

『论文笔记』Hybrid Task Cascade for Instance Segmentation
论文地址:Hybrid Task Cascade for Instance Segmentation
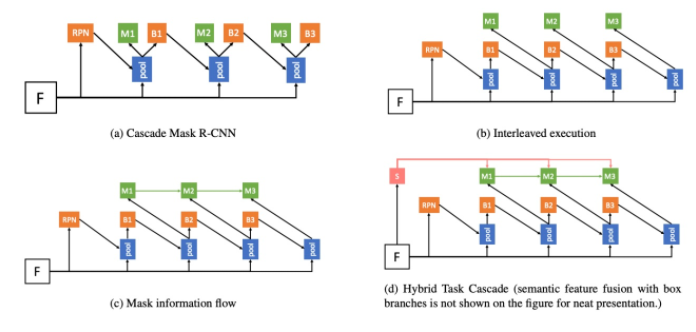
多任务多阶段的混合级联结构,并且融合了一个语义分割的分支来增强 spatial context。
关键思想:通过在每个阶段结合级联和多任务来改善信息流,并利用空间背景来进一步提高准确性。
Cascade是一种经典而强大的架构,可以提升各种任务的性能。但是,如何引入级联到实例分割仍然是一个悬而未决的问题。 Cascade R-CNN和Mask R-CNN的简单组合仅带来有限的增益。本文实际上就是针对Cascade RCNN的不足进行改进的工作:
(1)Cascade-Mask-RCNN方法:没有很好地利用前一时刻的mask结果。
(2)能够区分难被区分的背景
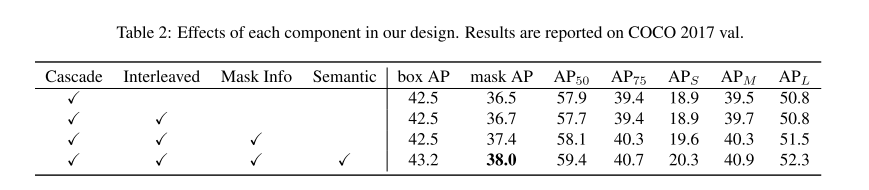
1、Interleaved Execution
Cascade R-CNN 虽然强行在每一个 stage 里面塞下了两个分支,但是这两个分支之间在训练过程中没有任何交互,它们是并行执行的。所以我们提出 Interleaved Execution,也即在每个 stage 里,先执行 box 分支,将回归过的框再交由 mask 分支来预测 mask,如上图(b)所示。这样既增加了每个 stage 内不同分支之间的交互,也消除了训练和测试流程的 gap。我们发现这种设计对 Mask R-CNN 和 Cascade Mask R-CNN 的 mask 分支都有一定提升。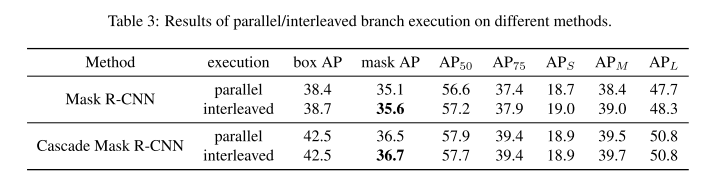
2、Mask Information Flow
这一步起到了很重要的作用,对一般 cascade 结构的设计和改进也具有借鉴意义。我们首先回顾原始 Cascade R-CNN 的结构,每个 stage 只有 box 分支。当前 stage 对下一 stage 产生影响的途径有两条:
- Bi+1 的输入特征是 Bi 预测出回归后的框通 RoI Align 获得的;
- Bi+1的回归目标是依赖 Bi 的框的预测的。这就是 box 分支的信息流,让下一个 stage 的特征和学习目标和当前 stage 有关。在 cascade 的结构中这种信息流是很重要的,让不同 stage 之间在逐渐调整而不是类似于一种 ensemble。
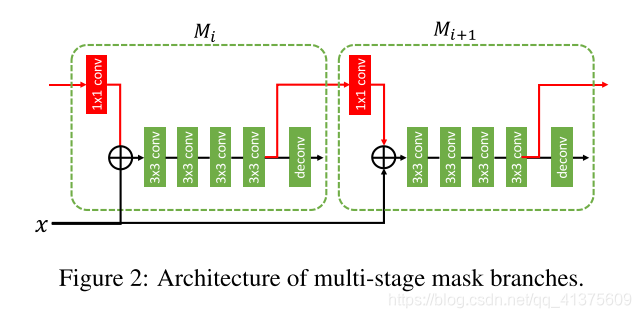
然而在 Cascade Mask R-CNN 中,不同 stage 之间的 mask 分支是没有任何直接的信息流的,Mi+1 只和当前 Bi 通过 RoI Align 有关联而与 Mi 没有任何联系。多个 stage 的 mask 分支更像用不同分布的数据进行训练然后在测试的时候进行 ensemble,而没有起到 stage 间逐渐调整和增强的作用。为了解决这一问题,我们在相邻的 stage 的 mask 分支之间增加一条连接,提供 mask 分支的信息流,让 Mi+1能知道 Mi 的特征。具体实现上如下图中红色部分所示,我们将 Mi 的特征经过一个 1x1 的卷积做 feature embedding,然后输入到 Mi+1,这样 Mi+1 既能得到 backbone 的特征,也能得到上一个 stage 的特征。
3、Semantic Feature Fusion
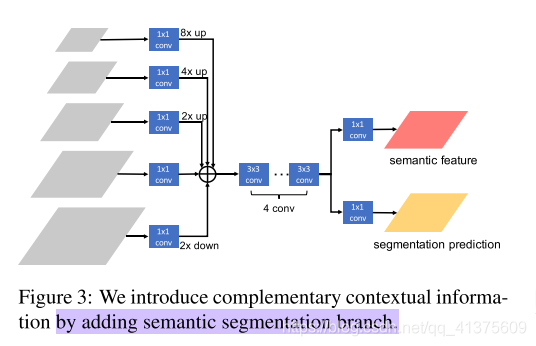
这一步是我们尝试将语义分割引入到实例分割框架中,以获得更好的 spatial context。因为语义分割需要对全图进行精细的像素级的分类,所以它的特征是具有很强的空间位置信息,同时对前景和背景有很强的辨别能力。通过将这个分支的语义信息再融合到 box 和 mask 分支中,这两个分支的性能可以得到较大提升。
在语义分割模块的具体设计上,为了最大限度和实例分割模型复用 backbone,减少额外参数,我们在原始的 FPN 的基础上增加了一个简单的全卷积网络用来做语义分割。首先将 FPN 的 5 个 level 的特征图 resize 到相同大小并相加,然后经过一系列卷积,再分别预测出语义分割结果和语义分割特征。这里我们使用 COCO-Stuff 的标注来监督语义分割分支的训练。红色的特征将和原来的 box 和 mask 分支进行融合(在下图中没有画出),融合的方法我们也是采用简单的相加。
实验效果比RCNN系列内网络都好,不过其实计算量增加也很可观:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号