


linux 安装 hadoop
一、首先jdk路径配置好,注意jdk与系统位数对应起来,一开始我安装的jdk是32位,与系统不匹配,导致像hdfs上传文件命令执行不成功。
二、hadoop安装
1)进入到 Hadoop 安装包路径下:
[root@hadoop101 ~]# cd /opt/software/
2)解压安装文件到/opt/module 下面
[root@hadoop101 software]# tar -zxf hadoop-2.7.2.tar.gz -C /opt/module/
3)查看是否解压成功
[root@hadoop101 software]# ls /opt/module/
hadoop-2.7.2
4)在/opt/module/hadoop-2.7.2/etc/hadoop 路径下配置 hadoop-env.sh
(1)Linux 系统中获取 jdk 的安装路径:
[root@hadoop101 jdk1.8.0_144]# echo $JAVA_HOME
/opt/module/jdk1.8.0_144
(2)修改 hadoop-env.sh 文件中 JAVA_HOME 路径:
[root@hadoop101 hadoop]# vi hadoop-env.sh
修改 JAVA_HOME 如下
export JAVA_HOME=/opt/module/jdk1.8.0_144
5)将 hadoop 添加到环境变量
(1)获取 hadoop 安装路径:
[root@ hadoop101 hadoop-2.7.2]# pwd
/opt/module/hadoop-2.7.2
(2)打开/etc/profile 文件:
[root@ hadoop101 hadoop-2.7.2]# vi /etc/profile
在 profie 文件末尾添加 jdk 路径:(shitf+g)
##HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-2.7.2
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
(3)保存后退出:
:wq
(4)让修改后的文件生效:
[root@ hadoop101 hadoop-2.7.2]# source /etc/profile
(5)重启(如果 hadoop 命令不能用再重启):
[root@ hadoop101 hadoop-2.7.2]# sync
[root@ hadoop101 hadoop-2.7.2]# reboot
6)修改/opt 目录下的所有文件所有者为 atguigu
[root@hadoop101 opt]# chown atguigu:atguigu -R /opt/
7)切换到 atguigu 用户
[root@hadoop101 opt]# su atguigu
Hadoop 运行模式
1)官方网址
(1)官方网站:
http://hadoop.apache.org/
(2)各个版本归档库地址
https://archive.apache.org/dist/hadoop/common/hadoop-2.7.2/
(3)hadoop2.7.2 版本详情介绍
http://hadoop.apache.org/docs/r2.7.2/
2)Hadoop 运行模式
(1)本地模式(默认模式):
不需要启用单独进程,直接可以运行,测试和开发时使用。
(2)伪分布式模式:
等同于完全分布式,只有一个节点。
(3)完全分布式模式:
多个节点一起运行。
本地运行 Hadoop 案例
官方 grep 案例
1)创建在 hadoop-2.7.2 文件下面创建一个 input 文件夹
[atguigu@hadoop101 hadoop-2.7.2]$mkdir input
2)将 hadoop 的 xml 配置文件复制到 input
[atguigu@hadoop101 hadoop-2.7.2]$cp etc/hadoop/*.xml input
3)执行 share 目录下的 mapreduce 程序
[atguigu@hadoop101 hadoop-2.7.2]$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar grep input output 'dfs[a-z.]+'
4)查看输出结果
[atguigu@hadoop101 hadoop-2.7.2]$ cat output/*
官方 wordcount 案例
1)创建在 hadoop-2.7.2 文件下面创建一个 wcinput 文件夹
[atguigu@hadoop101 hadoop-2.7.2]$mkdir wcinput
2)在 wcinput 文件下创建一个 wc.input 文件
[atguigu@hadoop101 hadoop-2.7.2]$cd wcinput
[atguigu@hadoop101 wcinput]$touch wc.input
3)编辑 wc.input 文件
[atguigu@hadoop101 wcinput]$vim wc.input
在文件中输入如下内容
hadoop yarn
hadoop mapreduce
atguigu
atguigu
保存退出::wq
4)回到 hadoop 目录/opt/module/hadoop-2.7.2
5)执行程序:
[atguigu@hadoop101 hadoop-2.7.2]$ hadoop jar
share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount wcinput wcoutput
6)查看结果:
[atguigu@hadoop101 hadoop-2.7.2]$cat wcoutput/part-r-00000
atguigu 2
hadoop 2
mapreduce 1
yarn 1
伪分布式运行 Hadoop 案例
启动 HDFS 并运行 MapReduce 程序
1)分析:
(1)准备 1 台客户机
(2)安装 jdk
(3)配置环境变量
(4)安装 hadoop
(5)配置环境变量
(6)配置集群
(7)启动、测试集群增、删、查
(8)执行 wordcount 案例
2)执行步骤
需要配置 hadoop 文件如下
(1)配置集群
(a)配置:hadoop-env.sh
Linux 系统中获取 jdk 的安装路径:
[root@ hadoop101 ~]# echo $JAVA_HOME
/opt/module/jdk1.8.0_144
修改 JAVA_HOME 路径:
export JAVA_HOME=/opt/module/jdk1.8.0_144
(b)配置:core-site.xml
<!-- 指定 HDFS 中 NameNode 的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop101:9000</value>
</property>
<!-- 指定 hadoop 运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-2.7.2/data/tmp</value>
</property>
(c)配置:hdfs-site.xml
<!-- 指定 HDFS 副本的数量 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
(2)启动集群
(a)格式化 namenode(第一次启动时格式化,以后就不要总格式化)
[atguigu@hadoop101 hadoop-2.7.2]$ bin/hdfs namenode -format
(b)启动 namenode
[atguigu@hadoop101 hadoop-2.7.2]$ sbin/hadoop-daemon.sh start namenode
(c)启动 datanode
[atguigu@hadoop101 hadoop-2.7.2]$ sbin/hadoop-daemon.sh start datanode
(3)查看集群
(a)查看是否启动成功
[atguigu@hadoop101 hadoop-2.7.2]$ jps
13586 NameNode
13668 DataNode
13786 Jps
(b)查看产生的 log 日志
当前目录:/opt/module/hadoop-2.7.2/logs
[atguigu@hadoop101 logs]$ ls
hadoop-atguigu-datanode-hadoop.atguigu.com.log
hadoop-atguigu-datanode-hadoop.atguigu.com.out
hadoop-atguigu-namenode-hadoop.atguigu.com.log
hadoop-atguigu-namenode-hadoop.atguigu.com.out
SecurityAuth-root.audit
[atguigu@hadoop101 logs]# cat hadoop-atguigu-datanode-hadoop101.log
(c)web 端查看 HDFS 文件系统
http://192.168.1.101:50070/dfshealth.html#tab-overview
注意:如果不能查看,看如下帖子处理
http://www.cnblogs.com/zlslch/p/6604189.html
(4)操作集群
(a)在 hdfs 文件系统上创建一个 input 文件夹
[atguigu@hadoop101 hadoop-2.7.2]$ bin/hdfs dfs -mkdir -p /user/atguigu/input
(b)将测试文件内容上传到文件系统上
[atguigu@hadoop101 hadoop-2.7.2]$ bin/hdfs dfs -put wcinput/wc.input
/user/atguigu/input/
(c)查看上传的文件是否正确
[atguigu@hadoop101 hadoop-2.7.2]$ bin/hdfs dfs -ls /user/atguigu/input/
[atguigu@hadoop101 hadoop-2.7.2]$ bin/hdfs dfs -cat /user/atguigu/
input/wc.input
(d)运行 mapreduce 程序
[atguigu@hadoop101 hadoop-2.7.2]$ bin/hadoop jar
share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /user/atguigu/input/
/user/atguigu/output
(e)查看输出结果
命令行查看:
[atguigu@hadoop101 hadoop-2.7.2]$ bin/hdfs dfs -cat /user/atguigu/output/*
浏览器查看
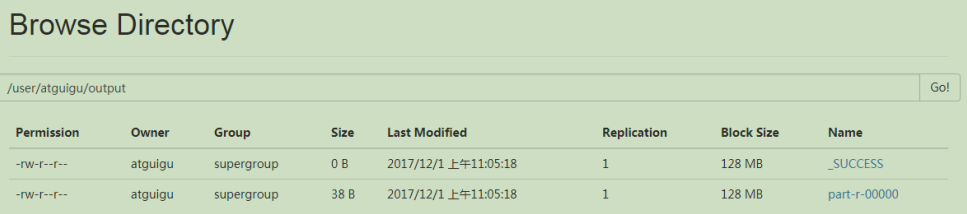
(f)将测试文件内容下载到本地
[atguigu@hadoop101 hadoop-2.7.2]$ hadoop fs
-get /user/atguigu/
output/part-r-00000 ./wcoutput/
或者执行
bin/hdfs dfs -get /user/hejj1/output/p* wcinput/
(g)删除输出结果
[atguigu@hadoop101 hadoop-2.7.2]$ hdfs dfs -rm -r /user/atguigu/output
三、hadoop运行模式

本地运行 Hadoop 案例
官方 grep 案例
官方 wordcount 案例
伪分布式运行 Hadoop 案例
启动 HDFS 并运行 MapReduce 程序
1)分析:
(1)准备 1 台客户机
(2)安装 jdk
(3)配置环境变量
(4)安装 hadoop
(5)配置环境变量
(6)配置集群
(7)启动、测试集群增、删、查
(8)执行 wordcount 案例


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· winform 绘制太阳,地球,月球 运作规律
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· AI 智能体引爆开源社区「GitHub 热点速览」
· 写一个简单的SQL生成工具