
上一步建立好模型之后,现在就可以训练模型了。
主要代码如下:
import sys #将当期路径加入系统path中 sys.path.append("E:\\CODE\\Anaconda\\tensorflow\\Kaggle\\My-TensorFlow-tutorials-master\\01 cats vs dogs\\") import os import numpy as np import tensorflow as tf import input_data import model #%% N_CLASSES = 2 #类别数 IMG_W = 208 # resize the image, if the input image is too large, training will be very slow. IMG_H = 208 BATCH_SIZE = 16 CAPACITY = 2000 #队列中元素个数 MAX_STEP = 10000 #最大迭代次数 with current parameters, it is suggested to use MAX_STEP>10k learning_rate = 0.0001 # with current parameters, it is suggested to use learning rate<0.0001 #%% def run_training(): # you need to change the directories to yours. #train_dir = '/home/kevin/tensorflow/cats_vs_dogs/data/train/'#数据存放路径 train_dir = 'E:\\data\\Dog_Cat\\train\\' #logs_train_dir = '/home/kevin/tensorflow/cats_vs_dogs/logs/train/'#存放训练参数,模型等 logs_train_dir = "E:\\CODE\\Anaconda\\tensorflow\\Kaggle\\My-TensorFlow-tutorials-master\\01 cats vs dogs\\" train, train_label = input_data.get_files(train_dir) train_batch, train_label_batch = input_data.get_batch(train, train_label, IMG_W, IMG_H, BATCH_SIZE, CAPACITY) train_logits = model.inference(train_batch, BATCH_SIZE, N_CLASSES)#获得模型的输出 train_loss = model.losses(train_logits, train_label_batch)#获取loss train_op = model.trainning(train_loss, learning_rate)#训练模型 train__acc = model.evaluation(train_logits, train_label_batch)#模型评估 summary_op = tf.summary.merge_all() sess = tf.Session() train_writer = tf.summary.FileWriter(logs_train_dir, sess.graph)#把summary保存到路径中 saver = tf.train.Saver() sess.run(tf.global_variables_initializer()) coord = tf.train.Coordinator() threads = tf.train.start_queue_runners(sess=sess, coord=coord) try: for step in np.arange(MAX_STEP): if coord.should_stop(): break _, tra_loss, tra_acc = sess.run([train_op, train_loss, train__acc]) if step % 50 == 0: print('Step %d, train loss = %.2f, train accuracy = %.2f%%' %(step, tra_loss, tra_acc*100.0)) summary_str = sess.run(summary_op) train_writer.add_summary(summary_str, step) if step % 2000 == 0 or (step + 1) == MAX_STEP: checkpoint_path = os.path.join(logs_train_dir, 'model.ckpt') saver.save(sess, checkpoint_path, global_step=step)#保存模型及参数 except tf.errors.OutOfRangeError: print('Done training -- epoch limit reached') finally: coord.request_stop() coord.join(threads) sess.close() run_training()
一些函数说明如下:
1)tf.summary.merge_all
作用:Merges all summaries collected in the default graph.
2)tf.summary.FileWriter
作用:Writes Summary protocol buffers to event files.
3)tf.train.Saver
作用:保存和恢复变量。
举例:
saver.save(sess, 'my-model', global_step=0)
==> filename: 'my-model-0'
...
saver.save(sess, 'my-model', global_step=1000)
==> filename: 'my-model-1000'
4)add_summary
作用:Writes Summary protocol buffers to event files.
程序运行后,控制台输出如下:
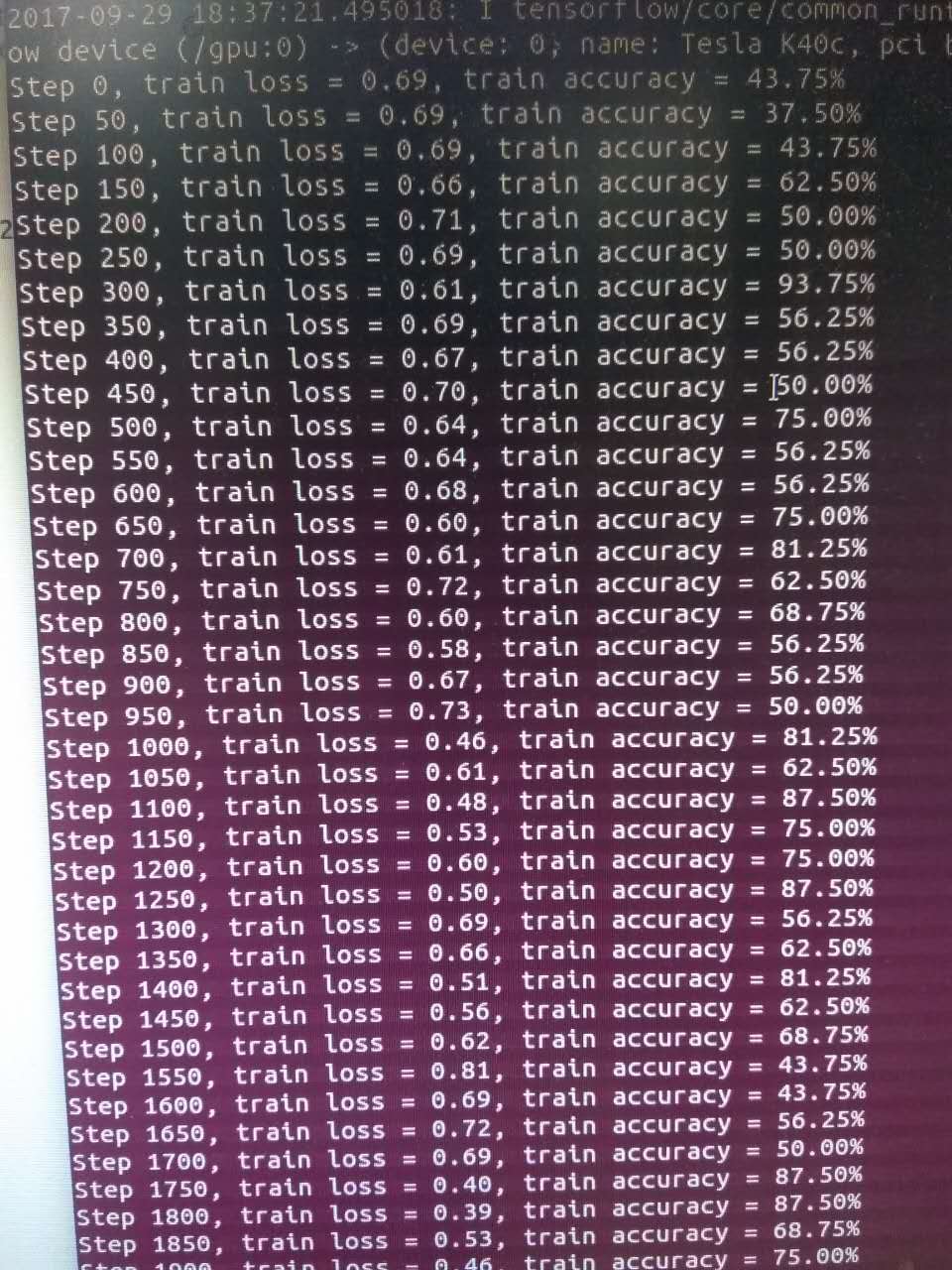
训练期间,也可以使用tensorboard查看模型训练情况。
可以使用如下命令打开tensorboard。
tensorboard --logdir=log文件路径
log文件路径即为程序中设置的logs_train_dir。
启动tensorboard之后,打开浏览器,输入对应网址,即可查看训练情况。
整体解码如下图:
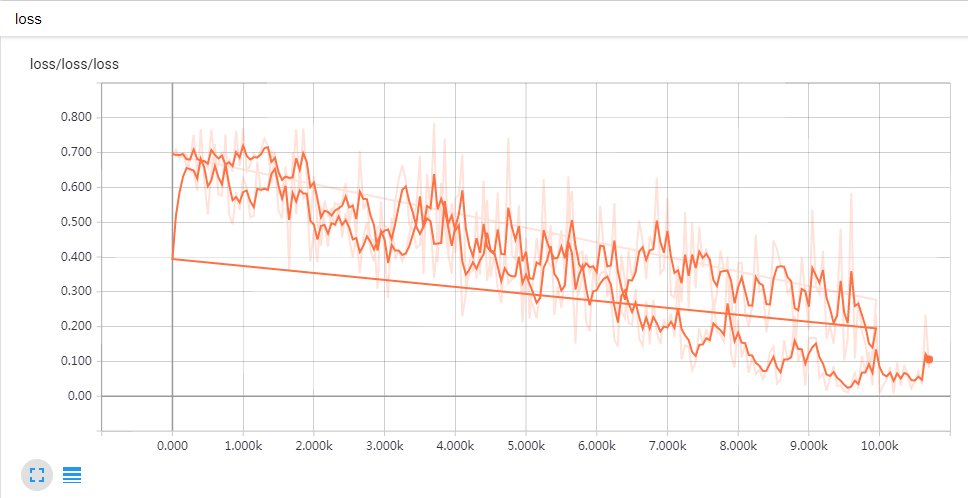
loss与step的关系如下(两条曲线的原因是训练了两次,一次迭代了10000步,另一次迭代了15000步):
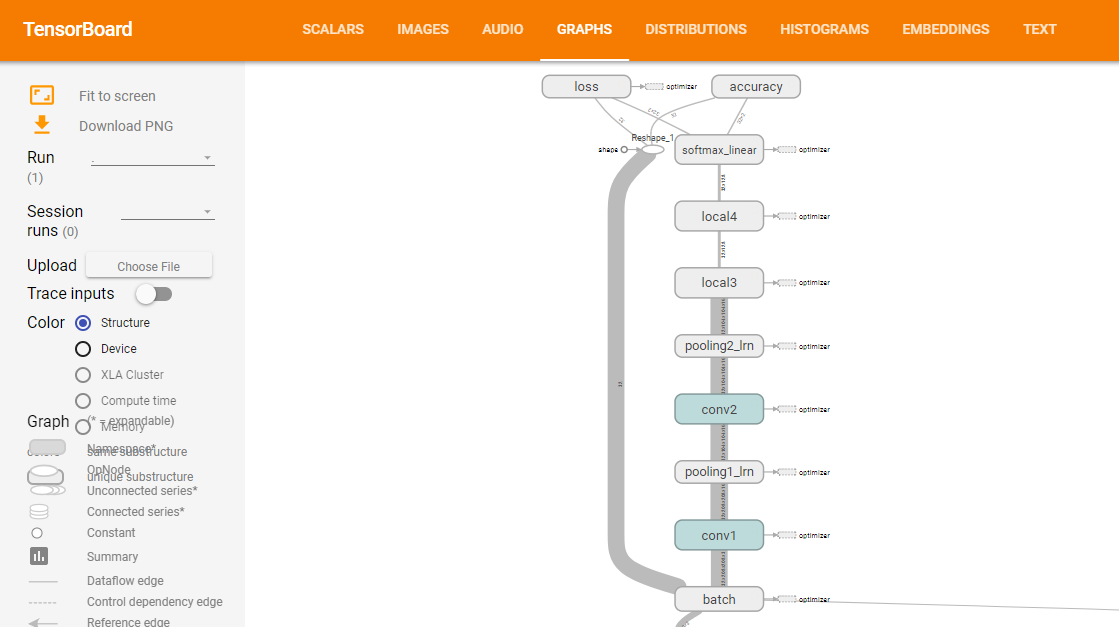
也可以选择查看模型:
说明:
代码来自:https://github.com/kevin28520/My-TensorFlow-tutorials,略有修改
函数作用主要参考tensorflow官网。https://www.tensorflow.org/versions/master/api_docs/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号