zookeeper一点通
概述
Zookeeper(很多时候也简称ZK)是Hadoop项目的正式子项目,是一个针对大型分布式系统的可靠协调系统,其功能包括:配置维护、名字服务、分布式同步、组服务等,光放用于各种场景下的分布式协调,比如kafka中使用ZK存储一些元数据、偏移量等。
安装
安装流程
笔者使用的是mac电脑,以下所有的安装步骤均是在mac电脑上的安装步骤,请知悉:
1. 下载地址:https://zookeeper.apache.org/releases.html#download
2. 解压缩,笔者下载的版本是3.8.0,解压缩目录如下:
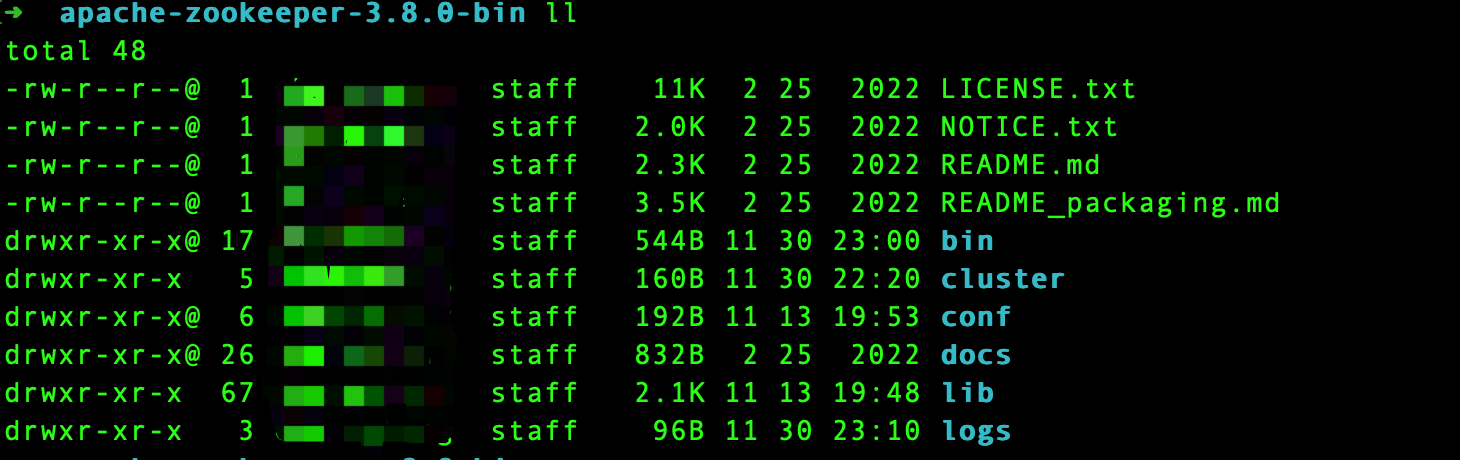
说明:
- bin目录下是一些脚本文件,比如服务启动脚本,后续流程会使用到
- conf目录下存放了一些配置文件
- lib目录下包含了一些需要使用的jar包
- docs目录顾名思义是和文档相关的目录
- logs目录下存放的则是一些日志文件
- cluster目录是笔者自己创建,用来在本地搭建伪集群模式的根目录
3. 现在,我们启动三台机器来搭建一个ZK集群,为了测试,将三个ZK节点都安装到本地机器上,也就是所谓的伪集群模式,根目录为cluster
4. 在cluster目录下创建三个目录zoo001、zoo002、zoo003,然后在这三个目录下创建data、log目录,再然后在data目录下创建myid文件,文件内容分别是1、2、3,目录结构如下:
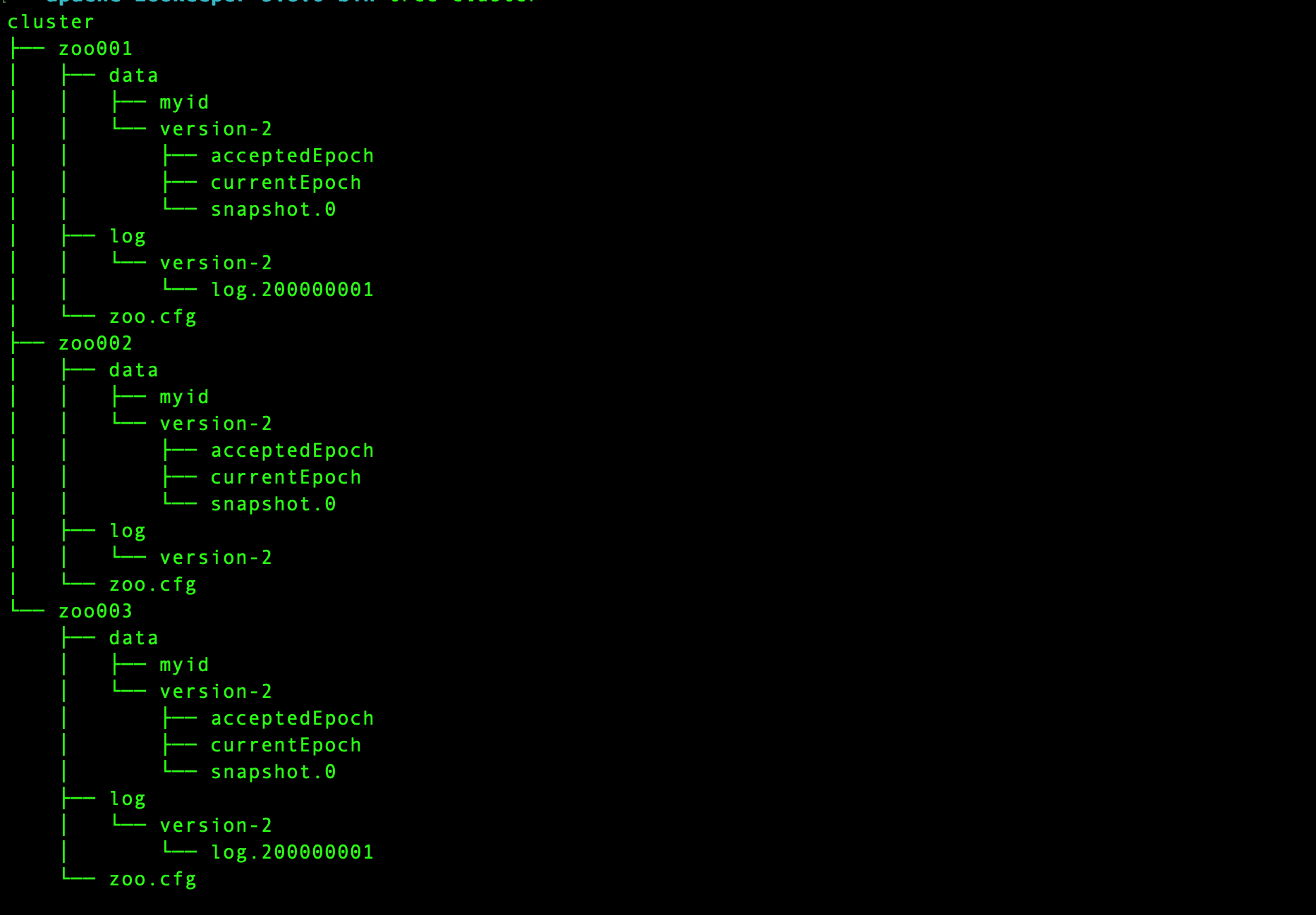
具体操作流程说明:
- 分别创建zoo001、zoo002、zoo003目录,作为伪集群模式三个ZK节点的根目录
- 在zoo001、zoo002、zoo003目录下分别创建data、log目录,分别作为数据目录和日志目录,稍后配置文件中需要配置目录地址
- 在data目录下创建myid文件,用以记录节点id
- conf目录下有个zoo_sample.cfg文件,这是安装包里给出的配置文件的样本,将该配置文件复制一份到zoo001、zoo002、zoo003目录下,并重命名为zoo.cfg
注意:version-2目录并非读者创建,而是伪集群模式启动后自动生成的目录,可以暂时不用关注
5. 修改zoo.cfg配置文件内容
🛠:zoo001/zoo.cfg配置文件内容
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/YOUR-PATH/apache-zookeeper-3.8.0-bin/cluster/zoo001/data
dataLogDir=/YOUR-PATH/apache-zookeeper-3.8.0-bin/cluster/zoo001/log
# the port at which the clients will connect
clientPort=2181
server.1=127.0.0.1:2991:3991
server.2=127.0.0.1:2992:3992
server.3=127.0.0.1:2993:3993🛠:zoo002/zoo.cfg配置文件内容
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/YOUR-PATH/apache-zookeeper-3.8.0-bin/cluster/zoo002/data
dataLogDir=/YOUR-PATH/apache-zookeeper-3.8.0-bin/cluster/zoo002/log
# the port at which the clients will connect
clientPort=2182
server.1=127.0.0.1:2991:3991
server.2=127.0.0.1:2992:3992
server.3=127.0.0.1:2993:3993🛠:zoo003/zoo.cfg配置文件内容
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/YOUR-PATH/apache-zookeeper-3.8.0-bin/cluster/zoo003/data
dataLogDir=/YOUR-PATH/apache-zookeeper-3.8.0-bin/cluster/zoo003/log
# the port at which the clients will connect
clientPort=2183
server.1=127.0.0.1:2991:3991
server.2=127.0.0.1:2992:3992
server.3=127.0.0.1:2993:39936. 启动集群
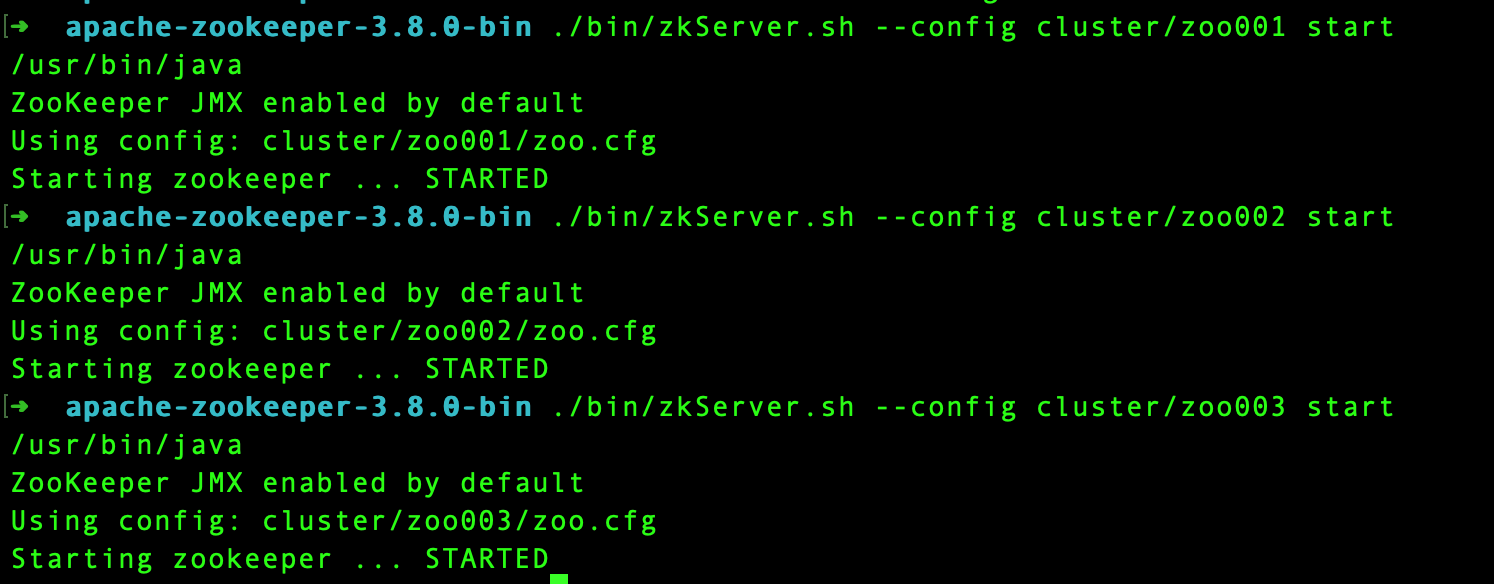
流程说明:
- 切换到apache-zookeeper-3.8.0-bin目录下,该目录下bin目录存放的是启动脚本,cluster为伪集群根目录
- 控制台运行命令:./bin/zkServer.sh --config cluster/zoo001 start ,启动第一个ZK节点,其他两个节点启动同理
- 启动成功后则如上图所示
注意:
zkServer.sh脚本启动时--config参数为zoo.cfg所在的父目录,不要写cluster/zoo001/zoo.cfg
7. 查看启动情况

运行命令:./bin/zkServer.sh --config cluster/zoo001 status,若正常启动则显示如上。
8. 启动Zookeeper客户端连接到集群:./bin/zkCli.sh -server 127.0.0.1:2181
配置详解上述安装过程中大家会注意到以下几个问题:
- 集群节点数量我们设置为3个
- 在data目录下创建了myid文件
- zoo001、zoo002、zoo003目录下都新建了一个zoo.cfg文件
- zoo.cfg文件中定义了以下内容
- tickTime
- initLimit
- syncLimit
- dataDir
- dataLogDir
- clientPort
- server.id
为什么一定要做这些操作呢,下面对这些问题一一解答:
- Zookeeper集群节点数量必须是奇数,为什么要有这样一个要求呢?ZK集群是由一系列ZK节点组成,构成ensemble,这些节点会选举出来一个主节点Leader,Zookeeper集群节点均是peer节点,数据一致性采用的是ZAB协议,需要要Leader节点发起提案进行数据同步。而Leader节点是由群首选举出来的,群首选举需要投票的可用节点数量超过总结点数量一半,如果节点总数为偶数,则可能会出现脑裂问题。上述安装示例中我们的zk集群节点数量设定为3个,这也是最少得节点数量,否则只有一个节点的话也无法构成一个集群。
- 集群安装的过程中,我们在data目录下创建了一个myid文件,该文件的作用是记录zk节点的编号,文件类型是一个文本文件,文件内容为数字,数字范围是1~255,默认情况下需要放在data目录下。
- zoo.cfg配置文件中可以定义节点的一些属性,比如端口号、pid、数据地址、日志地址等,可以看到,示例中所有的配置操作我们都是在这个配置文件中修改的。
- zoo.cfg属性介绍:
- dataDir:数据目录选项,存放znode节点数据。myid文件处于此目录下。
- dataLogDir:目录日志选项,存放日志文件。如果没有配置该参数,默认为dataDir选项值。
- clientPort:客户端连接ZK节点的端口号。
- tickTime:配置单元时间。单元时间是ZK的时间计算单元,其他时间选项的时间间隔都是使用tickTime的倍数表示的。
- initLimit:节点初始化时间。该参数用于Follower启动并完成与Leader进行数据同步的时间。
- syncLimit:心跳最大延迟时间。该参数用于配置Follower和Leader之间心跳检测的最大延迟时间,Leader通过心跳检测来确定Follower是否存活。
- server.id:配置集群节点信息,格式为:server.id=host:port:port。其中,这里的id指的是ZK节点编号,也就是myid文件中的数值;host位ZK节点的host地址;第一个port用以节点之间的通信,比如Follower节点作为客户端与Leader通信,Follower则使用该端口号与Leader的clientPort来进行通信;第二个port用以选举主节点。需要注意的是,zoo.cfg配置文件中需要配置全部的节点信息,而不是仅仅配置自己的节点信息,如示例中每个配置文件中三个节点的信息我们都做了配置。
原理
存储模型
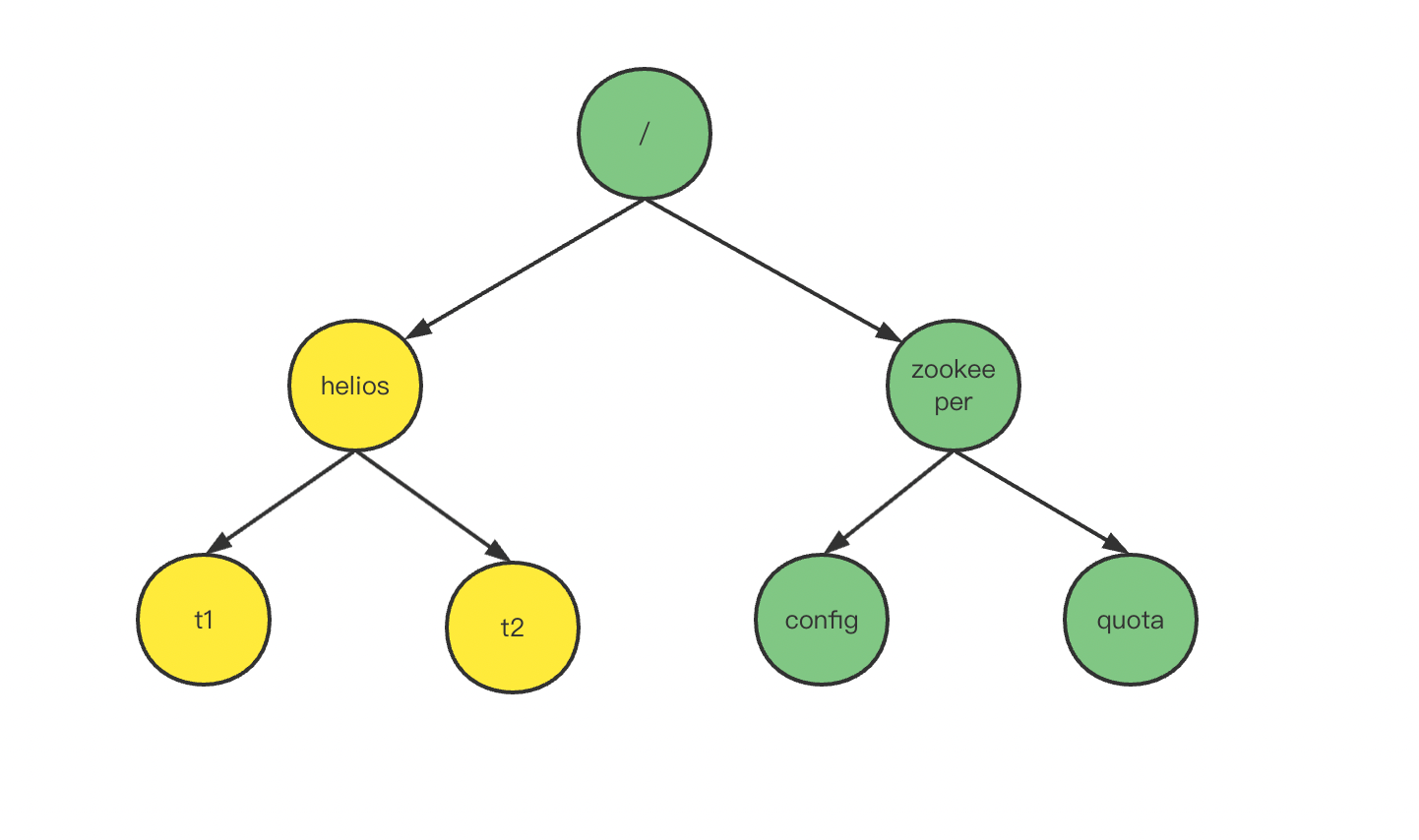
Zookeeper的存储模型比较简单,和Linux的文件系统类似,是一棵树形接口,每个节点称之为ZNode节点。如上图示,Zookeeper提供了一个znode根节点,称之为“/”,除了根节点外,其他的节点都有一个父节点。上述图示中绿色节点都是Zookeeper提供的,黄色节点为笔者测试创建的节点。每个znode节点都用以“/”分隔的完整路径来唯一标识,比如t1节点的路径为:/helios/t1。通过znode树,Zookeeper提供了一个多层级的属性命名空间。
Zookeeper将数据存储在znode节点中,每个znode都可以保存二进制有效负载数据(payload),需要牢记的是,znode的数据写入是overwrite模式,每次写入都会全量覆盖。为了提高读取效率,znode树保存在内存中,所以,尽量不要往znode节点中写入较大的数据。不过,为了保证数据不丢失,Zookeeper支持将数据同步到磁盘,后续会进行讲解。
除了payload数据外,znode还包含了很多属性,下面我们以/helios节点为例来讲解一下znode节点都包含什么。
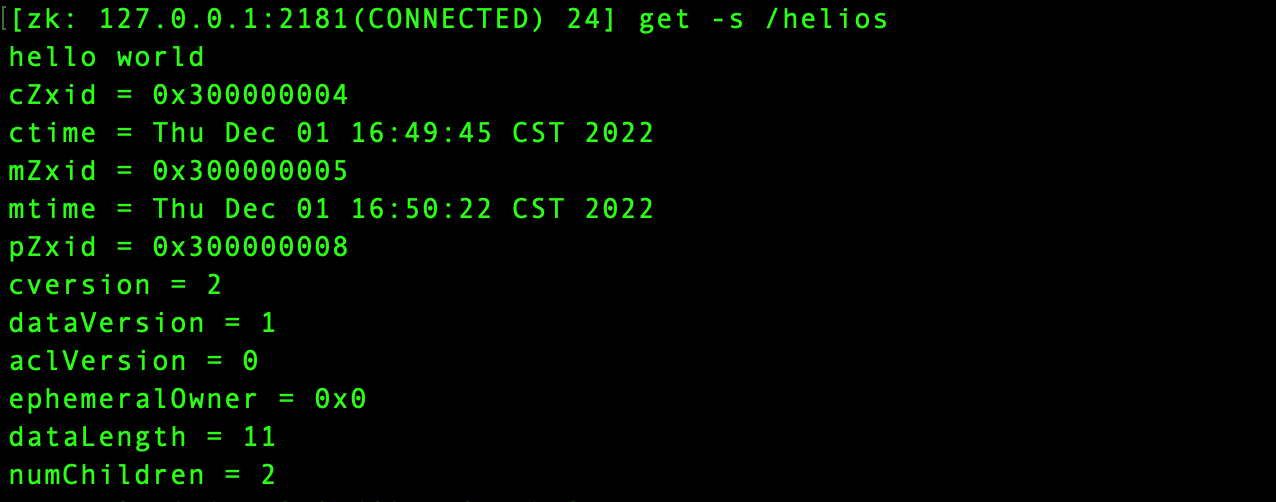
使用zkCli客户端创建了如同图示的三个znode节点,分别是/helios、/helios/t1、/helios/t2。其中,向/helios节点写入”hello world“,使用get命令获取该节点内容如上,可以看到,znode节点包含了一下内容:
- payload:znode节点存储的负载数据,格式为二进制字节数组,如上payload数据为”hello world“
- cZxid:znode节点创建时的事务ID(事务ID以时间戳+计数器的格式构成)
- ctime:znode节点创建时的时间戳
- mZxid:znode节点修改时的事务ID,该事务ID只和znode节点payload负载数据有关,删减子节点并不会影响mZxid
- mtime:znode节点最近一次更新的时间戳,该属性也只和payload有关
- pZxid:znode节点子节点最大cZxid,比如图示中的pZxid和/helios/t2节点的cZxid一致
- cversion:子节点版本号,每次变更子节点操作时+1,比如:helios节点下新建了t1、t2两个节点,故而cversion=2
- dataVersion:数据版本号,每次编辑内容时+1,比如:helios节点创建后直接使用set命令设置内容为”hello world“,故而dataVersion=1
- aclVersion:节点ACL权限修改版本号,这里并没有修改znode节点ACL访问权限,故而aclVersion=0
- numChildren:孩子节点数量,这里创建了t1、t2两个孩子节点,故而numChildren=2
Zookeeper节点有4种类型:
- PERSISTENT:持久化节点
- PERSISTENT_SSEQUENTIAL:持久化顺序节点
- PHEMERAL:临时节点
- PHEMERAL_SEQUENTIAL:临时顺序节点
所谓持久化节点,指的是节点创建后一直存在,直到客户端执行删除操作。而临时节点的生命周期则和客户端有关,群首会管理和客户端的会话,如果客户端断开连接,则该客户端创建的临时节点也会被删除。需要注意的是,临时节点不能创建子节点。顺序节点指的是每个父节点会为它的第一级子节点维护一份顺序编号,记录节点创建的先后顺序,设置的节点名称为前缀,后续示例中会介绍这种节点类型,顺序节点在一些场景下也被用来生成分布式ID。
群首选举
集群组织结构
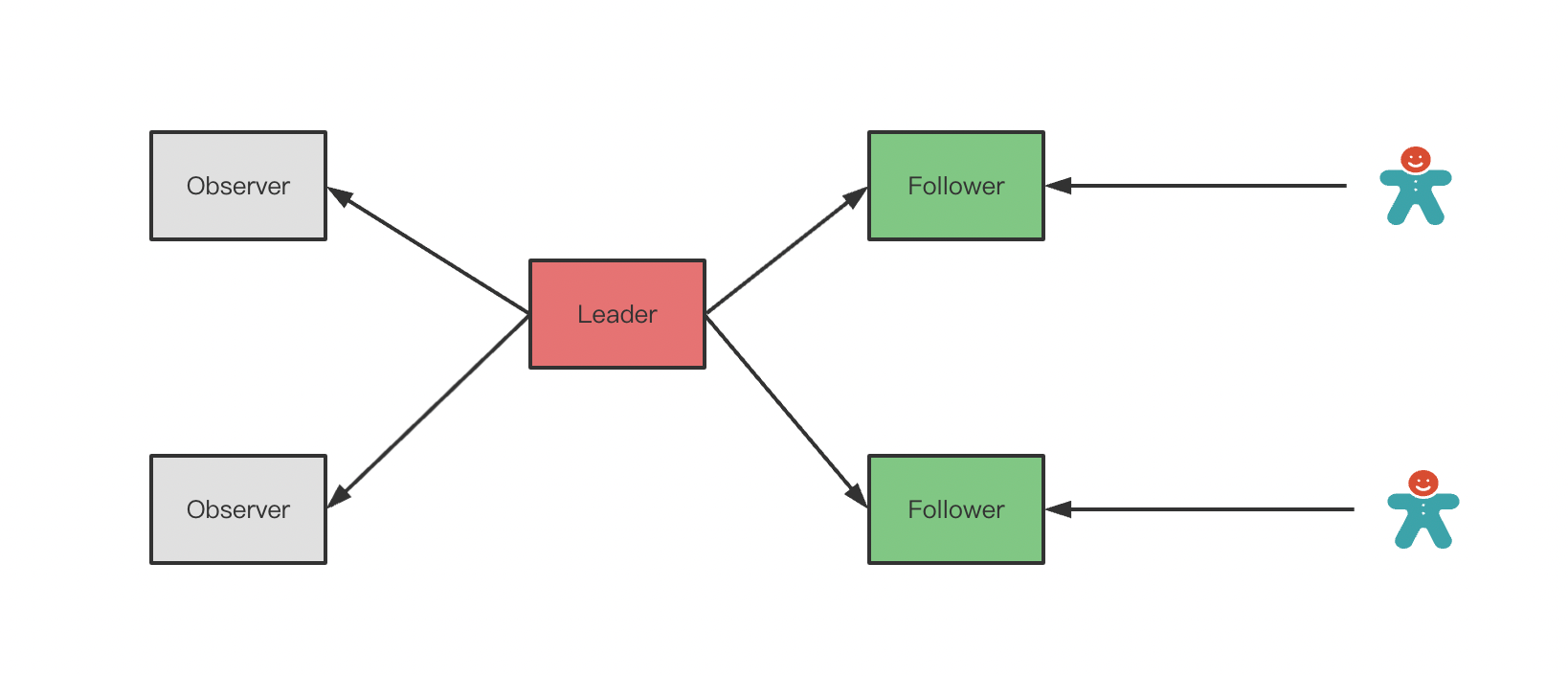
Zookeeper集群由一系列的ZK节点组成ensamble,zk节点之间为peer-to-peer模式,每个zk节点都保存了一棵完整的znode树(部分Follower和Observer节点可能会有延迟,但保证最终一致性)。Zookeeper采用最终一致性方案,由上图所示,Zookeeper集群的zk节点包括三种角色:群首(Leader)、追随者(Follower)、观察者(Observer)。那么,为什么要设置这三种角色呢,这还要从数据一致性说起。Zookeeper采用了类似于Paxos的最终一致性方案,所有 节点都可以读取数据,但是数据的写入则需要一个群首来负责。当打算更新数据时,ZK服务器节点接收到客户端的setData请求,此时,如果该ZK节点不是Leader,它会将请求转发到Leader节点,由Leader负责生成事务,然后采用ZAB原子广播协议将数据写入到其他ZK节点,这时,集群中所有ZK节点才都会保存有一份znode树的快照数据。
群首选举过程
群首是集群中的所有服务器推选出来的一个服务器,并会一直被集群所认可,由群首来服务对客户端发起的Zookeeper状态变更请求进行排序,比如create、delete和setData操作。群首负责将变更请求转换为一个事务,并将这些事务发送给追随者和观察者,以确保集群中各节点数据一致性。那么,群首是如何被推选出来的呢?
群首需要集群中达到法定仲裁数量的服务器节点认可(注意:这里不包括观察者),比如集群中有5个ZK节点,则需要满足3个以上的ZK节点同时推选出一个ZK节点为群首。每个服务器启动后都会 进入Looking状态,此时该服务器会尝试选举一个新的群首或者查找已经存在的群首,如果群首已经存在,则其他服务器会通知该服务器哪个服务器是群首,此时,新启动的这台服务器就会去Leader建立连接,开始同步数据。如果集群中还不存在Leader,则这些服务器之间会进行通信来进行群首选举。选举出来的服务器会进入LEADING状态,其他服务器会进入FOLLOWING状态。
那么,这些服务器之间怎么样进行通信来选举出来群首Leader呢?
这里,需要关注两个重要的属性:voteSid和voteZxid。选举过程如下:
- 服务器进入LOOKING状态后,会向其他服务器发起一个投票信息,该信息中包含voteSid(自己服务器id)和voteZxid(当前服务器最大事务ID),并用mySid和myZxid来保存这两个属性值
- 服务器接收到来自其他服务器的投票信息,如果(voteZxid>myZxid)或者(voteZxid=myZxid && voteSid>mySid),则修改自己的投票信息(myZxid=voteZxid,mySid=voteSid),继续发起投票
- 如果不满足上述条件,则保留自己的投票信息
- 当服务器接收到的法定仲裁数量的投票信息都一样时,如果voteSid是自己服务器ID,则开始行驶群首的角色,否则则成为一个Follower开始追随群首
有几点需要注意:
- 如果voteZxid=myZxid,会选举最新的服务器成为群首,这是为了简化群首崩溃后重新仲裁的流程。
- 步骤2如果要修改自己的投票信息,并不是接收到投票信息修改后立即发起投票,而是要等待一段时间,这时可能会有其他服务器的投票信息到达,这样做是为了防止频繁发起错误的投票
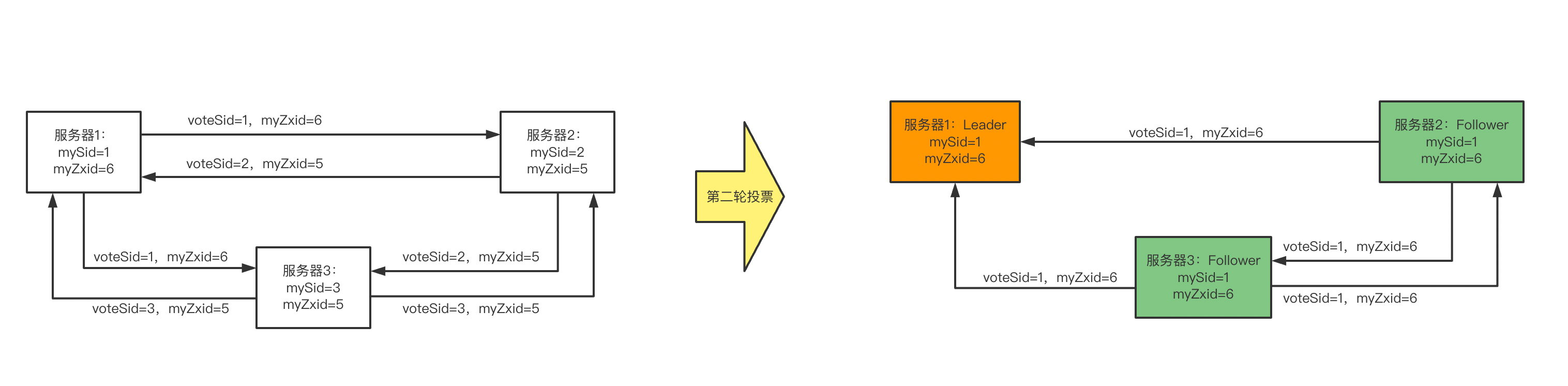
我们以3台服务器构成的简单Zookeeper集群为例,来说明一下群首选举过程:
- 三台服务器sid分别为1、2、3,其中服务器1事务zxid=1,其他两台服务器事务zxid=5
- 三台服务器刚开始都处于LOOKING状态,彼此间发起投票信息
- 服务器1接收到来自服务器2、服务器3的投票信息,比较voteZxid发现自己的myZxid较大,保留自己的投票信息
- 服务器2、服务器3接收到来自服务器1的投票信息,将修改自己的投票信息(mySid=1、myZxid=6),然后服务器2、服务器3重新发起投票信息
- 服务器1接收到来自服务器2、服务器3的投票信息,加上自己给自己的投票,发现3个节点都选举自己,于是自己成为Leader
- 服务器2、服务器3也收到投票信息,发现仲裁数量为3,于是确认服务器1为Leader,自己成为追随者
- 服务器2、服务器3开始和Leader同步数据,至此,群首选举结束
ZAB
请求、事务和标识符
Zookeeper服务器节点会在本地处理只读请求(getData和getChildren),然而对于状态更新的请求(crete、Delete和setData),则需要转交给Leader来处理。Leader此时会将更新请求转换成一个事务,然后采用两阶段提交方案将事务同步到其他节点,那么,什么是事务呢?
请求表示客户端发起的操作,而事务则表征状态的更新。比如,客户端发起incr(i)请求,语义为在当前的数据基础上加1,如果当前的值为2,则事务代表的操作是set(3)。Leader会将请求操作结合本地znode快照数据转化为事务,可以看到,事务具有幂等性,表示的是将znode一种状态直接转化成另外一种状态,数据是直接进行覆盖操作,事务操作以原子性方式被执行。
前面我们了解到,znode中有很多zxid相关的属性,比如cZxid、mZxid和Zxid,这些zxid有时间戳(epoch)+计数器(counter)组成。每次群首选举后,时间戳就会进行更新,此后,每一次状态更新操作计数器都会累加,这个zxid就是Leader将请求转换成成事务后生成的事务标识符,通过zxid来标识事务,可以确保事务在群首中按照指定顺序来执行。
原子广播协议
Zookeeper采用两阶段提交来确保事务的提交,在Zookeeper中称之为ZAB协议(原子广播协议),流程如下:
- Leader向所有追随者发送一个PROPOSAL天消息p
- 当追随者接收到天消息p后,会进行检查,判断是否可以提交该事务,如果可以,则将该事务写入事务日志中 ,然后发送ack给Leader表示自己接受提案
- Leader收到仲裁数量的确认消息后(包括Leader自己),Leader通知追随者进行commit操作
- Follower接收到commit消息后,更新内存的znode快照数据,然后将znode数据同步到磁盘
注意事项:
- commit阶段,追随者会阻塞后续的读取请求,直到commit完成,所以尽量不要频繁的更新Zookeeper数据
- 事务日志和快照写入到磁盘过程中,Zookeeper采用了组提交和补白以加速持久化的性能。组提交是指在一次磁盘写入时追加多个事物,减少了磁盘寻址开销。另外,数据写入到磁盘过程中,才做系统会进行页缓存,此时可能并没有真正的写入到磁盘,如果需要,可以flush缓存数据到磁盘介质。补白是指在文件中预分配磁盘存储块,事务日志文件写入时,如果datanode节点不足,这时需要申请datanode,之后还需要更新inode节点元数据,为了减少开销,采用补白在文件中预分配存储块。
- Zookeeper存储模式为znode树,Zookeeper将znode快照持久化到磁盘,Follower和Leader进行数据同步时,如果数据落后不是太多采用DIFF模式进行同步,Follower会在本地replay事务,如果落后太多则直接将SNAPSHOT快照同步过来。
会话
Zookeeper的会话跟踪由群首来负责,群首和追随者通过心跳机制通信,追随者会将客户端连接的会话信息转发给群首。为了管理会话过期,群首采用过期队列来维护会话。群首根据会话过期时间分为不同的bucket,每个bucket对应某一时间范围内过期的会话。为了确定会话是否过期,群首交由一个线程来找出要过期的bucket,该线程会取出bucket中过期的session让其过期。采用bucket的方式是为了减少会话过期的系统开销,对会话过期进行较粗粒度的管理。
会话过期公式:
(expirationTime / expirationInterval + 1) * expirationIntervalbucket的分割以expirationInterval为单位,比如expirationTime=10,expirationInterval,表示分割单位为2个tick,会话10个tick后过期,该会话被分配到12这个bucket。如果此时客户端和服务端通信,expirationTime值会增加,这时会移动到其他的bucket中。
监视点
Zookeeper提供了watch监视功能,znode状态变更后服务器会通知客户端数据发生了变更。这一操作是一次性的,如果需要一直监视则需要客户端重新设置监视点。Zookeeper提供了一个监视点管理器来管理监视点,每个服务器都有一个监视点管理器,监视点信息都保存在内存中,服务器并不会持久化到磁盘,此外,客户端也会维护一份监视点数据,如果客户端和服务器断开连接又重连之后,客户端监视点数据会被同步到服务端。
实践
客户端
zkCli客户端命令
用zkCli.sh连接上ZK服务后,可以使用zkCli提供的命令来操作ZK节点,可以使用help命令来查看所有命令的用法,常用的命令如下:
- create:创建ZNode节点
- ls:查看路径下的所有节点
- get:获得节点的值
- set:修改节点的值
- delete:删除节点
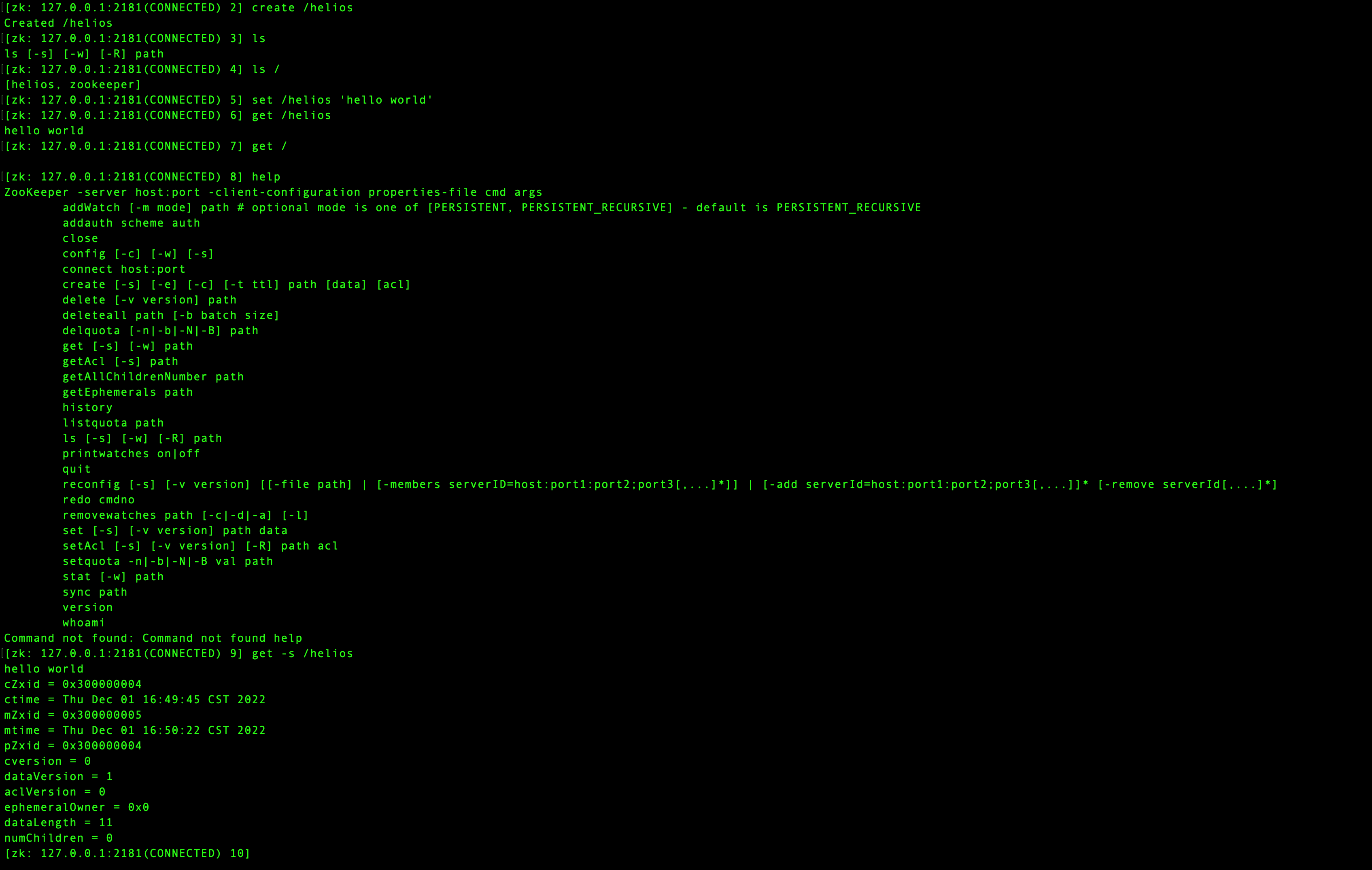
流程说明:
- 使用create命令在根节点下创建了一个helios节点
- 使用ls命令查看根节点
- 使用set命令修改/helios节点值
- 使用get命令查看/helios节点值,注意:这里值显示了节点的内容,节点相关的属性并没有显示出来
- 使用help命令查看各种命令的用法,可以看到get命令有一个参数[-s]
- 使用get -s查看znode节点详细信息,可以看到除了我们set的“hello world”内容外还显示出了cZxid、ctime等信息
Curator开源客户端
Curator是Netflix公司开源的一套Zookeeper客户端框架,解决了一些非常底层的细节开发工作,比如连接、重连、反复注册Watcher的问题等。除此之外,Curator还为Zookeeper客户端框架提供了一些比较普遍的、开箱即用的、分布式开发应用的解决方案,例如Recipe、共享锁服务、Master选举机制和分布式计算器等,避免开发者重复造轮子的无效开发工作。
鼎鼎大名的Patrixck Hunt对Curator给予了高度评价:”Guava is to Java that Curator to Zookeeper“。
环境准备
Curator官网地址:https://curator.apache.org/
使用Curator之前,需要导入Curator包,包含以下几个:
- curator-framework:对Zookeeper底层API的一些封装
- curator-client:提供了一些客户端操作,比如重试策略等
- curator-recipes:封装了一些高级特性,比如:Cache事务监听、选举、分布式锁、分布式计数器、分布式Barrier等
笔者导入的Curator包如下:
<!-- https://mvnrepository.com/artifact/org.apache.curator/curator-recipes -->
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-recipes</artifactId>
<version>5.4.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.curator/curator-framework -->
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-framework</artifactId>
<version>5.4.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.curator/curator-client -->
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-client</artifactId>
<version>5.4.0</version>
</dependency>示例
查看代码
import org.apache.curator.framework.CuratorFramework;
import org.apache.curator.framework.CuratorFrameworkFactory;
import org.apache.curator.retry.RetryOneTime;
import org.apache.zookeeper.CreateMode;
import org.apache.zookeeper.data.Stat;
import java.nio.charset.StandardCharsets;
import java.util.List;
import java.util.Objects;
public class SimpleCuratorDemo {
public static void main(String[] args) throws Exception {
String ZK_ADDRESS = "127.0.0.1:2181";
// 创建Curator客户端实例
CuratorFramework client = CuratorFrameworkFactory.builder()
.connectString(ZK_ADDRESS)
.retryPolicy(new RetryOneTime(1000))
.build();
// 启动客户端实例,连接到zookeeper服务器
client.start();
String ROOT_PATH = "/helios/test";
String PERSISTENT_PATH = ROOT_PATH + "/persistent";
String PERSISTENT_SEQUENTIAL_PATH = ROOT_PATH + "/persistent-sequential/test-";
// 检查节点是否已经存在
Stat existingStat = client.checkExists().forPath(PERSISTENT_PATH);
// 创建持久化节点并设置内容
if (Objects.isNull(existingStat)) {
client.create()
.creatingParentsIfNeeded()
.withMode(CreateMode.PERSISTENT)
.forPath(PERSISTENT_PATH, "This is a persistent znode!".getBytes(StandardCharsets.UTF_8));
}
// 创建持久化顺序节点
if (Objects.isNull(client.checkExists().forPath(PERSISTENT_SEQUENTIAL_PATH))) {
client.create()
.creatingParentsIfNeeded()
.withMode(CreateMode.PERSISTENT_SEQUENTIAL)
.forPath(PERSISTENT_SEQUENTIAL_PATH);
}
// 更新节点内容(注意:这里采用了异步更新,如果要使用同步更新可以注释掉inBackground)
client.setData()
.inBackground((curatorFramework, curatorEvent) -> System.out.println(curatorEvent.getResultCode()))
.forPath(PERSISTENT_PATH,"Hello world!".getBytes(StandardCharsets.UTF_8));
// 读取znode节点数据
byte[] data = client.getData().forPath(PERSISTENT_PATH);
System.out.println(new String(data));
// 获取子节点列表
List<String> children = client.getChildren().forPath(ROOT_PATH + "/persistent-sequential");
System.out.println(children);
String deletedPath = PERSISTENT_SEQUENTIAL_PATH + "0000000000";
// 删除节点
if(Objects.nonNull(client.checkExists().forPath(deletedPath))) {
client.delete().forPath(deletedPath);
}
}
}分布式命名服务
命名服务是为系统中的资源提供标识能力,可以利用zookeeper节点的树形分层结构和子节点的顺序维护能力来为分布式系统中的资源命名。
典型的分布式命名服务有以下几种场景:
- 分布式API目录:为分布式系统中各种API接口服务的名称、链接地址提供类似于JNDI中的文件系统的功能。比如:Dubbo中就使用zookeeper来维护全局的服务接口API的地址列表。服务提供者(Provider)启动的时候,会向zookeeper上的指定节点/dubbo/${serviceName}/providers写入自己的API地址。而服务消费者(Consumer)启动的时候,则会订阅该节点下服务提供者的URL地址,获取Provider的所有API。
- 分布式ID生成器:分布系统中,有时候需要生成一个全局唯一的ID,比如分布式session中的sessionId,可以使用zookeeper提供的顺序节点来提供有序的分布式ID。
- 分布式节点的命名:一个分布式系统通常由很多节点组成,而这些节点又是动态变化的,如何为这些大量的动态节点来命名呢,也可以使用zookeeper提供的顺序节点来实现。
可以看到,分布式命名服务主要使用zookeeper的两个核心能力,znode树形分层结构以及利用znode的特性(persistent、phemeral、sequential)。
由于分布式ID的使用场景很多,下面以分布式ID生成器来介绍。
分布式ID需要满足以下需求:
- 全局唯一:不能出现重复ID
- 高可用性:ID生成服务是最基础的支撑系统,被许多关键系统调用,一旦出现问题,可能会导致严重影响,故而一定要保证高可用性。
常用的分布式ID方案:
- Java的UUID:UUID可以由计算机本地生成,是一个16字节长的数字,转换为字符串则长达36个字节。其优点是可以本地生成,性能高,缺点是UUID过长,而且没有排序,无法保证趋势提增。
- 利用Redis生成ID:利用Redis的原子操作INCR和INCRBY来生成全局唯一的ID,高并发场景下可以使用这种方案。
- Twitter的SnowFlake算法:SnowFlake生成的ID为64bit的长整型数字,包含时间戳、机器ID、序列化(递增),一毫秒内可以生成400多万个ID,有需要的可以去查阅相关资料看看如何实现。
- Zookeeper生成ID:利用Zookeeper的顺序节点来生成全局唯一的ID。但是Zookeeper的作用只是用于分布式协调服务,不适用于大量高并发的场。景
- MongoDb的ObjectID:MongoDb是一个分布式的NoSQL数据库,每插入一个document都会自动生成全局唯一的”_id“字段值,这是一个12字节的字符串,也可以用于分布式ID。
利用Zookeeper的顺序节点来实现分布式ID,一个简单的示例如下:
查看代码
import org.apache.curator.framework.CuratorFramework;
import org.apache.curator.framework.CuratorFrameworkFactory;
import org.apache.curator.retry.RetryOneTime;
import org.apache.zookeeper.CreateMode;
import java.util.Objects;
public class SimpleZookeeperIDMaker {
CuratorFramework client;
final String path;
final String zkAddress;
public SimpleZookeeperIDMaker(String path, String zkAddress) {
this.path = path;
this.zkAddress = zkAddress;
this.client = initClient();
}
public static void main(String[] args) throws Exception {
String path = "/helios/case/id/ID_";
String address = "127.0.0.1:2181";
SimpleZookeeperIDMaker idMaker = new SimpleZookeeperIDMaker(path, address);
String id = idMaker.generateID();
System.out.println(id);
}
public String generateID() throws Exception {
String nodeName = createZNode();
if(Objects.isNull(nodeName)) return null;
return nodeName.replace(path,"");
}
public String createZNode() throws Exception {
return client.create()
.creatingParentsIfNeeded()
.withMode(CreateMode.EPHEMERAL_SEQUENTIAL)
.forPath(path);
}
public CuratorFramework initClient() {
// 创建Curator客户端实例
CuratorFramework client = CuratorFrameworkFactory.builder()
.connectString(zkAddress)
.retryPolicy(new RetryOneTime(1000))
.build();
client.start();
return client;
}
}流程说明:
- 创建Curator客户端示例
- 创建临时顺序znode节点,该节点客户端断开连接后即被删除
- znode节点创建成功后,获取编号,用该标号作为分布式ID,可以看到,输出内容诸如:0000000002、0000000003、0000000004之类
分布式锁
怎样利用Zookeeper实现分布式锁呢,流程如下:
- 首先创建一个persistent znode节点,比如/lock
- 然后利用Zookeeper的顺序节点特性,每一个要获取锁的线程都要现在/lock节点下创建一个Phemeral Sequential节点
- 我们知道,zk的顺序节点是有序的,此刻,判断一下自己是不是编号最小的那个节点,如果是则获取锁
- 利用Zookeeper的监听机制,监听排在自己前一个位置的znode节点是否还存在,如果不存在,则重新判断是否可以获取锁
详细的使用Zookeeper实现分布式锁流程以及实现代码可以参考笔者写的另一篇文章 ,Curator包中提供了一些常用的Recipes,包括分布式锁的实现,比如InterProcessMutex可重入锁。如果需要的话可以直接使用Curator提供的工具类,避免重复造轮子。
import org.apache.curator.framework.CuratorFramework;
import org.apache.curator.framework.CuratorFrameworkFactory;
import org.apache.curator.framework.recipes.locks.InterProcessMutex;
import org.apache.curator.retry.RetryOneTime;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class InterProcessMutexDemo {
public static void main(String[] args) throws Exception {
CuratorFramework client = CuratorFrameworkFactory.newClient("127.0.0.1:2181", new RetryOneTime(1000));
client.start();
InterProcessMutex mutex = new InterProcessMutex(client, "/helios/case/lock/inter-process-mutex");
ExecutorService executorService = Executors.newFixedThreadPool(10);
final int[] counter = {0};
for (int i = 0; i < 10; i++) {
executorService.submit(() -> {
for (int j = 0; j < 10; j++) {
try {
mutex.acquire();
counter[0]++;
System.out.println(counter[0]);
mutex.release();
}
catch (Exception e) {
e.printStackTrace();
}
}
});
}
executorService.shutdown();
}
}说明:上述示例代码为InterProcessMutex的简单示例,流程如下:
- 创建Zookeeper客户端实例,并与Zookeeper服务器建立连接
- 创建InterProcessMutex,需要配置Zookeeper客户端和znode节点path地址
- 创建一个线程池用来执行线程
- 每个线程依次对counter进行+1操作
可以看到控制台输出,counter按照次序有序输出。
使用Zookeeper实现分布式锁,可以有效的解决分布式问题,不可重入问题,使用起来也比较简单。但是,对于高并发场景,Zookeeper实现的分布式锁性能并不高,这是因为锁的创建和释放都需要动态创建节点,而Zookeeper的数据更新操作都是有群首服务器来完成的,所以会存在一定的性能问题。对于高并发场景下的分布式锁,可以考虑使用Redis来实现。
参考文献
- 《Netty、Redis、Zookeeper高并发实战》
- 《Zookeeper分布式过程协同技术详解》

 浙公网安备 33010602011771号
浙公网安备 33010602011771号