

『计算机视觉』Region Proposal by Guided Anchoring
论文地址:Guided Anchoring
不得不佩服自媒体,直接找到了论文作者之一写了篇解析文章,这里给出链接,本文将引用一部分原作者的解析,减少我的打字量,也方便结合比照理解。
一、问题和思路
1、面临问题
常见的生成 anchor 的方式是滑窗(sliding window),也就是首先定义 k 个特定尺度(scale)和长宽比(aspect ratio)的 anchor,然后在全图上以一定的步长滑动。anchor 的尺度和长宽比需要预先定义,这是一个对性能影响比较大的超参,而且对于不同数据集和方法需要单独调整。如果尺度和长宽比设置不合适,可能会导致 recall 不够高:
一方面,大部分的 anchor 都分布在背景区域,对 proposal 或者检测不会有任何正面作用
另一方面,预先定义好的 anchor 形状不一定能满足极端大小或者长宽比悬殊的物体
而且 anchor 数目过多影响将网络性能和速度。所以我们期待的是稀疏,形状根据位置可变的 anchor。
2、anchor设计准则
本段引用作者自己的解释:
Alignment
由于每个 anchor 都是由 feature map 上的一个点表示,那么这个 anchor 最好是以这个点为中心,否则位置偏了的话,这个点的 feature 和这个 anchor 就不是非常好地对应起来,用该 feature 来预测 anchor 的分类和回归会有问题。我们设计了类似 cascade/iterative RPN 的实验来证明这一点,对 anchor 进行两次回归,第一次回归采用常规做法,即中心点和长宽都进行回归,这样第一次回归之后,anchor 中心点和 feature map 每一个像素的中心就不再完全对齐。我们发现这样的两次 regress 提升十分有限。所以我们在形状预测分支只对 w 和 h 做预测,而不回归中心点位置。
Consistency
这条准则是我们设计 feature adaption 的初衷,由于每个位置 anchor 形状不同而破坏了特征的一致性,我们需要通过 feature adaption 来进行修正。这条准则本质上是对于如何准确提取 anchor 特征的讨论。对于两阶段检测器的第二阶段,我们可以通过 RoI Pooling 或者 RoI Align 来精确地提取 RoI 的特征。但是对于 RPN 或者单阶段检测器的 anchor 来说,由于数量巨大,我们不可能通过这种 heavy 的方法来实现特征和框的精确 match,还是只能用特征图上一个点,也就是 512x1x1 的向量来表示。那么 Feature Adaption 起到了一个让特征和 anchor 对应更加精确的作用,这种设计在其他地方也有可以借鉴之处。
3、文章贡献
1、提出了一种新的 anchor 生成方法:Guided Anchoring,即通过图像特征来指导 anchor 的生成,通过预测 anchor 的位置和形状,来生成稀疏而且形状任意的 anchor
2、设计了 Feature Adaption 模块来修正特征图使之与 anchor 形状更加匹配
这篇 paper 的方法用在了 COCO Challenge 2018 检测任务的冠军方法中,在极高的 baseline 上涨了 1 个点。
二、Guided Anchoring
1、inference 网络
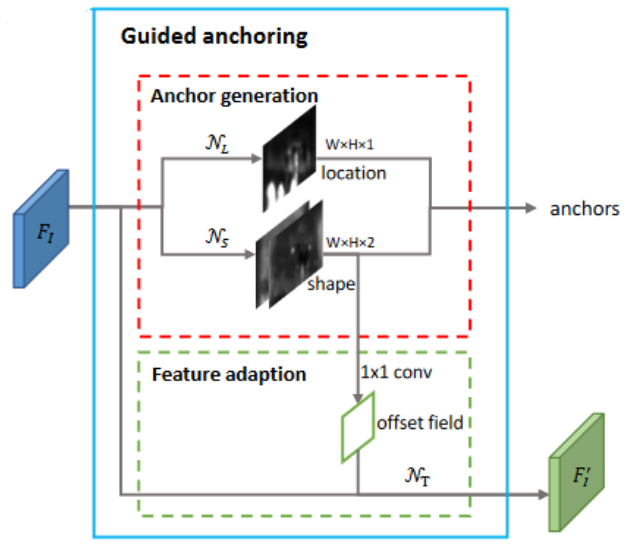
GA的逻辑图如上,网络分为3块:NL、NS、NT
NL 生成等大的单通道特征,表示每一个像素位置为一个 anchor 中心的概率(1*1卷积+sigmoid)
NS 生成等大的双通道特征,表示每一个 anchor 中心对应的 h、w 值(1*1卷积+转换运算)
NT 作者提出的 Feature adaption 模块,逻辑上属于 backbone 的特征提取,应用了可变形卷积,附加了 anchor 的信息,生成的 F' 将可以直接回归、分类对应的 anchor
NS 转换运算公式如下:
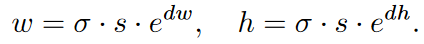
将 dw 和 dh 转换为 w 和 h,原文说可将 [-1,1] 放缩到 [0,1000],方便学习,所以推测在1*1后应该还有一个sigmoid层。
NT 的提出是因为自学习的 anchor 长宽并不会受特征层的感受野指导,所以问题就来了:同一层的特征感受野相同,但 anchor 差异巨大,每一个特征点使用同样大小的感受野代表不同大小的 anchor,这不合理,所以作者在 NS 后添加了1*1卷积输出 offset,设计了 NT 这个仅包含一层3*3可变形卷积的结构,使得输出特征的每个特征点代表一个 anchor 的特征信息。
2、损失函数和 label 设置
损失函数由四部分组成:
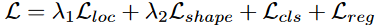
其后两项为传统的分类回归损失函数,前两项为anchor的定位、形状损失函数。
锚框定位损失函数 Lloc:
定位标签按照 NL 输出来看很容易发现仅需要一张 mask 图像即可,但是这样定位正样本比例会过低,且负样本中会有很多误导项(临近真实点的像素都作为负样本的话会有很强的干扰性),所以作者提出了几个概念:CR、IR、OR,原文解释如下(“x′g” 表示的是 x 上标为 ' 下标为 g,其他符号同理):
(1) The center region CR=R(x′g, y′g, σ1w′, σ1h′) defines the center area of the box. Pixels in CR are assigned aspositive samples.
(2) The ignore region IR=R(x′g, y′g ,σ2w′, σ2h′) \ CR is a larger (σ2> σ1) region excluding CR. Pixels in IR are marked as“ignore”and exluded during training.
(3) The outside region OR is the whole feature map excluding CR and IR. Pixels in OR are regarded as negative samples.
即 CR 区域(真实中心附近的矩形范围像素)的样本均视为正样本,CR 区域外围的环形区域 IR 不参与损失函数的贡献,防止混淆,再外面的像素 OR 才视为负样本。
对于应用 FPN 结构作者做出了进一步的规范:
- 有预测 gt 任务的层的相邻层,将把任务层的 CR+IR 区域对应的像素均视为本层的IR
结合上面的规则,示意图如下:

锚框形状损失函数 Lshape:
原文本部分涉及两个问题:损失函数的选择 & gt 的选择。
先看 gt 选择,由于我们的 anchor 没有预先的形状,所以我们不好判断 anchor 属于哪个 gt,作者的处理手段也很传统:预先定义9组宽高,将9组宽高和特定 gt 的 IOU 计算出来并保留最大的记为 vIOU,将其和不同 gt 的 vIOU 横向比较,选最大的 vIOU 对应的 gt 作为该 anchor 对应的 gt。
损失函数作者在连接文章中说的很明白了,
预测最佳的长和宽,这是一个回归问题。按照往常做法,当然是先算出 target,也就是该中心点的 anchor 最优的 w 和 h,然后用 L1/L2/Smooth L1 这类 loss 来监督。然而这玩意的 target 并不好计算,而且实现起来也会比较困难,所以我们直接使用 IoU 作为监督,来学习 w 和 h。既然我们算不出来最优的 w 和 h,而计算 IoU 又是可导的操作,那就让网络自己去优化使得 IoU 最大吧。后来改用了 bounded IoU Loss,但原理是一样的。
论文为: Improving object local-ization with fitness nms and bounded iou loss (2018)。
3、将 GA 结构应用到传统两步法网络
作者发现 proposal 质量提升很多,但是在 detector 上性能提升比较有限。在不同的检测模型上,使用 Guided Anchoring 可以提升 1 个点左右。明明有很好的 proposal,但是 mAP 却没有涨很多。作者对该问题的探索如下:
经过一番探究,我们发现了以下两点:1. 减少 proposal 数量,2. 增大训练时正样本的 IoU 阈值(这个更重要)。既然在 top300 里面已经有了很多高 IoU 的 proposal,那么何必用 1000 个框来训练和测试,既然 proposal 们都这么优秀,那么让 IoU 标准严格一些也未尝不可。
这个正确的打开方式基本是 Jiaqi 独立调出来的,让 performance 一下好看了很多。通过这两个改进,在 Faster R-CNN 上的涨点瞬间提升到了 2.7 个点(没有加任何 trick),其他方法上也有大幅提升。
其他实验部分较为琐碎建议浏览原文。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号