
『计算机视觉』物体检测之RefineDet系列
Two Stage 的精度优势
二阶段的分类:二步法的第一步在分类时,正负样本是极不平衡的,导致分类器训练比较困难,这也是一步法效果不如二步法的原因之一,也是focal loss的motivation。而第二步在分类时,由于第一步滤掉了绝大部分的负样本,送给第二步分类的proposal中,正负样本比例已经比较平衡了,所以第二步分类中不存在正负样本极度不平衡的问题。即二步法可以在很大程度上,缓和正负样本极度不平衡的分类问题
二阶段的回归:二步法中,第一步会先对初始候选框进行校正,然后把校正过的候选框送给第二步,作为第二步校正的初始候选框,再让第二步进一步校正
二阶段的特征:在二步法中,第一步和第二步法,除了共享的特征外,他们都有自己独有的特征,专注于自身的任务。具体来说,这两个步骤独有的特征,分别处理着不同难度的任务,如第一步中的特征,专注于处理二分类任务(区分前景和背景)和粗略的回归问题;第二步的特征,专注于处理多分类任务和精确的回归问题
特征校准:在二步法中,有一个很重要的RoIPooling扣特征的操作,它把候选区域对应的特征抠出来,达到了特征校准的目的,而一步法中,特征是对不齐的
一、RefineDet 论文介绍
发表于CVPR2018,题目是single-shot refinement neural network for object detection
附上一篇很好的论文解读博客:RefineDet算法笔记
1、网络介绍
网络框架如下,由于和SSD、FPN的思想一脉相承,很好理解所以我不多介绍了,直接贴作者的描述:

这个是RefineDet的检测框架。该框架由两个模块组成,即上面的Anchor Refinement Module(ARM)和下面的Object Detection Module(ODM),它俩是由Transfer Connection Block(TCB)连接。
• 在这个框架中,ARM模块专注于二分类任务,为后续ODM模块过滤掉大量简单的负样本;同时进行初级的边框校正,为后续的ODM模块提供更好的边框回归起点。ARM模块模拟的是二步法中第一个步骤,如Faster R-CNN的RPN。
•ODM模块把ARM优化过的anchor作为输入,专注于多分类任务和进一步的边框校正。它模拟的是二步法中的第二个步骤,如Faster R-CNN的Fast R-CNN。
• 其中ODM模块没有使用类似逐候选区域RoIPooling的耗时操作,而是直接通过TCB连接,转换ARM的特征,并融合高层的特征,以得到感受野丰富、细节充足、内容抽象的特征,用于进一步的分类和回归。因此RefineDet属于一步法,但是具备了二步法的二阶段分类、二阶段回归、二阶段特征这3个优势。
作者觉得two stage方法的第二步(逐区域检测)由于并行很多inference的原因,效率很低,所以对其进行了改进。作者认为他们是对one stage方法的改进,我倒是觉得这个更接近two stage的方法,对此作者也有解释(作者准备真充分……):
当时RefineDet提出来的时候,有不少人说,RefineDet不属于一步法,毕竟有两阶段的分类和回归。我们认为,二步法之所以精度比较高,是因为它有一个逐区域操作的第二步,这个操作非常有效果,但也比较耗时,而RefineDet在没有用逐区域操作的情况下,获得了同等的效果。因此我们认为,区分一步法和二步法的关键点:是否有逐区域的操作。
2、性能分析
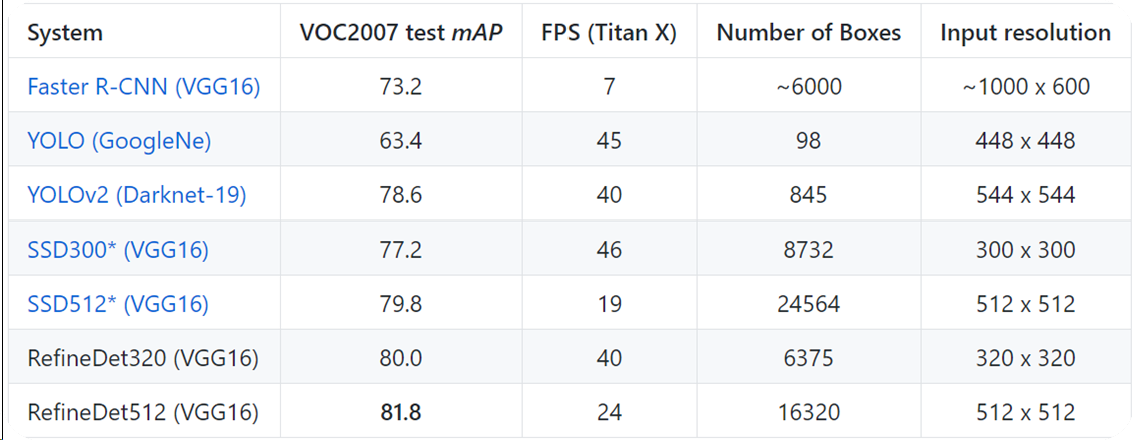
速度和SSD相近,精度明显更高,精度更高没什么好说的,速度在多了下面一部分卷积层和反卷积层的情况下没有明显下降,作者分析有两点原因,anchors较少以及基础网络后的附加网路层数少、特征选取层更少(4个,我记得SSD有5个),作者原文:
1. 我们使用了较少的anchor,如512尺度下,我们总共有1.6W个框,而SSD有2.5W个框。我们使用较少anchor也能达到高精度的原因是二阶段回归。虽然我们总共预设了4个尺度(32,,64,128,256,)和3个比例(0.5,1,2),但是经过第一阶段的回归后,预设的anchor被极大的丰富了,因此用于第二阶段回归的anchor,具备着丰富的尺度和比例。
2. 第2个原因是,由于显存限制,我们只在基础网络的基础上,新加了很少的卷积层,并只选了4个卷积层作为检测层。如果增加更多卷积层,并选择更多检测层,效果应该还能得到进一步提升。
3、经验总结
作者有关训练的总结:
Ø 首先输入尺度越大效果越好,在小目标多的任务上体现的更明显
Ø 小batch会影响BN层的稳定
有关BN层和batch的事我们多提一句,由于目标检测输入图尺寸大、网络尺寸大(如ResNet),一个batch可能就1、2张图片,所以目标检测任务的BN层基本都是不开放训练的,优化思路一般是:多卡BN同步(旷世论文MegDet),使用固定的BN参数(参考某个数据集得出),或者干脆是提出其他的BN层变种(如何凯明的group
normalization之类),作者提到何凯明论文Rethinking ImageNet Pre-training
有讲到或者应用这三种方法。
二、后续改进
a、SRN
这是作者后续的文章,继续上篇文章进行了探讨,不过这几篇文章是人脸检测领域
Shifeng
Zhang, Xiangyu Zhu, Zhen Lei, Hailin Shi, Xiaobo Wang, Stan Z. Li,
S3FD: Single Shot Scale-invariant Face Detector, ICCV, 2017
Shifeng
Zhang, Longyin Wen, Hailin Shi, Zhen Lei, Siwei Lyu, Stan Z. Li,
Single-Shot Scale-Aware Network for Real-Time Face Detection, IJCV
网络介绍
网络设置如下,注意P5、P6和P7之间的关系:C2->C5是backbone,P5->P2是反向backbone,而C6、C7、P6、P7都是在backbone后面额外添加的3*3卷积层。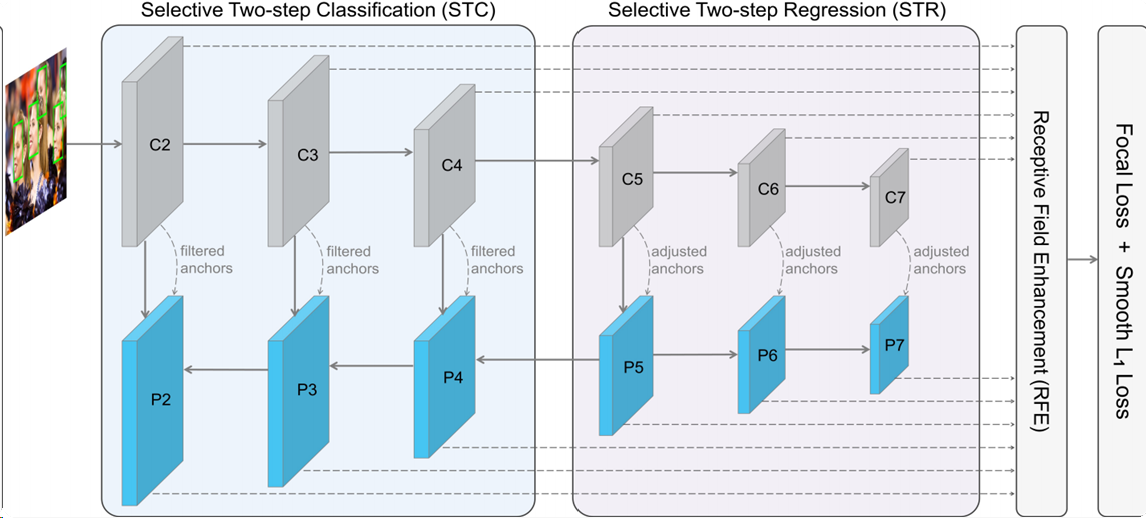
按照作者的说法,他将第二阶段的分类、回归操作进行了解耦:
a. Conduct the two-step classification only on the lower pyramid levels (P2, P3, P4)
b. Perform the two-step regression only on the higher pyramid levels (P5, P6, P7)
原因如下:如果实际去计算一下,可以发现anchors选取的过程中,浅层的占比要远大于深层的占比(空间分辨率大),这导致大量的负样本集中在浅层,所以对其进行预分类是必要的;而深层感受野本身很大,分类相比之下很容易,没必要进行两次分类。
这篇论文是人脸分类的文章,其具体流程原文说的也不甚详细,我的理解是C2->C4仅进行分类,C5->C7仅进行回归,而P系列则完全和RefineDet一致。
b、AlignDet
之前提到了one stage相较于two stage的四个劣势,refine解决了前三个,最后的特征校准遗留了下来,这里作者把它补上了(又成了一篇文章233),由于原理很简单没什么好说的,贴张图自己理解一下吧: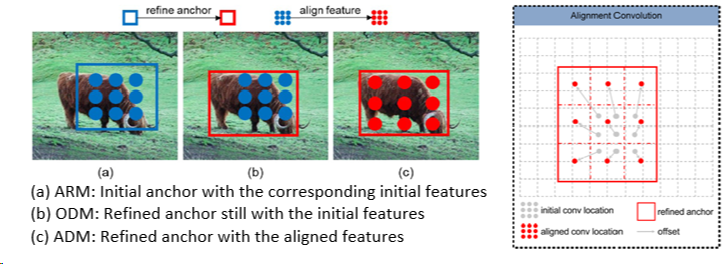
三、讨论
更快的速度
更高的准确率
a. 小物体检测:人脸检测的主要难题就是小物体检测
b. 遮挡问题: 行人检测的主要问题就是遮挡去除
多任务
例如检测+分割(最终目标:实例分割、全景分割)
视频目标检测
利用视频的连续性:精度提升
利用视频的冗余性:速度提升

 浙公网安备 33010602011771号
浙公网安备 33010602011771号