hbck2的一些用法
一、执行 hbase org.apache.hbase.HBCK2 可以看到下面一些选择项
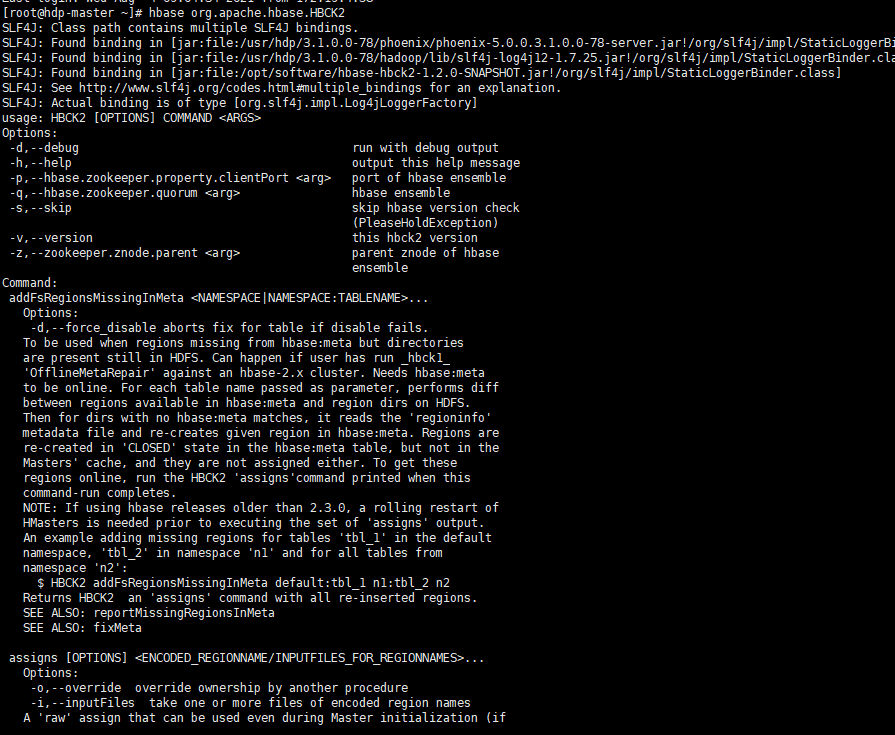
**示例: -d 打印debug日志 -s 跳过客户端与服务端一致性的版本检测
hbase org.apache.hbase.HBCK2 -d -s bypass
1、bypass [OPTIONS] ...
HBCK2的核心功能,bypass可以将一个或多个卡住的procedure进行释放。
原理很简单,在procedure的类里有一个bypass的flag, 每次执行时会检查这个flag是否为true,如果为true则直接返回null, 这样procedure就会被认为执行成功。
而我们的bypass就是把这个procedure对象中的这个flag设为true。这样stuck的procedure就能够不再执行,后续的修复工作才能继续。
返回值为true则是成功,false是失败。
参数解析:
-o,--overide
在执行bypass之前先会尝试去拿IdLock, 如果procedure还在运行就会超时返回null,但是设置了这个参数即使拿不到IdLock也会去将procedure的bypass flag设为true。
-r, --recursive
在bypass一个procedure时也会将这个procedure的所有子procedure进行递归的bypass。例如我们bypass一个对table schema修改的procedure, 就需要加上-r参数,才能把这个操作的所有子procedure都bypass掉。
-w, --lockWait
上文提到的等待IdLock的超时时间配置,默认为1ms
2、assigns [OPTIONS] <ENCODED_REGIONNAME>...
将一个或多个region再次随机assign到别的机器上,返回值是创建的pid则为成功,-1则为失败。
参数解析:
-o,--override
这里的override跟bypass的override不同,因为assign本身就会创建一个新的procedure, 所以肯定是不涉及到拿IdLock的,但是这里涉及到资源锁的问题。因为之前卡住的资源锁即使在bypass后也不会释放(用于fence, 防止更多未知的错误操作),所以需要加一个-o去手动释放这个资源锁。
3、unassigns <ENCODED_REGIONNAME>...
将一个或多个region unassign,返回值是创建的pid则为成功,-1则为失败。
参数解析:
-o,--override,与assigns的一致
4、setTableState
可能的table状态, ENABLED, DISABLED, DISABLING, ENABLING
在table的状态和所有的region状态不一致时可以用这个命令进行修复
5、serverCrashProcedures ...
手动schedule一个或多个serverCrashProcedure, 如果有serverCrashProcedure没有执行成功,但是procedure log已经丢失了,那么可以利用这个命令进行修复。返回值为创建的pid则为成功,-1则为失败。
patch在HBASE-21393[3],目前这个功能在release版本还没有。
所有的武器我们都有了,再回顾一下之前提到的问题,我们应该怎么处理呢?在Case解决中我们会详细阐述应该怎么处理,这里大家可以先思考一下。
二、问题查找
1、canary tool
模拟用户的读写请求,去访问集群上的表。当我们需要检查集群meta上记录的region assignment跟实际region server上打开的region是否一致时,可以使用这个命令去检查:
hbase canary -f false -t 6000000
这个命令会向meta上的记录的每个region发送一个get请求,将-f设为false是为了不在遇到第一个错误时退出,-t则是这个命令的超时时间,我们设成了6000秒。在执行完成以后可以通过grep ERROR来找到那些有问题的region。
需要注意的是因为是模拟客户端发送的get请求,最好将HBase的客户端超时时间和超时次数配的小一些,否则会很慢。
PS: canary 本身也很适合用来作为集群可用性的监控
2、页面状态
其实大部分的信息都会在master的页面上展示出来,我们来详细的介绍一下:
Procedures & Locks:

可以检查当前所有没有执行完的procedure以及所有资源锁,当我们想要assign或者unassign一个region时,需要先去检查下是由有别的procedure已经占有了这个资源锁,如果是的话需要现将那个procedure bypass掉,或者等待那个procedure释放锁。
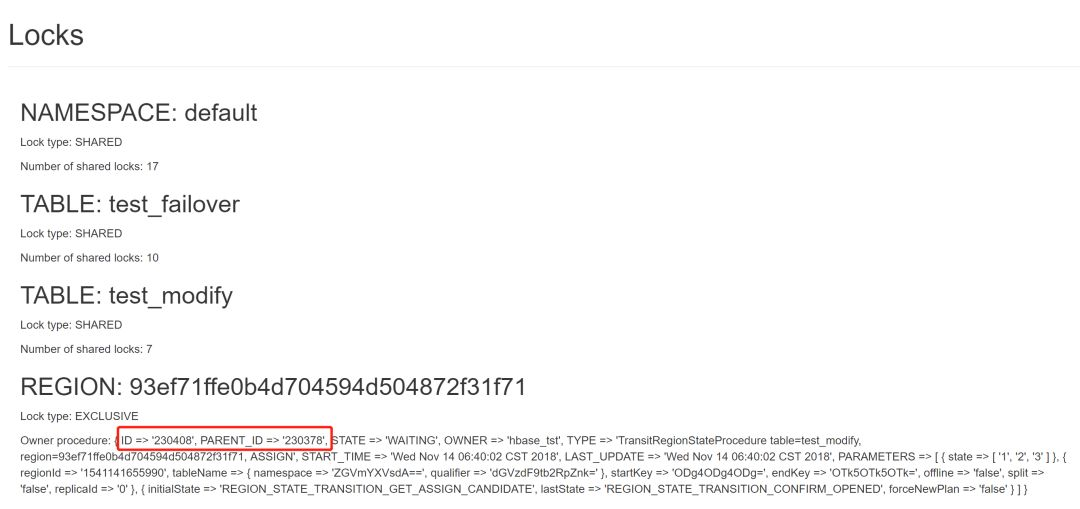
可以看到EXCLUSIVE的lock只有region级别的,图中红框圈出来的就是占有这个锁的procedure id以及它的parent procedure id, 由此我们知道如果想要重新assign/unassign这个region,那么一定要bypass这个procedure。
同理,当Locks这块没有任何EXLUSIVE锁时,我们可以放心的去执行操作而不用担心被卡住。
3、OPENING/CLOSING region的查找
branch-2.0上最容易出现的问题就是region卡在了OPENNING/CLOSING状态,一般处于这两种状态的region都会在rit的队列中,可以通过点击页面上的链接拿到所有的region以及对应的procedure id。
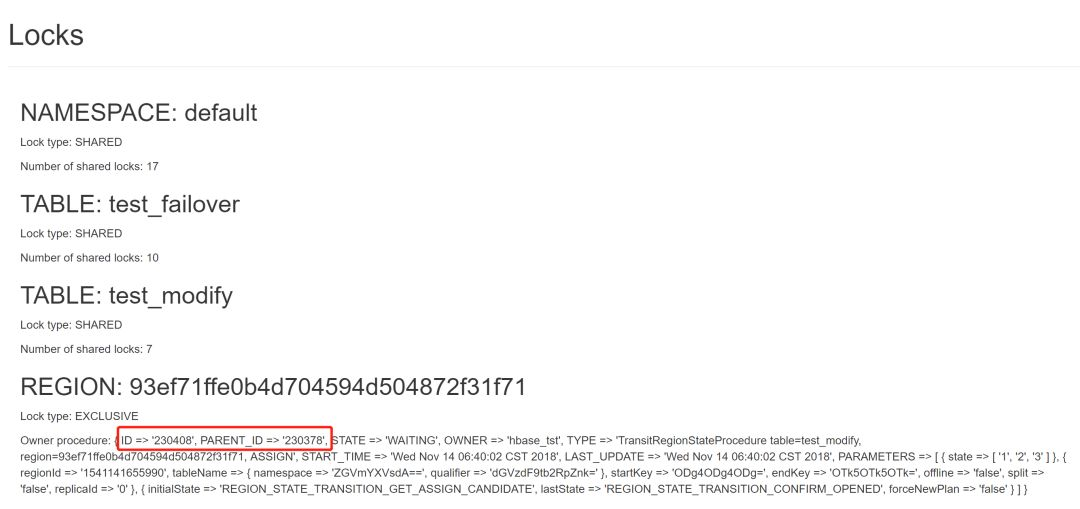
可以看到现在有17个region处在transition中,我们可以点击红框圈住的这个链接,会展示所有的region。
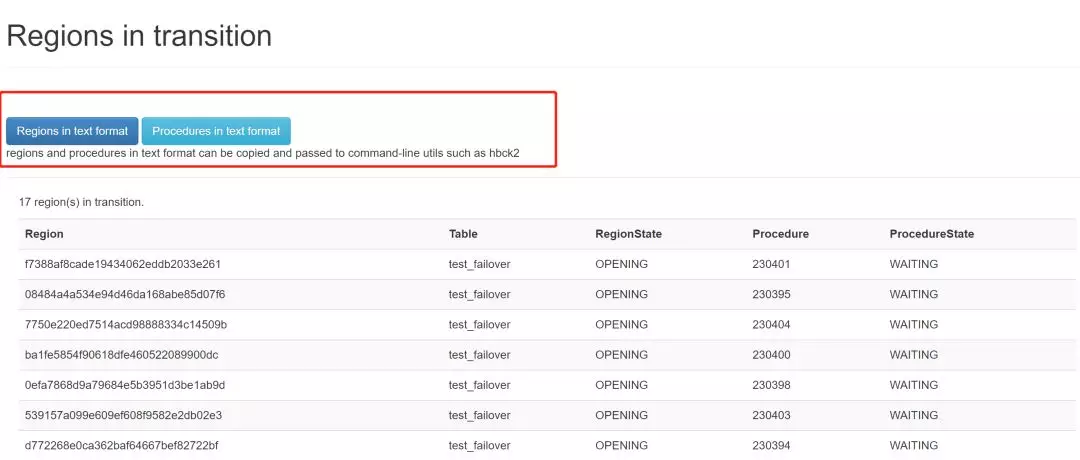
因为我们最后是希望通过HBCK2来进行处理,那么最好是可以复制粘贴需要处理的region或者procedure, 所以可以点击圈出的这两个按钮,会以text形式展示所有region或者所有procedure。

4、Master日志
stuck的region会打印以下日志:
WARN [ProcExecTimeout] org.apache.hadoop.hbase.master.assignment.AssignmentManager: STUCK Region-In-Transition rit=OPENING, location=c4-hadoop-tst-st99.bj,42900,1542148656901, table=test_modify, region=8d81f74b324d0503c3fc87f34e9a17cb
三、场景解决
1、region卡在OPENING/CLOSING 状态
首先找到这些region对应的pid, 然后执行bypass, 检查是否锁都释放了,如果释放了就再assign一遍,如果需要close,就再unassign一次
pid如截图
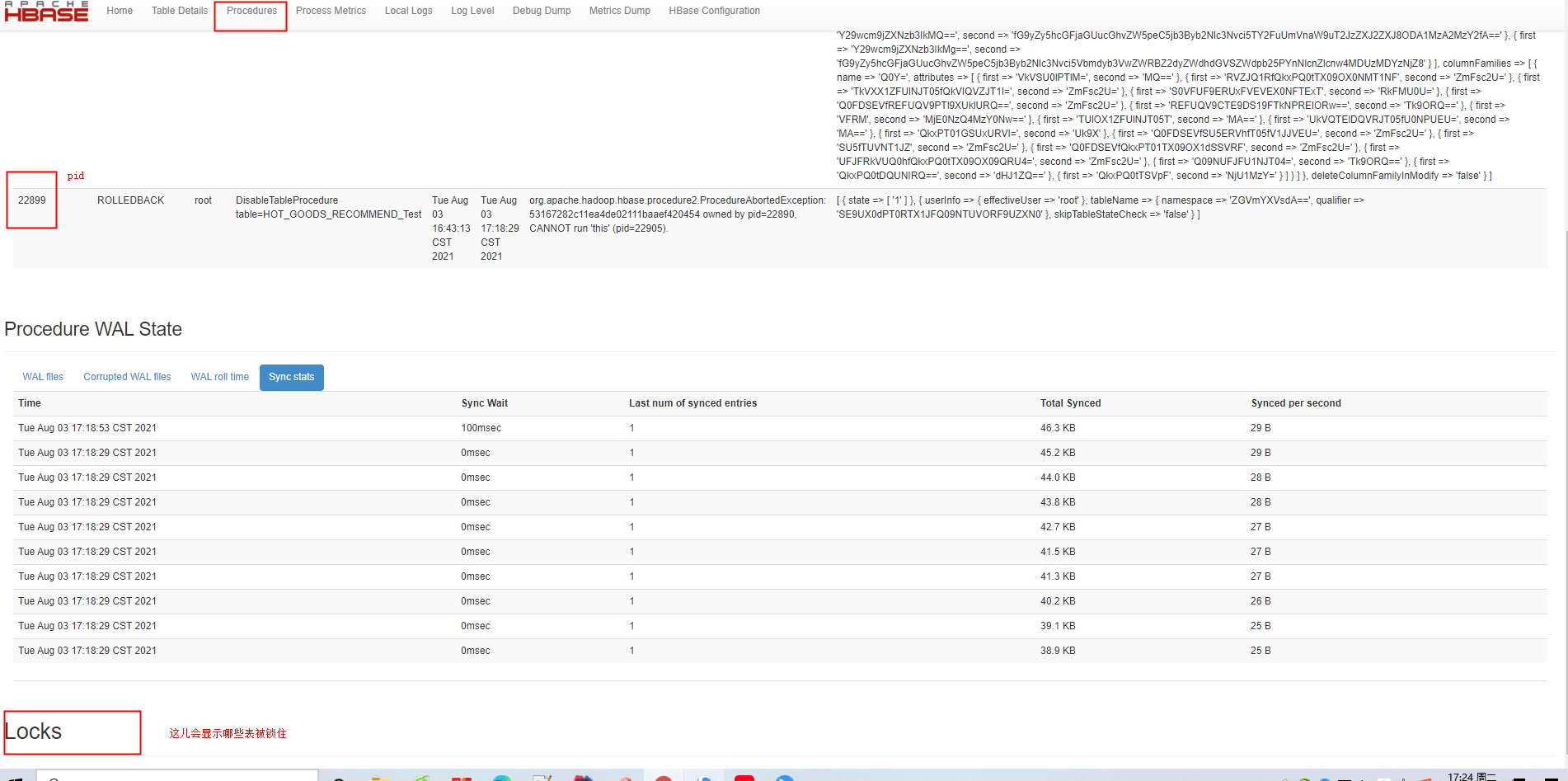
2、对table的修改有问题如何回退
找到这个修改的root procedure, bypass -or来bypass所有相关的procedure, 利用table unset来重置meta,因为bypass之后资源锁还是没有释放,所以需要手动加上override参数再去全部assigns一遍
3、Master起不起来
日志里一般会有这个:
WARN org.apache.hadoop.hbase.master.HMaster: hbase:meta,,1.1588230740 is NOT online; state={1588230740 state=CLOSING, ts=1538456302300, server=ve1017.example.org,22101,1538449648131}; ServerCrashProcedures=true. Master startup cannot progress, in holding-pattern until region onlined.
手动去assign一下meta表即可,hbase:meta表的encoded name是一个时间戳,比如上面日志的encoded name就是1588230740
另外hbase:namespace表没有online也会造成这个问题,同样需要我们去手动assign一下
table卡在disabling状态4、table卡在disabling状态
因为要求是所有region都disabled, 那么解决办法可以是手动把没有closed的region根据case1来解决。如果所有region都已经是closed状态了,那么我可以利用setTableState手动将表的状态设为DISABLED。之后再drop都是安全的了。
4.总体解决思路
-
其实HBase-2.x版本的运维思路很简单,因为使用了procedure,集群出现meta跟regionserver不一致的状态是很少的,一般都是有procedure出问题了。那么我们主要就是看怎么解决这个有问题的procedure。
-
如果是table/namespace级别的修改,因为涉及到很多region的锁,如果需要bypass的话需要找到root procedure然后使用bypass -or.
-
如果只是region级别的问题,则bypass -o即可。
-
bypass之后检查locks的页面,看看是不是锁都释放了,如果没有锁了则根据需求进行assign或者unassign,或者对table的属性进行还原。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号