
基于高层次综合器(Vivado HLS)的硬件优化[原创www.cnblogs.com/helesheng]
![基于高层次综合器(Vivado HLS)的硬件优化[原创www.cnblogs.com/helesheng]](https://img2023.cnblogs.com/blog/1380455/202302/1380455-20230209232006830-345615567.png) 介绍了在Vivado HLS中对硬件进行优化的方法
介绍了在Vivado HLS中对硬件进行优化的方法
最近在写一本Xilinx的FPGA方面的书,现将HLS部分内容在这里分享给大家,希望大家喜欢,也欢迎批评指正。以下原创内容欢迎网友转载,但请注明出处: https://www.cnblogs.com/helesheng
通过前面的学习,相信读者已经基本掌握了高层次综合器的基本使用方法,本小节将学习使用高层次综合器提供的工具,优化上一小节实现的FIR滤波器消耗的FPGA资源和执行时间。
仔细阅读代码8.4,可以发现它每次只接收一个数据x(点),输出一个数据(存储在y所指向的存储器中)。作为一个有限冲击响应滤波器(FIR),它的输出只由当前输入和以前的输入计算产生,这段代码将之前的输入数据都缓冲在shift_reg数组之中。函数中的for循环两个具体操作:其一,滤波器系数和输入历史数据之间的乘加运算。其二,对存储在shift_reg数组中历史数据进行移位,以将新的输入存储数组,并对老的历史数据进行进一步老化。
可以看出上述代码实现的FIR滤波器和用传统高级语言经由CPU或DSP逐句实现的方法没有多大区别,所有的计算仍然采用“串行”方式执行,并且需要在电路中增加大量流程控制逻辑。既没有发挥可编程逻辑器件“并行”化执行算法的优势,有没有节约多少硬件资源,可以通过多种手段优化上述高层次综合器代码。
1、优化条件判断语句
代码8.4中for循环内部的if条件判断语句将被高层次综合器综合后的硬件电路的工作效率十分低效,因为判断后两个分支中的乘加和移位操作都只有在if判断执行后才能真正执行,从而限制了后续优化中这些运算“并行化”的实现。是我们在优化中首先要解决的问题。另外,优化掉判断语句还能省去综合结果硬件电路中的条件判断电路,从而降低电路的整体复杂度,可谓一举多得。
仔细观察代码后可以发发现,去掉if条件判断并不困难。因为该判断中的一个分支只发生在i == 0时,i等于其他值的情况都只会执行另外一个分支;另外,所有的分支在每次循环中都必将被依次执行。因此,可以将i为0时对应的分支直接放到for循环的外部,最后执行即可,不会影响执行结果。得到优化代码如下(注意,代码中的Shift_Accum_Loop标签和C语言中语句的标签语法要素和作用完全相同,用于表示某些语句,不会产生任何实质性代码或硬件)。



1 #define N 11 2 typedef int coef_t; 3 typedef int data_t; 4 typedef int acc_t; 5 void fir(data_t *y,data_t x) 6 { 7 coef_t C[N] = {53,0,-91,0,313,500,313,0,-91,0,53}; 8 static 9 data_t shift_reg[N]; 10 acc_t acc; 11 int i; 12 acc = 0; 13 Shift_Accum_Loop: 14 for(i = N-1;i > 0;i--){ 15 shift_reg[i] = shift_reg[i-1]; 16 acc += shift_reg[i] * C[i]; 17 } 18 acc += x * C[0]; 19 shift_reg[0] = x; 20 * y = acc; 21 }
下图是代码8.6经高层次综合器综合后的结果,可以看到代码的设计延时明显降低,而乘加运算所使用的DSP48资源增加,显然计算的并行度增加了。
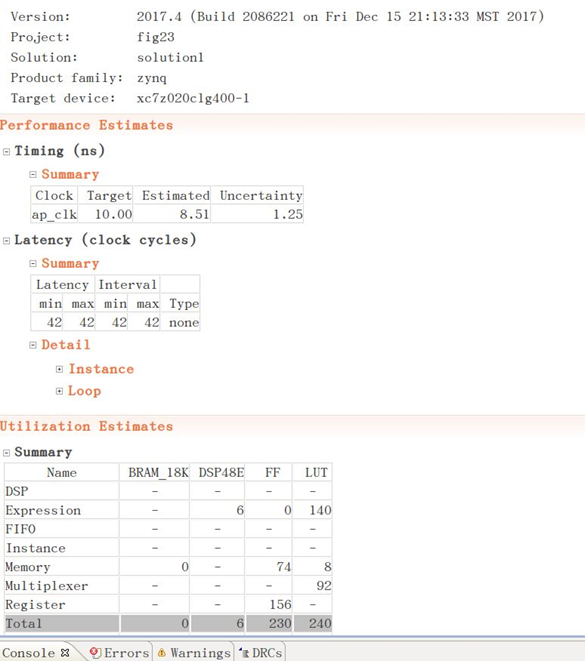
图8.3.1 优化后的综合报告1
2、for循环拆分
如前所述,代码8.6中的for循环中有两种操作:乘加(标签为MAC)和移位(标签为TDL),将它们分别放在两个for循环中,有利于高层次综合器针对每个循环进行硬件优化,提高整体的代码效率。拆分后的代码如代码8.7所示。
1 #define N 11 2 typedef int coef_t; 3 typedef int data_t; 4 typedef int acc_t; 5 void fir(data_t *y,data_t x) 6 { 7 coef_t C[N] = {53,0,-91,0,313,500,313,0,-91,0,53}; 8 data_t shift_reg[N]; 9 acc_t acc; 10 int i; 11 TDL: 12 for(i = N - 1;i > 0;i--){ 13 shift_reg[i] = shift_reg[i - 1]; 14 } 15 shift_reg[0] = x; 16 acc = 0; 17 MAC: 18 for(i = N-1;i >= 0;i--) { 19 acc += shift_reg[i] * C[i]; 20 } 21 * y = acc; 22 }
读者综合代码8.7后会惊异地发现他的设计延迟相比代码8.6不减反增!其实,这是很正常的现象,我们拆分for循环的目的是为了针对乘加和移位分别进行优化,而现在还未进行任何具体优化操作,拆分循环只会增加循环控制电路的复杂程度,性能自然降低了。我们需要进一步分别优化MAC和TDL两个循环。
3、移位循环的展开
如果不做专门的制定,高层次综合器将把硬件电路配置为顺序执行for循环结构。但对于循环的第i次计算不需要上一次(i-1次)循环计算的执行结果的“非依赖”循环,如果在硬件电路中增加对该for循环的并行性支持,可以进一步充分发挥可编程逻辑器件的并行结构优势,提升算法实现的效率。在代码8.7中实现历史数据存储移位的TDL循环就属于这类可以通过“循环展开”提升算法电路并行性的循环。
代码8.8将TDL循环展开为2次移位为一组的新循环体,即每次循环中循环体执行两个历史数据移位操作,这需要综合后得到的电路具有能够同时执行两个移位操作的硬件,但循环次数将降低为原来的一半。
1 TDL: 2 for(i = N - 1;i > 1;i = i - 2){ 3 shift_reg[i] = shift_reg[i - 1]; 4 shift_reg[i - 1] = shift_reg[i - 2]; 5 } 6 if(i == 1){ 7 shift_reg[1] = shift_reg[0]; 8 } 9 shift_reg[0] = x;
代码8.8由于每次对两个数据进行了移位,TDL循环中对索引i的操作变为每次减2(i == i - 2)。代码8.8还在循环后面增加了一个if条件判断,以防止循环次数为奇数时最后一次移位未被执行,当然如果事先知道N的值是奇数还是偶数,也可以避免使用这条判断语句。
上述展开操作,除了使用代码8.8所示的“手工”代码方式展开,还可以通过高层次综合器支持的指令方式“自动”完成。在Vivado HLS开发工具中,添加指令的方式有两种:
其一,直接在C语言源文件中嵌入编译脚本指令,具体位置在需要配置的循环体for语句之后。指令格式为:#pragma HLS unroll factor=2,以代表要求综合器将循环并行化为每次执行两个移位操作。(注意,这种嵌入源码的编译指令都以#开始)
1 TDL: 2 for(i = N - 1;i > 0;i--){ 3 #pragma HLS UNROLL factor=2 4 shift_reg[i] = shift_reg[i - 1]; 5 } 6 shift_reg[0] = x;
其二,通过图形界面编辑脚本指令,并将所有编译指令集中存放在专门的指令文件(Directive File)或循环所在的高级语言源文件中。这种方式需要在Vivado HLS界面右侧的指令区(Directive)中找到需要添加编译指令的循环,右击该循环体进行配置(只有在打开C源文件的情况下,才能在右侧的指令区找到需要编辑的循环)。指令编辑界面如下图8.3.2所示。
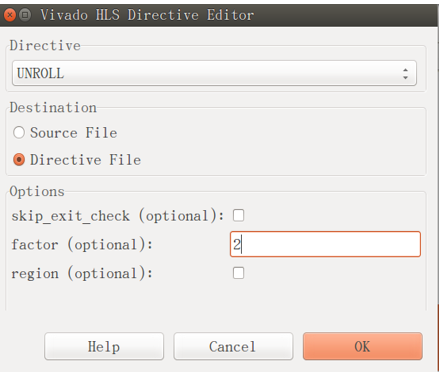
图8.3.2 高层次综合器指令编辑界面
在专门的指令文件添加过编译指令的循环将会在Vivado HLS开发环境右侧的指令区中看到以%开头的编译指令。如下图8.3.3所示。
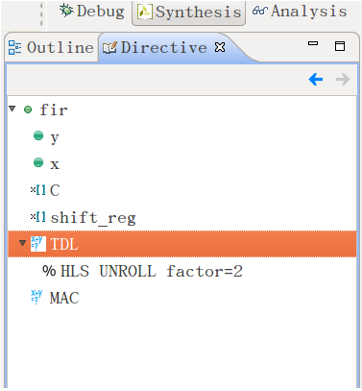
图8.3.3 添加了编译指令的指令区
显然,上述两种方式添加编译指令的展开方式具有阅读、修改方便,不易出错的优势,要远优于“手工”代码展开方式。若比较代码8.9所示的源码添加指令的方式和图8.2.14所示的在专门的指令文件中添加指令的方式哪种更好,则要根据开发者的需求来决定:源码和指令的分离有利于在更高层面上对工程整体进行优化,而直接在源码中写入指令则有利于针对具体代码的灵活优化。为方便叙述,本书后续都采用直接在源码中写入指令的方式进行编译配置和优化,但显然所有指令也可以通过图形界面完成配置。
最后,关于移位循环的展开还可针对移位寄存器本身的实现方式进行配置优化:若将移位寄存器shift_reg[N]配置在BRAM中,则由于BRAM只有两个读端口和一个写端口,则在单个时钟周期中最多完成一个写和两次读,代码8.8和8.9所希望的两次移位操作就只能在两个周期中才能完成。将所有的shift_reg[N]放在独立的寄存器中可以实现在单个时钟周期中完成多个移位寄存器单元读写的要求,使用编译指令#progmaHLS array_parition variable=shift_reg complete能够实现该功能。
4、乘加循环的展开
代码8.7中的乘加循环(标签为MAC的循环)中的每次乘加操作需要读取移位寄存器shift_reg[N]和系数寄存器C[N]中的值,并对它们相乘后累加到和acc中。如果要将这个乘加循环并行化,最大的障碍在于acc中的值存在“依赖关系”——即只有执行完上一次循环的加法得到acc的值后,才能执行下一次循环的加法。增加乘加循环并行度的关键是解除(或部分解除)这种依赖关系。
熟悉数字电路的读者应该知道,可编程逻辑器件可以实现加数多于二个的多加数的加法器,例如我们使用可以对五个加数求和的加法器,就可以解除四次乘加运算之间的结果“依赖关系”,从而增加综合结果电路的并行度。代码8.10就是利用多加数加法器增加解决依赖关系的实例。
1 MAC: 2 for(i = N - 1;i >= 3;i -= 4){ 3 acc += shift_reg[i] * C[i] + 4 shift_reg[i - 1] * C[i - 1] + 5 shift_reg[i - 2] * C[i - 2] + 6 shift_reg[i - 2] * C[i - 2] + 7 shift_reg[i - 3] * C[i - 3]; 8 } 9 for(;i >= 0; i--){ 10 acc += shift_reg[i] * C[i]; 11 }
其中,第一个for循环将五次加法合在了一个语句中实现,解除了这四次乘加结果求和对上一个乘加结果的依赖,使得这四个乘加可以并行执行(乘法操作可由不同的硬件,如DSP48E模块,同时分别完成)。当然,和前面的移位循环TDL一样,运算次数不一定能够整除并行因子4,需要后面一个for循环来完成最后的工作。如果实现指导循环次数为4的整数倍,后面的for循环也完全可以省去。
当然,代码8.10是为了方便的说明解决乘加循环依赖关系的办法给出的代码,实际工程中,工程人员一般通过Vivado HLS开发工具提供的添加指令功能在源码(在指令区中以#标志)或专门的指令文件(在指令区中以%标志)中添加编译指令的方式,自动添加心慌并行展开指令。完成代码8.10功能的编译指令为:#pragma HLS UNROLL factor=4。还可以通过在该指令中增加优化参数skip_exit_check来禁止高层次综合器检测并行化后循环是否完成(即代码8.10中的第二个循环),从而提高代码的效能。但这样做的前提是实现知道循环次数刚好能被展开因子整除。
若在编译指令中不给出展开因子factor,高层次综合器将把循环全部展开,不再通过多个时钟依次执行循环体,而是将每次循环都使用独立的硬件电路展开执行。这样将获得最快的执行时间,也将消耗非常多的硬件。代码8.11就是将乘加循环完全展开的代码,同图8.3.4是代码8.11的综合报告,可以看到设计延迟和吞吐量显著降低,但消耗的硬件资源也大大增加了。
1 AC: 2 for(i = N-1;i >= 0;i--) { 3 #pragma HLS UNROLL 4 acc += shift_reg[i] * C[i]; 5 }
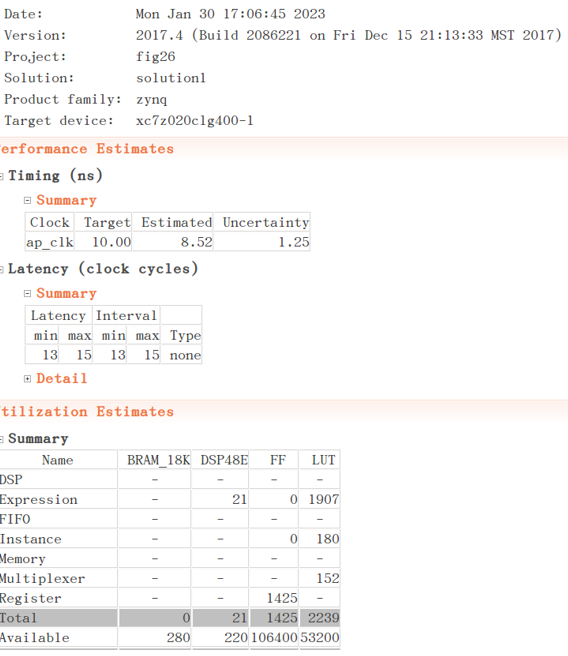
图8.3.4 优化后的综合报告2
需要注意的是,由于目标器件的资源是有限的,并非所有的展开都能实现,读者需要根据项目目标器件和项目性能需求综合取舍设计展开的而程度。
5、数据位宽优化
C语言本身定义了众多的数据类型,如定点的char、short、int、long等,浮点的float、double等。但由于C语言最初是为图灵计算机设计的,现代通用计算机处理数据的宽度多为8、16、32、64位等2的整数次幂,导致这些数据类型所对应的硬件也分别为8、16、32、64位。对可编程逻辑器件而言,并没有类似计算机这样对位宽的限制。因此高层次综合器的使用者可以根据算法的实际需要,定义任意宽度/精度的定点数据。
值得注意的是,高层次综合器针对C和C++使用不同的库和类型名称来实现任意精度的定点数。C语言使用的头文件名称为ap_cint.h(即需要在使用任意精度定点数的C源文件中包含#include “ap_cint.h”语句),使用的数据类型名称为intN或uintN,例如代码8.12所示。
1 int7 Var1; 2 uint58 Var2; 3 ……
C++使用的头文件名称为ap_int.h(即需要在使用任意精度定点数的CPP源文件中包含#include “ap_int.h”语句),使用的数据类型名称为ap_int<N>或ap_uint<N>,例如代码8.13所示。
1 ap_int<7> Var1; 2 ap_uint<58> Var2; 3 ……
浮点数方面,高层次综合器通过调用技术库的方式提供浮点运算功能,因此所使用的浮点数的格式必须符合IEEE754规定的浮点格式,而不能任意改变float和double类型指数部分和小数部分所占用的硬件宽度,否则将无法满足技术库中IP对数据格式的要求。
至于定点变量数据位宽的确定,可以遵循以下几个简单原则:
1)加法/减法的原则是,两个位宽同为n位的变量进行加法/减法后,结果占用的位宽为N+1位。
2)乘法的原则是,两个位宽同为n位的变量进行乘法后,结果占用的位宽为2×n位。
3)除法的原则是,一个位宽为n位的变量除以一个位宽为m位的变量后,若不考虑小数部分的话,结果占用的位宽为(n-m)位;若需要考虑使用定点小数表达结果,则可以根据除法结果需要的精度来确定结果占用的位宽。
以代码8.3和代码8.4为例,若输入x为12位补码输出ADC(数模转换器)的转换结果,则x可以定义为int12数据类型,存储历史数据的shift_reg[N]也可以定义为int12类型。系数数组C[N]的最大值和最小值分别为500和-91,可以定义为int9数据类型。acc需要存储N=11个12位数据与9位系数乘积(12+9=23位)结果,最多为23+4=27位(不小于log(11,2)的最小整数为4)。若需要保留acc的所有计算精度,可见acc定义为int27类型。
6、流水线优化
正如本章第一小节最后介绍的,如图8.1.11所示,对高层次综合器输出结果的硬件电路优化的另一种有效方式,是通过“流水线”的方法提高硬件电路的并行性,从而提升电路处理数据的平均吞吐量性能。
但在默认情况下,高层次综合器不会开启流水线优化,只是顺序完成高级语言给出的流程或循环任务。实际上在大多数情况下,在分解算法所需的硬件操作后可以发现某些“微步骤”之间不存在数据依赖关系,可以通过流水线方式并行化这些微步骤。例如FIR滤波器例子中的每个乘加操作可以分解为读取移位寄存器和系数数值,执行乘法操作和执行加法操作三个微步骤。对第一组两个乘数的乘法操作与对第二组两个乘数的读操作之间不存在数据依赖关系,硬件电路完全可以在执行第一组数乘法的同时,读取第二组数,从而大大节约算法的整体执行时间。同样道理,执行加法操作的同时也可以执行后续数据的读取和乘法操作。因此在最佳状态下,可以实现图8.3.4所示的乘加运算流水线,流水线中同时被处理的有三笔数据。
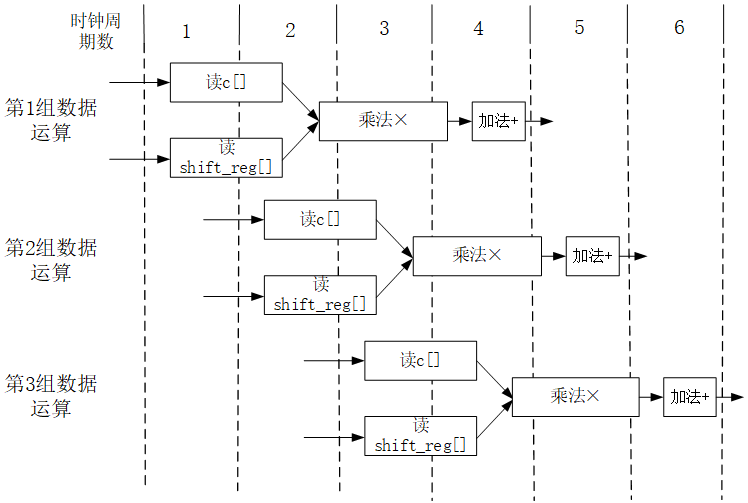
图8.3.4乘加操作流水线示意图
高层次综合器支持通过编译指令实现对流水线的配置,在Vivado HLS环境右侧的指令窗口中对代码8.7中的MAC循环右击添加指令,其指令格式为:#pragma HLS PIPELINE II=2。其中PIPELINE代表这是一条流水线配置指令,字符串“II=2”中的数字代表循环起始间隔,也就是图8.3.4两次乘加执行的延迟时间。当然这个延迟时间数值不一定能够实现,开始阶段可以从大到小使用不同的数值进行尝试,直到获得最佳时间和资源效率。当然,由于本FIR滤波器中乘加操作的次数为11,尝试使用大于或等于11的数值是没有意义的。如果对循环起始时间间隔没有明确的要求只要获得最佳性能,则可以在指令中省略这部分,将指令改写为#pragma HLS PIPELINE,高层次综合器会尝试帮助你找出最佳的数值。
代码8.7中的TDL循环的循环体是进行移位操作,移位操作也可以分解为读取数据和移位写入两个微步骤,对TDL循环使用流水线优化指令也能获得提升执行时间的效果。
图8.3.5所示的是对代码8.6中的MAC和TDL两个循环都使用了流水线优化后的综合报告,对比图8.3.1得到的未做流水线优化后的综合报告,可发现目标硬件的性能得到了很大提升。
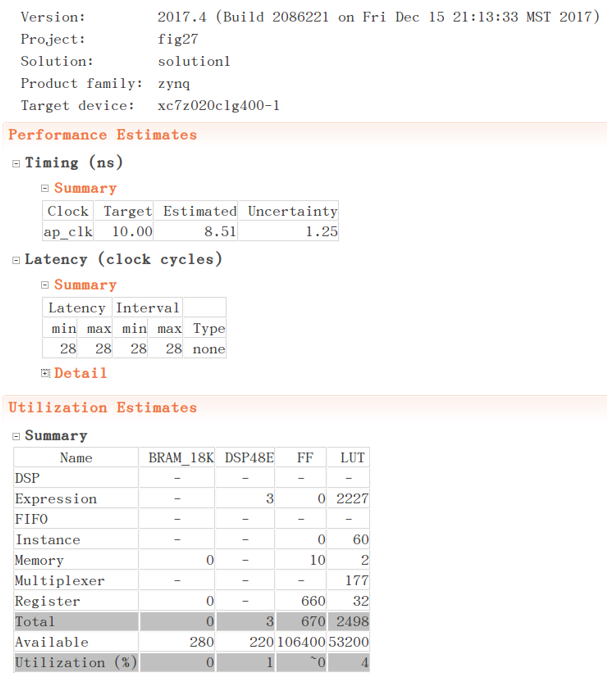
图8.3.5 优化后的综合报告3
需要特别指出的是,循环展开和流水线优化对电路处理算法的优化作用不一定能够叠加。原因是当循环被充分展开后,对每一笔数据的处理都有专门的硬件电路负责并行处理,这时再试图通过流水线优化提高并行度的效果就不明显了。对比展开和流水线优化两种方式可以发现:展开是纯粹的以硬件资源换处理时间——靠投入更多资源提升处理能力;流水线优化是通过调度现有资源工作时序,提升每个资源的工作效率实现的,需要增加的资源投入比较有限。
高层次综合器是Xilinx可编程逻辑器件开发中更新最活跃的工具之一,自问世以来获得了大量的关注,功能也发生了很大的改变。本章的介绍具有基础性和引导性,试图在较短的篇幅内帮助读者建立高层次综合器的基本概念,为未来的进一步使用铺平道路。但本章写作中难免出现挂一漏万和内容更新不及时的问题,建议需要深入该工具的读者关注Xilinx官方网站不断更新的应用笔记。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· 写一个简单的SQL生成工具
· AI 智能体引爆开源社区「GitHub 热点速览」
· C#/.NET/.NET Core技术前沿周刊 | 第 29 期(2025年3.1-3.9)