MySQL - 由一次Left Join查询缓慢引出的Explain和Join算法详解
由一次Left Join查询缓慢引出的Explain和Join算法详解
前些日子在生产环境中,项目经理偶然发现有一条SQL执行的非常缓慢,达到了不杀死这个语句就难以平民愤的程度。于是委派我来解决这个问题。
后来追踪到这是一个600万条数据的表和一个700万条数据的表 left join 的故事,sql语句类似于下面这种:
SELECT a.column_1, a.column_2, a.column_3, c.column_1 FROM table_1 a LEFT JOIN table_2 c ON a.column_1 = c.column_1 WHERE a.column_1 = 'value1'
AND a.column_2 BETWEEN STR_TO_DATE('2021-05-27 23:55:59','%Y-%m-%d %H:%i:%s')
AND STR_TO_DATE('2021-05-27 23:59:59','%Y-%m-%d %H:%i:%s') ORDER BY a.column_2 DESC LIMIT 0 , 1
我眉头一皱,发现事情并不简单,就想到了先用 explain 来看看这个语句到底干了什么。

Explain详解
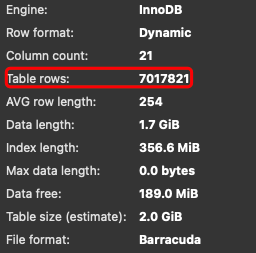
执行explain之后的结果如下所示:

id
- id越大执行优先级越高
- id相同则从上往下执行
- id为NULL最后执行
select_type
- SIMPLE:简单SELECT,不使用UNION或子查询等。
- PRIMARY:子查询中最外层查询,查询中若包含任何复杂的子部分,最外层的select被标记为PRIMARY。
- UNION:UNION中的第二个或后面的SELECT语句。
- DEPENDENT UNION:在包含UNION或者UNION ALL的大查询中,如果各个小查询都依赖于外层查询的话,那除了最左边的那个小查询之外,其余的小查询的select_type的值就是DEPENDENT UNION。
- UNION RESULT:MySQL选择使用临时表来完成UNION查询的去重工作,针对该临时表的查询的select_type就是UNION RESULT。
- SUBQUERY:如果包含子查询的查询语句不能够转为对应的semi-join的形式,并且该子查询是不相关子查询,并且查询优化器决定采用将该子查询物化的方案来执行该子查询时,该子查询的第一个SELECT关键字代表的那个查询的select_type就是SUBQUERY。
- DEPENDENT SUBQUERY:如果包含子查询的查询语句不能够转为对应的semi-join的形式,并且该子查询是相关子查询,则该子查询的第一个SELECT关键字代表的那个查询的select_type就是DEPENDENT SUBQUERY。
- DERIVED:对于采用物化的方式执行的包含派生表的查询,该派生表对应的子查询的
select_type就是DERIVED。 - UNCACHEABLE SUBQUERY:一个子查询的结果不能被缓存,必须重新评估外链接的第一行。
- MATERIALIZED:当查询优化器在执行包含子查询的语句时,选择将子查询物化之后与外层查询进行连接查询时,该子查询对应的select_type属性就是MATERIALIZED。
semi-join:
是指当一张表在另一张表找到匹配的记录之后,半连接(semi-jion)返回第一张表中的记录。
与条件连接相反,即使在右节点中找到几条匹配的记录,左节点 的表也只会返回一条记录。
另外,右节点的表一条记录也不会返回。半连接通常使用IN 或 EXISTS 作为连接条件。
物化: 这个将子查询结果集中的记录保存到临时表的过程称之为物化(Materialize)。
那个存储子查询结果集的临时表称之为物化表。
正因为物化表中的记录都建立了索引(基于内存的物化表有哈希索引,基于磁盘的有B+树索引),通过索引执行IN语句判断某个操作数在不在子查询结果集中变得非常快,从而提升了子查询语句的性能。
table
当前查询的表名。表名有可能是原名,有可能是别名,要看SQL语句的具体情况。
partitions
如果数据表建立分区了的话,这里会显示查询用到的分区。
type
表示MySQL在表中找到所需行的方式,又称“访问类型”。
常用的类型有: ALL、index、range、 ref、eq_ref、const、system、NULL(从左到右,性能从差到好)
- ALL:Full Table Scan, MySQL将遍历全表以找到匹配的行。
- index:Full Index Scan,index与ALL区别为index类型只遍历索引树。
- range:只检索给定范围的行,使用一个索引来选择行。
- ref:表示上述表的连接匹配条件,即哪些列或常量被用于查找索引列上的值。
- eq_ref:类似ref,区别就在使用的索引是唯一索引,对于每个索引键值,表中只有一条记录匹配,简单来说,就是多表连接中使用 primary key 或者 unique key 作为关联条件。
- const、system:当MySQL对查询某部分进行优化,并转换为一个常量时,使用这些类型访问。如将主键置于where列表中,MySQL就能将该查询转换为一个常量,system是const类型的特例,当查询的表只有一行的情况下,使用system。
- NULL:MySQL在优化过程中分解语句,执行时甚至不用访问表或索引,例如从一个索引列里选取最小值可以通过单独索引查找完成。
possible_keys
可能用到的索引。查询涉及到的字段上若存在索引,则列出,但查询的时候不一定会使用(如果没有任何索引显示 null)。
key
实际用到的索引。
key_len
表示索引中使用的字节数。
该列计算查询中使用的索引的长度,在不损失精度的情况下,长度越短越好。如果键是NULL,则长度为NULL。
该字段显示为索引字段的最大可能长度,并非实际使用长度。
ref
在key列显示的索引中,表在查找时所用到的列或常量,常见的有:const(常量),字段名(例:t1.id)。
rows
预计要读取并检索的行数,注意这个不是结果集里的行数,并且这个数字是一个估值,不是准确值。
filtered
返回结果的行占需要读到的行(rows列的值)的百分比。
Extra
- Using where:SQL使用了where条件过滤数据。(可以优化)
- Using index:SQL所需要返回的列都在一棵索引树上,不需要访问其对应的实际行记录。(性能较好)
- Using index condition:SQL用到了索引,但不是所有需要返回的列都在索引上,还需要访问实际的行记录。(性能次于Using index)
- Using filesort:要得到想要的结果集,需要将所有的数据进行排序。在一个没有建立索引的列上进行了order by,就会触发filesort,常见的优化方案是,在order by的列上添加索引,避免每次查询都全量排序。(性能很差,需要优化)
- Using temporary:需要建立临时表来得到想要的结果集。group by和order by同时存在,且作用于不同的字段时,就会建立临时表,以便计算出最终的结果集。(性能较差,需要优化)
- Using join buffer (Block Nested Loop):需要进行嵌套循环计算。两个关联表join,关联字段均未建立索引,就会出现这种情况。常见的优化方案是,在关联字段上添加索引,避免每次嵌套循环计算。(性能较差,需要优化)
Join算法详解
摘自 https://blog.csdn.net/u010841296/article/details/89790399
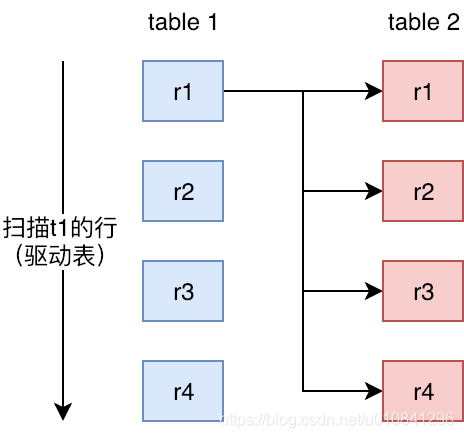
Mysql利用Nested-Loop Join 的算法思想去优化join,Nested-Loop Join翻译成中文则是“嵌套循环连接”。
举个例子:
select * from t1 inner join t2 on t1.id=t2.tid
(1)t1称为外层表,也可称为驱动表。
(2)t2称为内层表,也可称为被驱动表。
伪代码表示如下:
List<Row> result = new ArrayList<>(); for(Row r1 in List<Row> t1){ for(Row r2 in List<Row> t2){ if(r1.id = r2.tid){ result.add(r1.join(r2)); } } }
在Mysql的实现中,Nested-Loop Join有3种实现的算法:
- Simple Nested-Loop Join:SNLJ,简单嵌套循环连接
- Index Nested-Loop Join:INLJ,索引嵌套循环连接
- Block Nested-Loop Join:BNLJ,缓存块嵌套循环连接
在选择Join算法时,会有优先级,理论上会优先判断能否使用INLJ、BNLJ:
Index Nested-LoopJoin > Block Nested-Loop Join > Simple Nested-Loop Join
Simple Nested-Loop
简单嵌套循环连接实际上就是简单粗暴的嵌套循环,如果table1有1万条数据,table2有1万条数据,那么数据比较的次数=1万 * 1万 =1亿次(笛卡尔集),这种查询效率会非常慢。
所以Mysql继续优化,衍生出Index Nested-LoopJoin、Block Nested-Loop Join两种NLJ算法。在执行join查询时mysql会根据情况选择两种之一进行join查询。
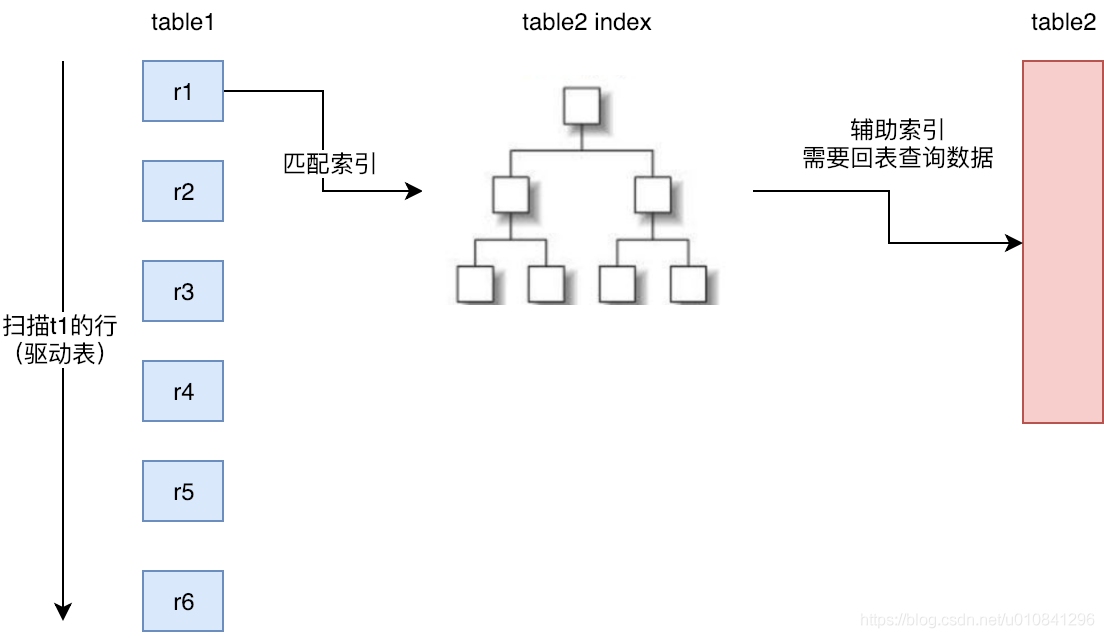
Index Nested-LoopJoin(减少内层表数据的匹配次数)
索引嵌套循环连接是基于索引进行连接的算法。索引是基于内层表的,通过外层表匹配条件直接与内层表索引进行匹配,避免和内层表的每条记录进行比较, 从而利用索引的查询减少了对内层表的匹配次数,优势极大的提升了 join的性能:
原来的匹配次数 = 外层表行数 * 内层表行数
优化后的匹配次数 = 外层表的行数 * 内层表索引的高度
只有内层表join的列有索引时,才能用到Index Nested-LoopJoin进行连接。
由于用到索引,如果索引是辅助索引而且返回的数据还包括内层表的其他数据,则会回内层表查询数据,多了一些IO操作。
Block Nested-Loop Join(减少内层表数据的循环次数)
缓存块嵌套循环连接通过一次性缓存多条数据,把参与查询的列缓存到Join Buffer 里,然后拿join buffer里的数据批量与内层表的数据进行匹配,从而减少了内层循环的次数(遍历一次内层表就可以批量匹配一次Join Buffer里面的外层表数据)。
当不使用Index Nested-Loop Join的时候,默认使用Block Nested-Loop Join。
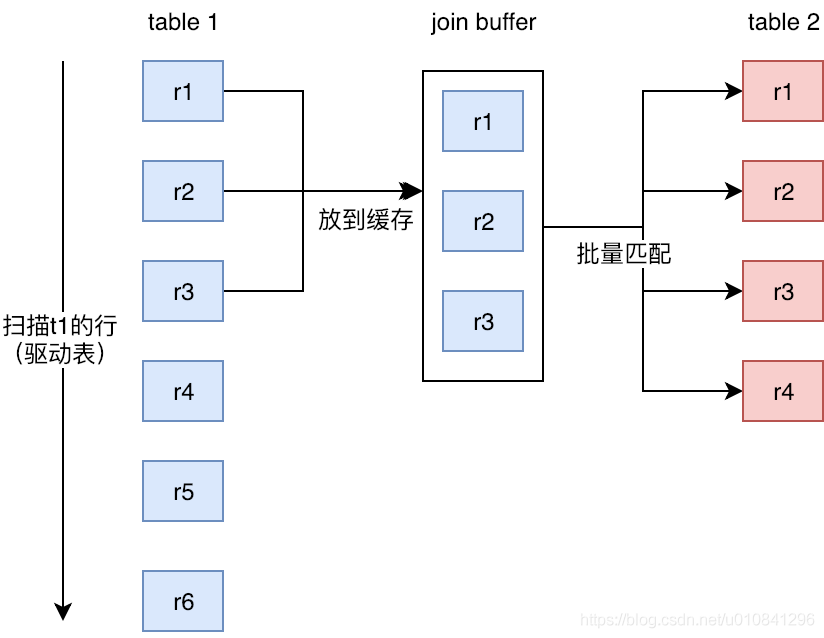
什么是Join Buffer?
- Join Buffer会缓存所有参与查询的列而不是只有Join的列。
- 可以通过调整join_buffer_size缓存大小
- join_buffer_size的默认值是256K,join_buffer_size的最大值在MySQL 5.1.22版本前是4G,而之后的版本才能在64位操作系统下申请大于4G的Join Buffer空间。
- 使用Block Nested-Loop Join算法需要开启优化器管理配置的optimizer_switch的设置block_nested_loop为on,默认为开启。
如何优化Join速度
用小结果集驱动大结果集,减少外层循环的数据量,从而减少内层循环次数:如果小结果集和大结果集连接的列都是索引列,mysql在内连接时也会选择用小结果集驱动大结果集,因为索引查询的成本是比较固定的,这时候外层的循环越少,join的速度便越快。
为匹配的条件增加索引:争取使用INLJ,减少内层表的循环次数.
增大join buffer size的大小:当使用BNLJ时,一次缓存的数据越多,那么内层表循环的次数就越少.
减少不必要的字段查询:
- 当用到BNLJ时,字段越少,join buffer 所缓存的数据就越多,内层表的循环次数就越少;
- 当用到INLJ时,如果可以不回表查询,即利用到覆盖索引,则可能可以提示速度。(未经验证,只是一个推论)
最终解决方案
有一说一,由于业务关系,我这次问题的解决方案是不用join。但我在实践中发现,用join代替left join也可以使速度变快,如果我以后研究出了个所以然,会在这里继续更新的。

