
Machine Learning---005
Machine Learning---005
局部多项式回归
局部多项式回归的拟合
局部多项式回归的拟合,需要我们在每个点\(x_0\)完成以下目标:
得到的解为
实际上就是一种加权最小二乘,密度低的地方的数据权重小,密度高的地方的数据权重大。
局部多项式回归的性质
-
有偏差的话,只能至少是\(d+1\)次项。
-
偏差小的代价是方差大(过拟合)。
-
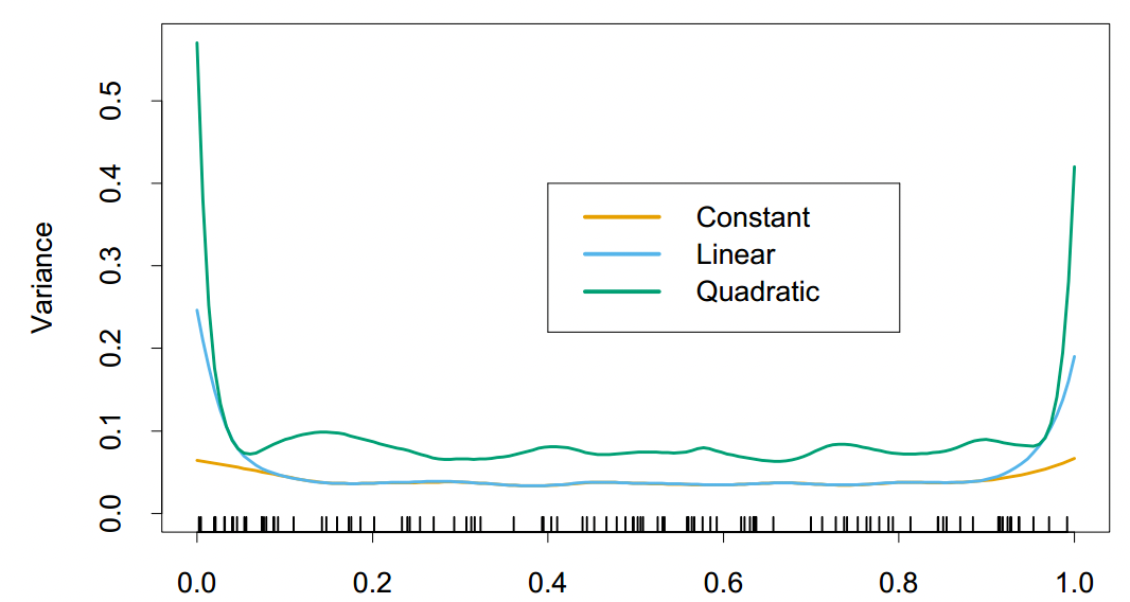
局部线性拟合有助于在边界处显着减小偏差,并且方差增大成本很小。局部二次拟合对在边界出减小偏差几乎没有作用,但是会大大增加方差。下图可以很好地展示这点。
![image]()
-
边界效应在二维或更高维度中是一个更大的问题,因为边界上的点的比例更大。
-
局部回归的在更高维的情况下效果不是很理想。
-
当维度 p 增大时但样本量没有随之增大时不可能同时满足low bias和low variance。
局部似然
局部似然拟合
局部似然(线性)的拟合,需要我们在每个点\(x_0\)完成以下目标:
同样可以视为加权。稍微拓展下,将上式子改写成:
\(z\)是$x $ or \(y\)经过变换得到的。\(\eta(x,y)\)是拟合成的函数形式。若取\(\eta(x_i,\theta(x_0))=x_i^T\theta(x_0)\)则意味着这是一个线性局部拟合。
局部似然应用
-
我们可将其用在时间序列上。假如我们想拟合一个 Autogressive time series model with order of k (即\(y_t = \beta_0 + \beta_1 y_{t-1}+ ...+ \beta_k y_{t-k}+\epsilon_t\)),我们可以设\(z_t = f(y_{t-1},...,y_{t-k})\)然后用上面式子拟合就成。\(K_\lambda(z_0,z_i)\)则可以用来控制时间序列对不同距离点的记忆能力。
-
我们还可以将其用在Multiclass Linear Logistic Regression上。对feature \(x_i\)来说,设其可能有的分类集合为 \(g \in \{ 1,2,3,...,J\}\),则Linear Model有以下形式:
\(J\)分类的最大似然函数可被转化为:
然后求解即可。
核密度函数估计以及分类
核密度函数估计
Parzen 估计
这里\(K_{\lambda}\)通常是Gaussian Kernel,故:
这里\(\phi_\lambda\)表示均值为 0 标准差为$λ $的高斯密度函数。
注意:\(\hat f_X(x)\)在R中积分值为1,因为其是概率密度。
核函数分类
通过贝叶斯定理以直接的方式使用非参数密度估计进行分类:
最后选出概率最大类别即可。
朴素贝叶斯分类器
朴素贝叶斯模型假设给定一个类\(G = j\), 特征\(X_k\)相互独立,我们可以得到:
对其进行对数变化:
设\(\lambda_j = \lambda\)可以减少参数量,但是会产生“空穴区域”,示意图如下:
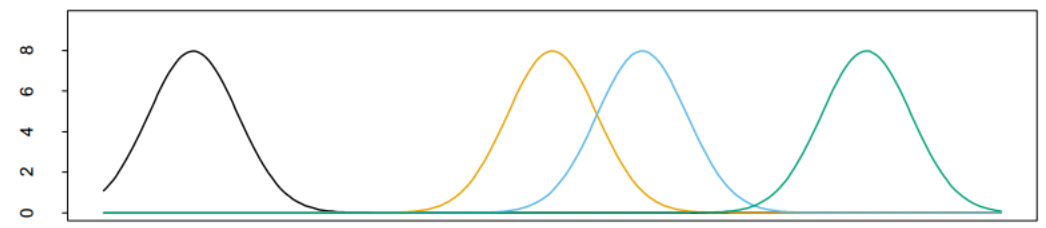
可以看到,有些地方\(Pr(X|G=j)\)对于所有j都几乎为0,并不能比较好地覆盖整个横轴。这些密度较低地方的X可能对计算造成严重影响。重新正则化径向基函数可以避免这个问题:
前面图中四个处理后如下:
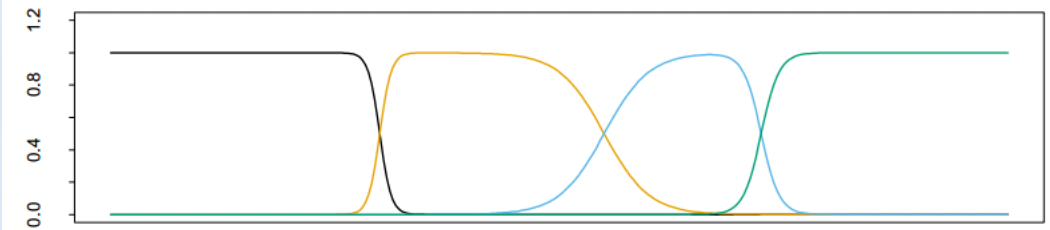
(参数估计未完成待补充)
Nadaraya-Watson 核估计可以视为正则化的径向基函数的扩展。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号