
实例分割综述
论文:A Survey on Instance Segmentation: State of the art
目标检测( Object detection)不仅需要提供图像中物体的类别,还需要提供物体的位置(bounding box)。语义分割( Semantic segmentation)需要预测出输入图像的每一个像素点属于哪一类的标签。实例分割( instance segmentation)在语义分割的基础上,还需要区分出同一类不同的个体。
本文主要介绍实例分割的背景( background),问题( issues),技巧方法( techniques),进展( evolution),热门的数据集( popular datasets),最先进的相关工作( related work up to the state of the art)和未来的发展方向( future scope)。
1. Introduction
1.1 Background
物体分类只要预测出图像中出现的物体的类别;目标检测( Object detection)不仅需要提供图像中物体的类别,还需要提供物体的位置(bounding box)。语义分割( Semantic segmentation)需要预测出输入图像的每一个像素点属于哪一类的标签。实例分割( instance segmentation)在语义分割的基础上,还需要区分出同一类不同的个体。如下图Figure 1所示。

注:作者给出语义分割(c)与实例分割(d)的示意图应该是弄反了。
1.2 Issues
对于语义分割( semantic segmentation),我们希望分割精度( segmentation accuracy)和分割效率( segmentation efficiency)都达到一个比较好的程度。好的分割精度主要表现在定位的精确和物体类别识别的准确;好的分割效率指的是在可接受的内存/存储的情况下,时间达到实时。
用于分割的目标检测器的重要组成部分之一是良好的特征表示( good feature representation),它在目标检测中其中至关重要的作用。以前,有一些手工设计的特征,如SIFT,HOG等;目前大都是使用CNN来提取特征。
基于CNN的检测器,如RCNN,Faster RCNN和YOLO等,通常使用最上的CNN层作为物体的表示。不过存在一个问题,就是物体的尺度变化很大,这对检测任务是一个难点。解决这个问题的其中一个方法是使用图像金字塔( pyramid of images),但是这个方法比较耗资源和耗时。
实例分割目前存在的一些问题和难点。
-
小物体分割问题。深层的神经网络一般有更大的感受野,对姿态,形变,光照等更具有鲁棒性,但是分辨率( resolution)比较低,细节也丢失了;浅层的神经网络的感受野比较窄,细节比较丰富,分辨率比较大,但缺少了语义上的信息。因此,如果一个物体比较小时,它的细节在浅层的CNN层中会更少,同样的细节在深层网络中几乎会消失。解决这个问题的方法有dilated convolution和增大特征的分辨率。
-
处理几何变换( geometric transformation)的问题。对于几何变换,CNN本质上并不是空间不变的( spatially invariant)。
-
处理遮挡( occlusions)问题。遮挡会造成目标信息的丢失。目前提出了一些方法来解决这个问题,如 deformable ROI pooling,deformable convolution和 adversarial network。另外,也可能可以使用GAN来解决这个问题。
-
处理图像退化( image degradations)的问题。造成图像退化的原因有光照,低质量的摄像机和图像压缩等。不过目前大多数数据集(如ImageNet,COCO和PASCAL VOC等)都不存在图像退化的问题。
2. Instance Segmentation Techniques: A Taxonomy
2.1 Classification of mask proposals
下图Figure2 展示了 Classification of mask proposals的大体框架。

2.1.1 Bottom-up Mask Proposals
在COCO推广之前,现代意义的实例分割是由 Hariharan等人(见论文: Simultaneous detection and segmentation)引入的。提出的方法包括mask proposals的生成,然后对这些生成的proposal进行分类。早期的时候,这种mask proposal的分类方法在其他很多地方使用。比如说Selective Search,可以用该方法获取box detection并用于语义分割;该方法也同样可以用于实例分割上。
2.1.2 Deep Learning
在深度学习热门之前,一般依赖于 bottom-up mask proposal的生成。后来,该方法就被新的结构替代了,如RCNN。尽管RCNN有比较高的分割精度,但是也有一些缺点。比如,RCNN训练时是多阶段的,每一阶段需要分开训练,比较慢,并且比较难优化。后来,Fast RCNN和Faster RCNN等解决了这些问题。
2.2 Detection followed by segmentation
The popular approach for instance segmentation involves object detection using a box followed by object-box segmentation。
下图Figure 3展示了这种方法的大体框架。
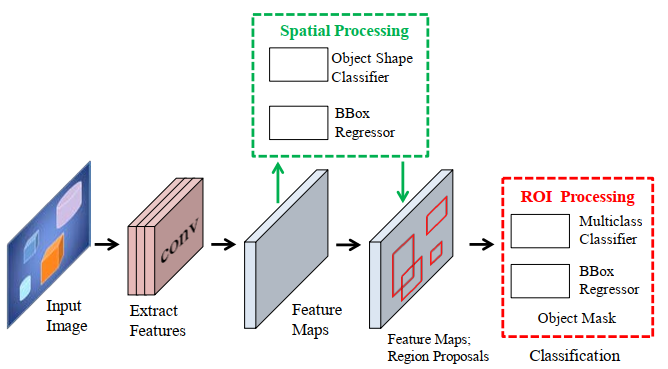
2.2.1 Mask Based Techniques
其中一个比较成功的方法是Mask RCNN。Mask RCNN是在Faster RCNN的基础上进行改进的,增加了一个简单的mask predictor。Mask RCNN训练更加容易,有更好的泛化性,并且在Faster RCNN上只需增加一点点的计算量。Mask RCNN最终精度也是不错的。
2.2.2 Other Techniques
检测目标bounding box,下面方法也会使用:
-
sliding-window techniques
-
region-based techniques
2.3 Labelling pixels followed by clustering
该方法包括将每一个图像像素点进行分类标注。接下来是使用聚类算法将像素分组到对象实例中。总体框架如下:

该方法得益于语义分割的积极发展,可以预测高分辨率的object mask。相比于 detection-followed-by-segmentation方法,该方法的精度较低;另外由于像素标记需要密集的计算,通常需要更多的算力。
2.4 Dense sliding window methods
该方法的总体架构如下:
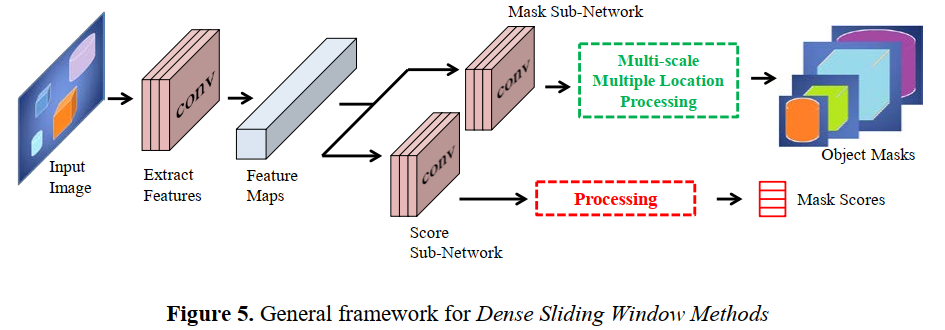
2.4.1 Class Agnostic Mask Generation Techniques
这些方法使用密集滑动窗口( dense sliding-window)的方法来生成CNN的mask proposal,比如DeepMask和InstanceFCN等。
2.4.2 TensorMask
与2.4.1提到的方法不同, TensorMask使用了一个新的架构并且有更好的效果。TensorMask涉及对多个类进行分类,这是与预测mask并行完成的。该特点也对实例分割很有用。该方法在COCO上有不错的表现,但是算法的复杂度比较高。
下面的表格Table 1是对Section 2的一个总结。

3. The Evolution of Instance Segmentation
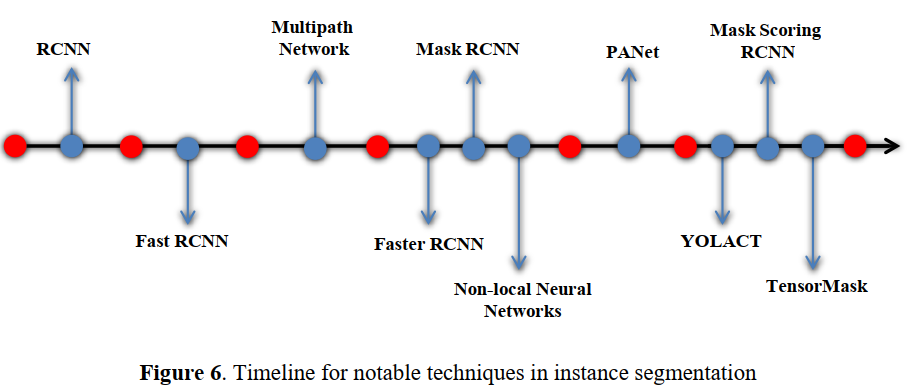
Section 2部分提到了很多算法,这些算法提出的时间线如下图Figure 6。
3.1 RCNN
RCNN是一篇比较早的使用CNN来做实例分割的。该方法结合了AlexNet和selective search的region proposal方法。训练RCNN的包括如下步骤:
-
使用selective search计算region proposals
-
使用region proposals来fine-tune一个已经预训练好的CNN模型,如AlexNet
-
CNN提取到特征之后,利用SVM分类器来对不同类别分类
RCNN虽然有较高的精度(当时而言),但是也有很多缺点,如多阶段的训练比较慢也比较难(不同阶段需要单独训练);训练SVM分类器和BBox regressor也是分开的,这导致需要更多的资源和时间;另外,测试也很慢,每一个object proposal都需要经过一遍CNN来提取特征。后续,Fast RCNN和Faster RCNN针对这些缺点做出了改进。
3.2 Fast RCNN
Fast RCNN解决了一部分RCNN的缺点,也提高了目标检测的精度。Fast RCNN使用端到端的训练方法。它同时学习sofamax分类器和特定类的bbox回归,而不是像RCNN那样单独训练模型的各个部分。Fast RCNN采用共享卷积和ROI pooling 的方法来提取region proposal的区域特征。这种方法可以大大加快训练速度。
3.3 MultiPath Network
见论文: Zagoruyko S, Lerer A, Lin T-Y, Pinheiro PO, Gross S, Chintala S, Dollár P (2016) A multipath network for object detection. arXiv preprint arXiv:160402135
3.4 Faster RCNN
见论文: Ren S, He K, Girshick R, Sun J (2017) Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Transactions on Pattern Analysis and Machine Intelligence 39 (6):1137-1149. doi:10.1109/TPAMI.2016.2577031
3.5 Mask R-CNN
见论文: He K, Gkioxari G, Dollar P, Girshick R (2018) Mask R-CNN. IEEE transactions on pattern analysis and machine intelligence. doi:10.1109/tpami.2018.2844175
3.6 MaskLab
见论文: Chen L, Hermans A, Papandreou G, Schroff F, Wang P, Adam H MaskLab: Instance Segmentation by Refining Object Detection with Semantic and Direction Features. In: 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 18-23 June 2018 2018. pp 4013-4022.
doi:10.1109/CVPR.2018.00422
3.7 Non-local Neural Networks
见论文: Wang X, Girshick R, Gupta A, He K Non-local Neural Networks. In: 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 18-23 June 2018 2018. pp 7794-7803. doi:10.1109/CVPR.2018.00813
3.8 Path Aggregation Network (PANet)
见论文: Liu S, Qi L, Qin H, Shi J, Jia J Path aggregation network for instance segmentation. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018. pp 8759-8768
3.9 Hybrid Task Cascade
见论文: Chen K, Pang J, Wang J, Xiong Y, Li X, Sun S, Feng W, Liu Z, Shi J, Ouyang W (2019) Hybrid task cascade for instance segmentation. arXiv preprint arXiv:190107518
3.10 GCNet
见论文: Cao Y, Xu J, Lin S, Wei F, Hu H (25 Apr 2019) GCNet: Non-local Networks Meet SqueezeExcitation Networks and Beyond. doi:arXiv:1904.11492v1
3.11 YOLACT
见论文: Bolya D, Zhou C, Xiao F, Lee YJ (2019) YOLACT: Real-time Instance Segmentation. arXiv preprint arXiv:190402689
3.12 Mask Scoring R-CNN
见论文: Huang Z, Huang L, Gong Y, Huang C, Wang X (2019) Mask Scoring R-CNN. arXiv e-prints
3.13 TensorMask
见论文: Chen X, Girshick R, He K, Dollár P (2019) TensorMask: A Foundation for Dense Object Segmentation. arXiv preprint arXiv:190312174
4. Datasets
下面介绍一些热门的实例分割的2D图像数据集(2D图像指灰度图像或者RGB图像)。
-
Microsoft Common Objects in Context (COCO) Dataset。提供了82783张训练图像,40504张验证集图像,超过80000张的测试图像;包含80类物体。
-
Cityscapes Dataset。该数据集是一个城市-街道-场景( urban-street-scene)图像的大集合。它侧重于对街景的语义理解。该数据集提供了语义标注,特定实例的标注和特定像素的标注,包含5000张标注良好的图像和20000张粗略标注的图像。
-
The Mapillary Vistas Dataset (MVD)。该数据集是另外一个大型的街景图像数据集。它包含25000张标注好的图像,66个类别。
5. Summary and Discussion
在这一部分,我们主要讨论基于深度学习的实例分割出现的关键因素和问题。
5.1 Detection frameworks: Two Stage versus Single Stage
如果以阶段数作为框架分类的方法,那么可以分为二阶段( Region based)和一阶段( unified framework)。
如果计算资源比较丰富,那么两阶段框架比单阶段框架有更好的精度。这是因为两阶段的框架更加灵活,更加适合于 region based detection,如 Mask RCNN。
一阶段的检测器,如YOLO,通常比两阶段的检测器速度上更快,这是因此一阶段检测器缺少了预处理,backbone比较轻量,候选区域个数也更少,并且使用全卷积。然而一阶段框架相比于二阶段框架比较难检测小目标。
为了提高检测器的精度与效率,大家做了很多尝试,最终导致一些关键的设计选择趋同:
-
全卷积网络框架
-
从相关任务中探索互补的信息,如Mask RCNN
-
使用滑动窗口
-
主干网络中多层信息的融合
5.2 Backbone networks
主干网络对精度上的影响是一个很重要的因素。尽管如ResNet、ResNext等深度网络很成功,但是这些都比较耗计算资源。
5.3 Improvement in robustness of representation of objects
遇到的问题以及解决方法。
-
目标的大小/尺度( Object Size/Scale)。尤其是小目标,姿态等是难点。解决方法有如下:
-
使用图像金字塔( image pyramids)
-
使用不同卷积层不同分辨率的特征
-
在网络中提高分辨率( Up-scaling to better resolution)来检测小目标
-
遮挡、形变和其他因素( Occlusion, deformation and other factors)。
-
使用空间转换网络( spatial transformer network)。 该方法利用回归得到变形区域,然后根据变形区域对特征进行变形。
-
旋转问题在实际环境中经常出现,但是热门数据集(如COCO)中没有旋转角度很大的情况
-
遮挡问题在本领域研究比较少
5.4 Detection proposals
检测方案大大减少了实例分割候选对象的搜索空间。其中RPN是一个不错的方案。
5.5 Strengths and weaknesses with various Instance Segmentation Techniques
各种实例分割技术的优缺点如下表Table 3.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号