

『论文笔记』BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
论文地址:https://arxiv.org/pdf/1810.04805.pdf
一、BERT网络结构
1、Transform
Bert的重要基础就是attention is all you need中的自注意力机制,快速回忆如下图:
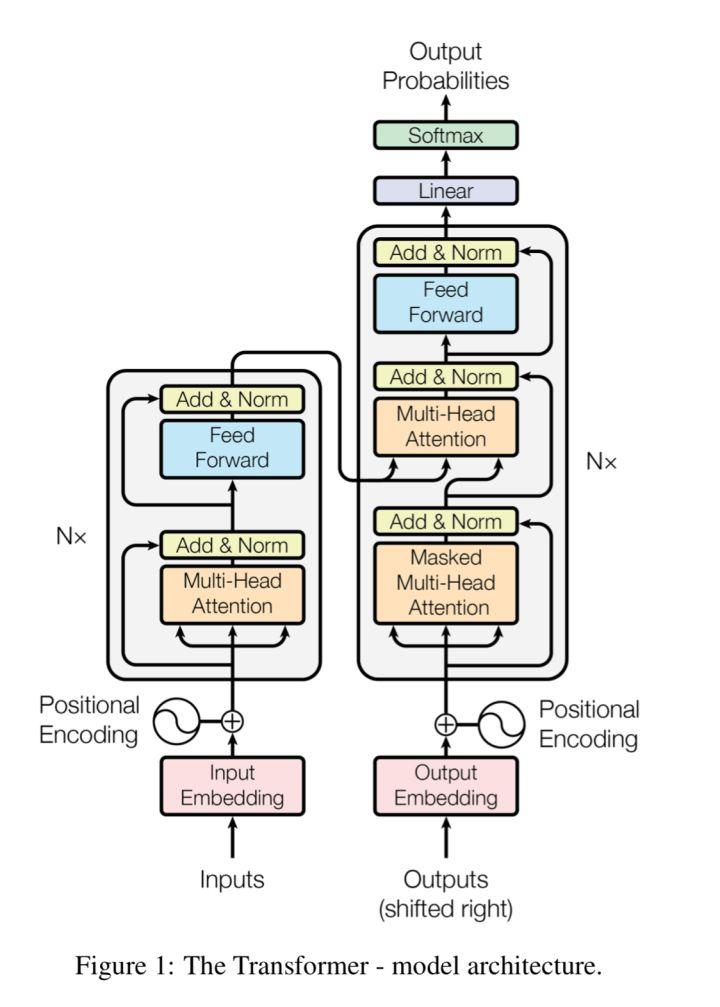
2、Bert
Bert的输入输出形式和RNN非常类似,N个字符输入对应N个输出。由于使用了transform作为特征提取器,相比其他方式有两个优点:可以兼顾前后文两个方向的信息;相比LSTM可以对更远的信息进行记忆。
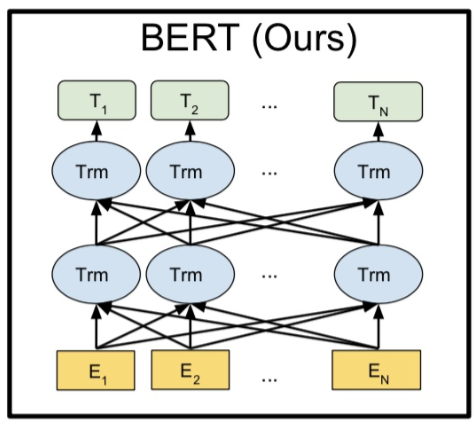
2、输入格式
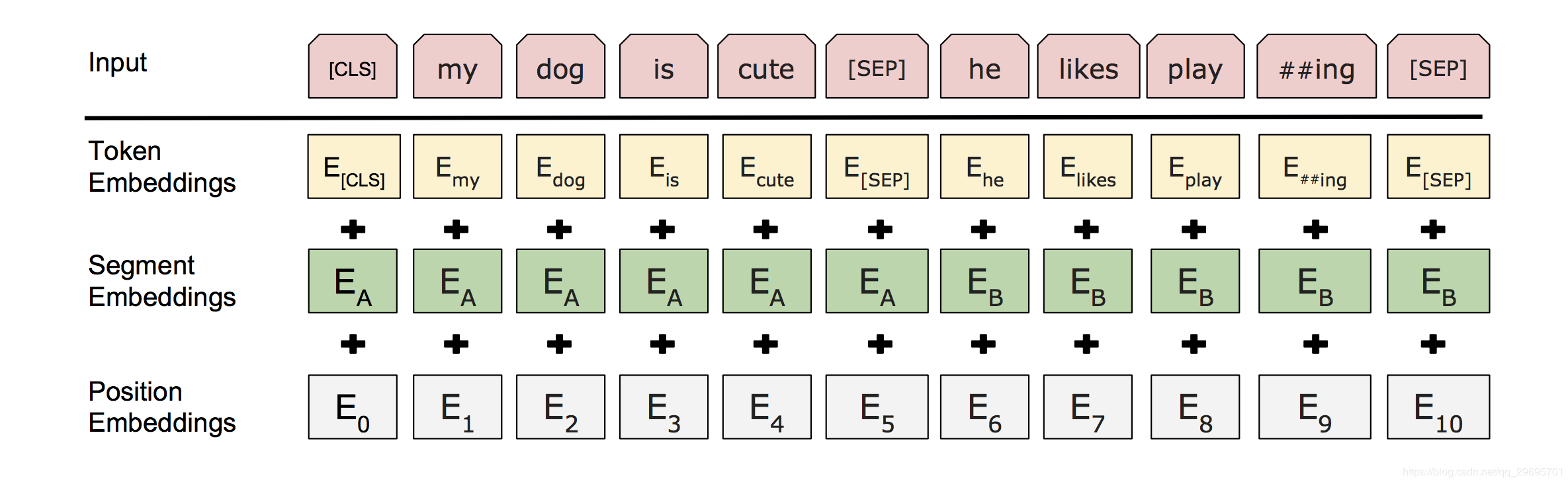
在整个工作中,“句子”可以是连续的任意跨度的文本,而不是实际语言意义上的句子。“序列”是指输入到 BERT 的标记序列,它可以是单个句子,也可以是两个句子组合在一起。实际输入包含三部分:句子的embedding,语义的embedding,位置的embedding。注意,这三者都是可训练的。
语义的embedding:输入表示能够在一个标记序列中清楚地表示单个文本句子或一对文本句子(例如,[Question, Answer])。
- 我们使用含 3 万个标记词语的 WordPiece 嵌入(Wu et al., 2016)。我们用 ## 表示拆分的单词片段。
- 我们使用学习到的位置嵌入,支持的序列长度最长可达 512 个标记。
- 每个序列的第一个标记始终是特殊分类嵌入([CLS])。该特殊标记对应的最终隐藏状态(即,Transformer 的输出)被用作分类任务中该序列的总表示。对于非分类任务,这个最终隐藏状态将被忽略。
- 句子对被打包在一起形成一个单独的序列。我们用两种方法区分这些句子。方法一,我们用一个特殊标记([SEP])将它们分开。方法二,我们给第一个句子的每个标记添加一个可训练的句子 A 嵌入,给第二个句子的每个标记添加一个可训练的句子 B 嵌入。
- 对于单句输入,我们只使用句子 A 嵌入。
二、预训练任务设计
基于Bert的NLP任务会先利用预训练来让网络学习到语言信息,然后再到具体的任务上进行微调,和通常的计算机视觉微调不同的是(当然只是“通常”),这里的预训练任务和微调任务差异很大。
1、遮蔽语言模型
In order to train a deep bidirectional representation, we simply mask some percentage of the input tokens at random, and then predict those masked tokens.
为了强化双向信息设置获取的任务:利用双向信息预测mask位置的词(完形填空)。
两个缺点:
第一个缺点是,预训练和微调之间造成了不匹配,因为 [MASK] 标记在微调期间从未出现过。为了缓和这种情况,我们并不总是用真的用 [MASK] 标记替换被选择的单词。而是,训练数据生成器随机选择 15% 的标记,例如,在my dog is hairy 这句话中,它选择 hairy。然后执行以下步骤:
- 数据生成不会总是用 [MASK] 替换被选择的单词,而是执行以下操作:
- 80% 的情况下:用 [MASK] 替换被选择的单词,例如,my dog is hairy → my dog is [MASK]
- 10% 的情况下:用一个随机单词替换被选择的单词,例如,my dog is hairy → my dog is apple
- 10% 的情况下:保持被选择的单词不变,例如,my dog is hairy → my dog is hairy。这样做的目的是使表示偏向于实际观察到的词。
Transformer 编码器不知道它将被要求预测哪些单词,或者哪些单词已经被随机单词替换,因此它被迫保持每个输入标记的分布的上下文表示。另外,因为随机替换只发生在 1.5% 的标记(即,15% 的 10%)这似乎不会损害模型的语言理解能力。
第二个缺点是,使用 Transformer 的每批次数据中只有 15% 的标记被预测,这意味着模型可能需要更多的预训练步骤来收敛,但是 Transformer 模型的实验效果远远超过了它增加的预训练模型的成本。
不过由于是无监督任务(或者是自监督?),没有标注成本使得这个预训练设计极为强大。
2、预测下一句
许多重要的下游任务,如问题回答(QA)和自然语言推理(NLI),都是建立在理解两个文本句子之间的关系的基础上的,而这并不是语言建模直接捕捉到的。为了训练一个理解句子关系的模型,这里预训练了一个下一句预测的二元分类任务,这个任务可以从任何单语语料库中简单地归纳出来。具体来说,在为每个训练前的例子选择句子 A 和 B 时,50% 的情况下 B 是真的在 A 后面的下一个句子,50% 的情况下是来自语料库的随机句子。比如说:
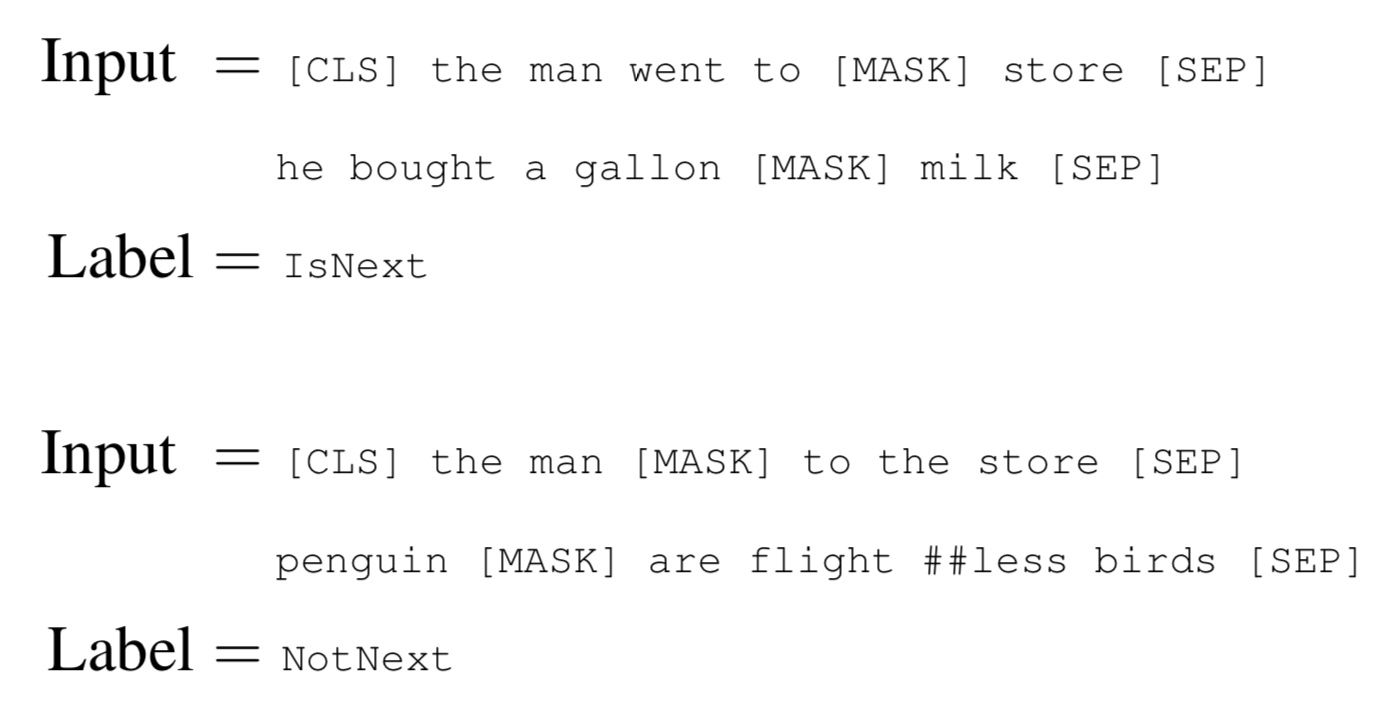
针对此任务的预训练对 QA 和 NLI 都非常有益。
3、微调
文章fine-tuning之前对模型的修改非常简单,例如针对sequence-level classification problem(例如情感分析),取第一个token的输出表示,喂给一个softmax层得到分类结果输出;对于token-level classification(例如NER),取所有token的最后层transformer输出,喂给softmax层做分类。
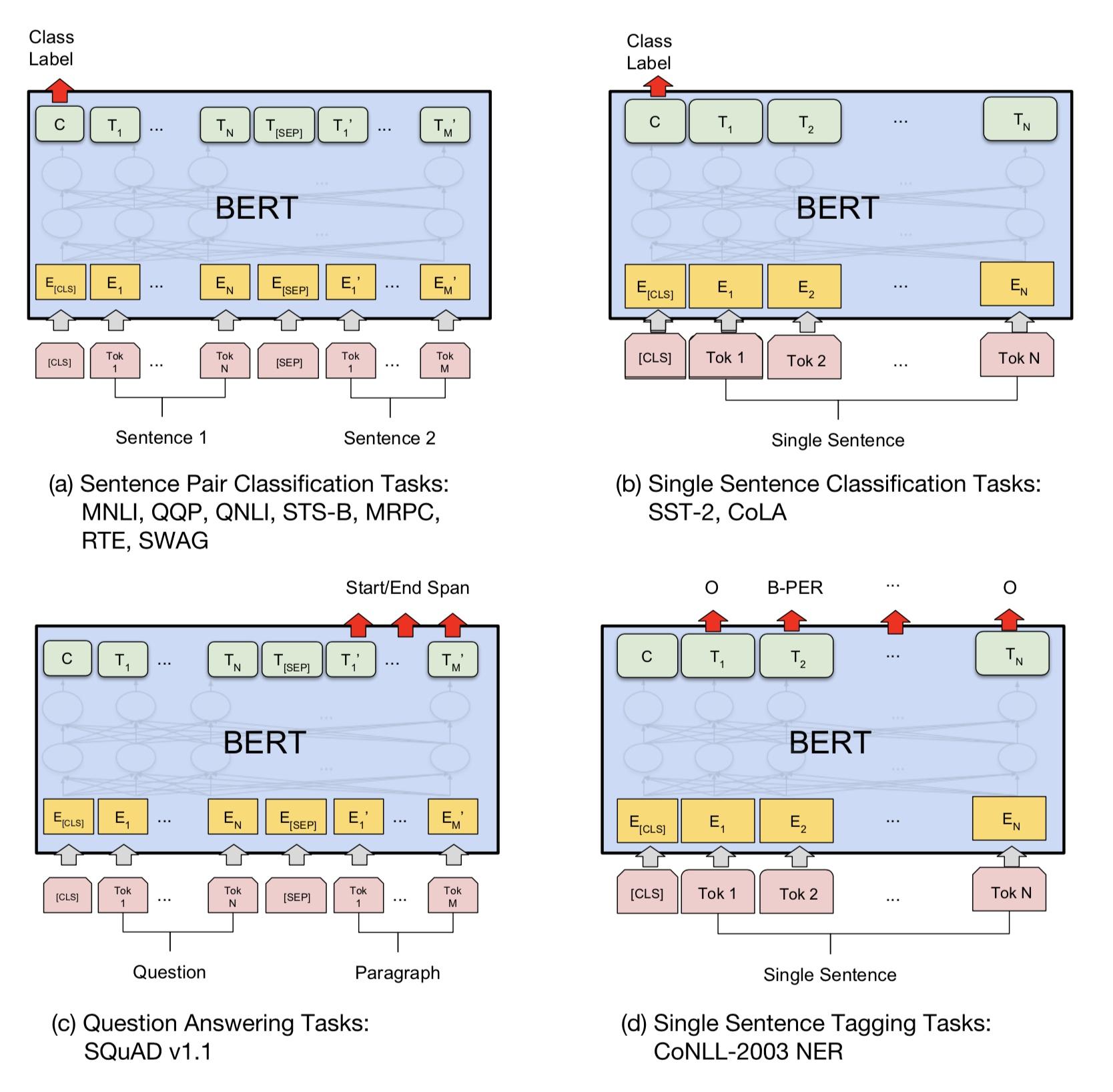
预训练任务1对应图d,任务2对应图a 。
三、实验分析
消融实验
Bert在11个NLP任务上取得了SOA的效果,我不了解相关任务,略去这部分。看消融实验,显然BERTBase的效果最好的:
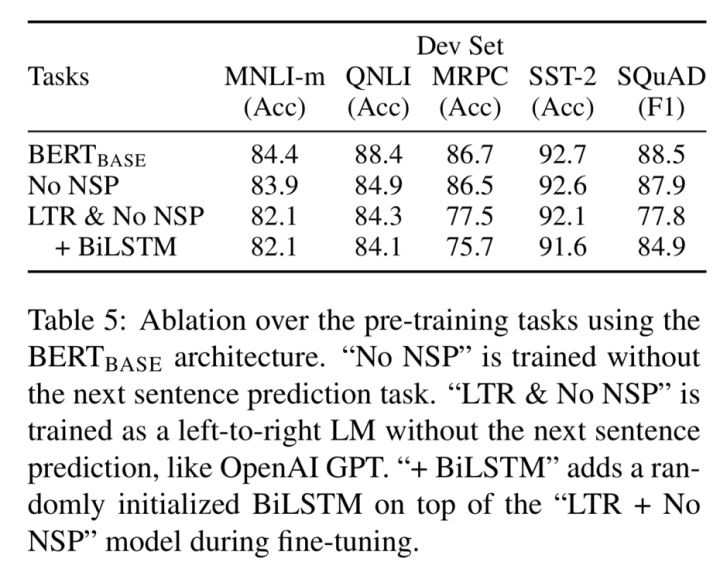
- No NSP:模型使用“遮蔽语言模型”(MLM)但是没有“预测下一句任务”(NSP)。
- LTR & No NSP:模型使用一个从左到右(LTR)的语言模型,而不是遮蔽语言模型。在这种情况下,预测每个输入词,不应用任何遮蔽。在微调中也应用了仅限左的约束,因为作者发现使用仅限左的上下文进行预训练和使用双向上下文进行微调结果更糟。此外,该模型未经预测下一句任务的预训练。这与OpenAI GPT有直接的可比性,但使用了更大的训练数据集、输入表示和微调方案。
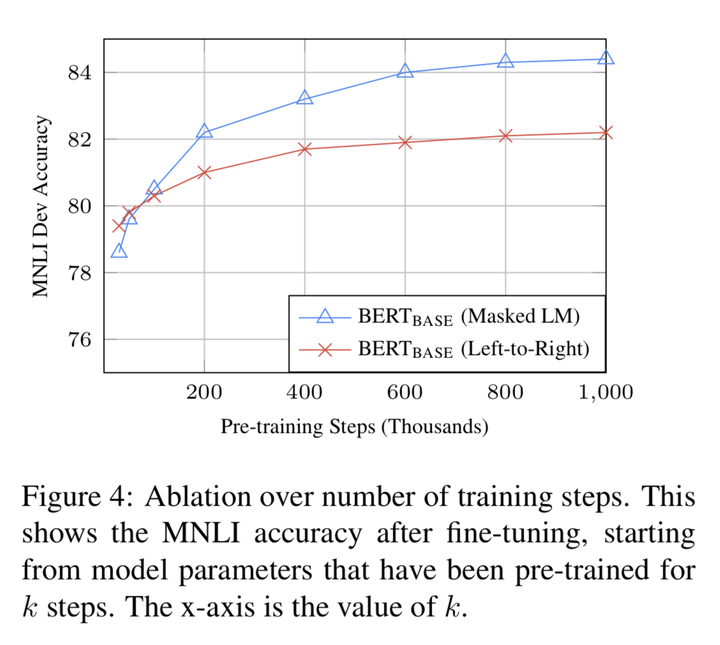
training steps的影响
这里主要讨论Masked LM和普通LM的训练时间问题,可以看到
- BERT的确需要训练很长steps
- MLM的确收敛比LTR慢,但是很早就效果好于LTR了
使用 BERT 基于特征的方法
这一节表示的是吧Bert作为单纯的特征提取器,用哪层的特征更好。
由于并非所有的NLP任务都可以很容易地用Transformer encoder结构来表示,因此还是需要一个task-specific model结构。同时如果需要fine-tuning的话,transformer encoder模型很大,需要重新训练的话,需要的计算资源比feature-based方法更多,因此如果可以直接用BERT的Transformer的结果的话,就很方面使用了。因此本文做了一个BERT + task-specific model的实验。表明这种方式也是可以有很好的效果的。

5. 总结
- BERT采用Masked LM + Next Sentence Prediction作为pre-training tasks, 完成了真正的Bidirectional LM
- BERT模型能够很容易地Fine-tune,并且效果很好,并且BERT as additional feature效果也很好
- 模型足够泛化,覆盖了足够多的NLP tasks

 浙公网安备 33010602011771号
浙公网安备 33010602011771号