


windows 安装hadoop
1.首先安装jdk
下载jdk解压包,配置环境变量
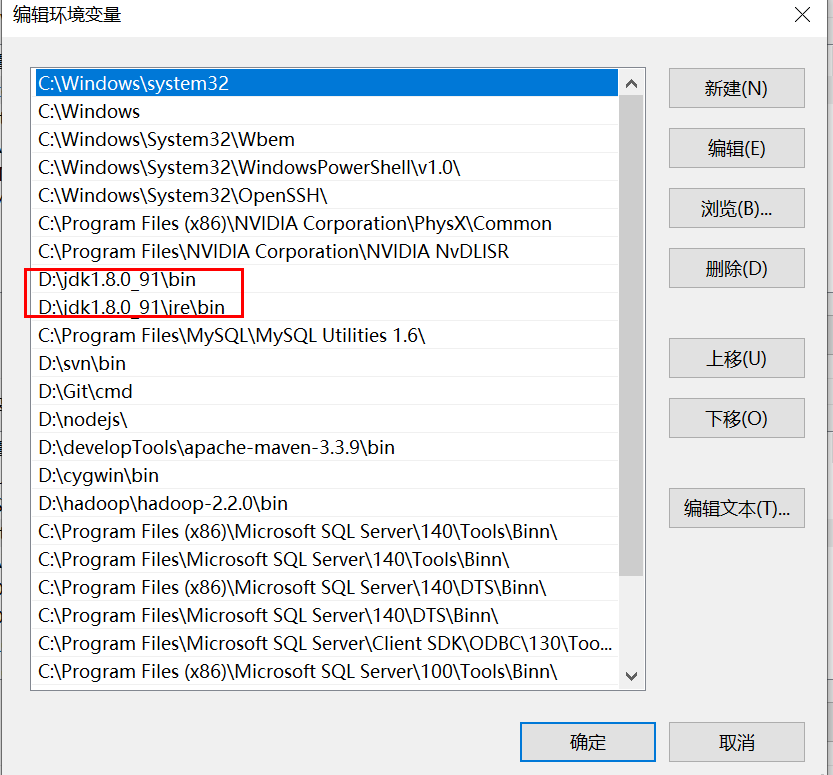
配置变量名JAVA_HOME,变量值: D:\jdk1.8.0_91

配置变量名CLASSPATH, 变量值.;%JAVA_HOME%\lib\dt.jar;%JAVA_HOME%\lib\tools.jar;
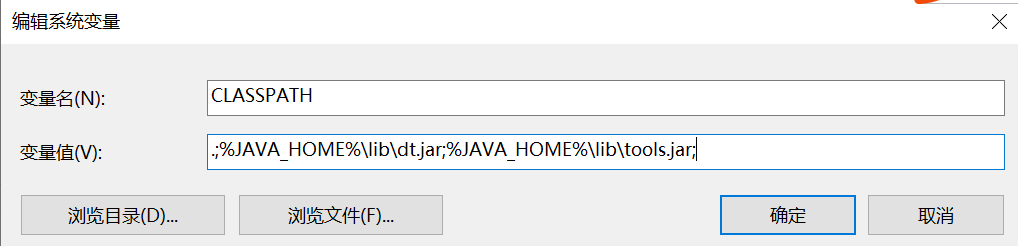
win10需要写真实路径,用%JAVA_HOME%,重新开机后jdk设置无效。
2.下载hadoop(由于之前用的2.2.0,所以此次下载的还是2.0)
Apache的hadoop下载地址
地址:https://archive.apache.org/dist/hadoop/common/
CDH的hadoop下载地址
地址:http://archive.cloudera.com/cdh5/cdh/5/
3、配置hadoop环境变量
变量名:HADOOP_HOME ,变量值:D:\hadoop\hadoop-2.2.0

下载完,发现没有hadoop.dll和winutils.exe,之前搭建hbase的时候,有下载一个hadoop-common-2.2.0-bin-master,里面包含这两个文件,直接拷贝进去就可以,一开始不知道要拷贝,一直报以下错误,windows本地运行mr程序时(不提交到yarn,运行在jvm靠线程执行),hadoop.dll防止报nativeio异常、winutils.exe没有的话报空指针异常,此外,还应该将hadoop.dll拷贝到c:/windows/System32,否则启动也会报错。
winutils.exe下载地址:
https://github.com/4ttty/winutils
hadoop-env.cmd文件中设置jdk路径,正常情况如下,有的博客说要设置成D:\jdk1.8.0_91这样的路径,但是不改也可以。
set JAVA_HONE=%JAVA_HONE%,
4.设置hadoop配置文件,路径:D:\hadoop\hadoop-2.2.0\etc\hadoop
core-site.xml


<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/hadoop/data/dfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/hadoop/data/dfs/datanode</value>
</property>
</configuration>
mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
5、进入bin目录,执行下面2条命令,先格式化namenode再启动hadoop
格式化:hadoop namenode -format
进入sbin目录然后启动:start-all.cmd
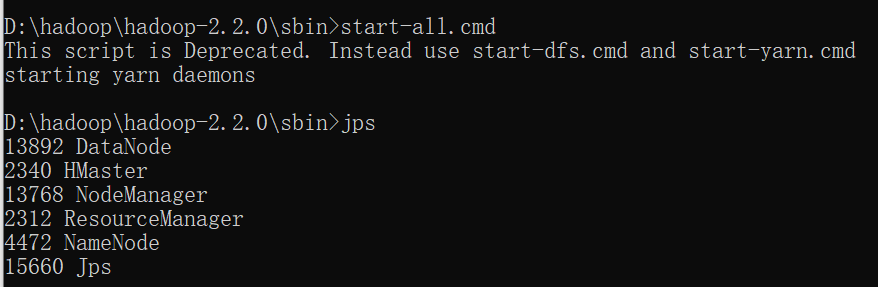
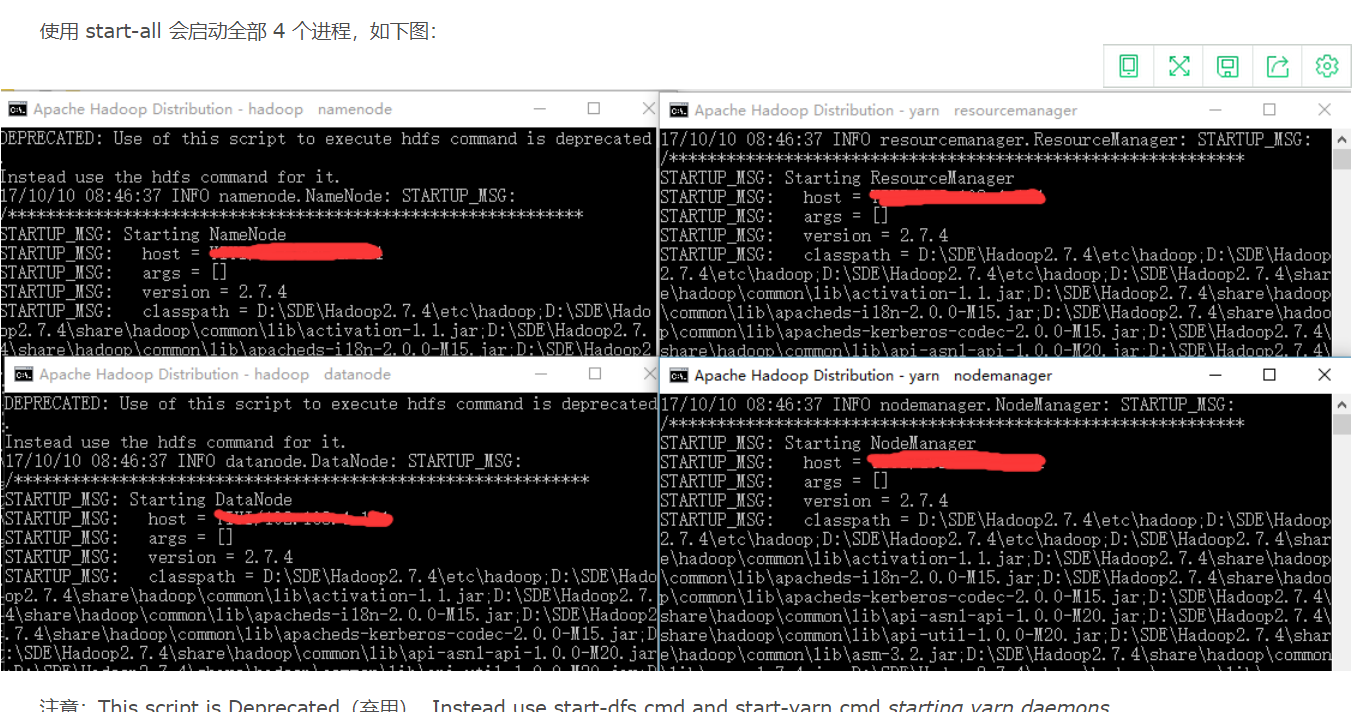
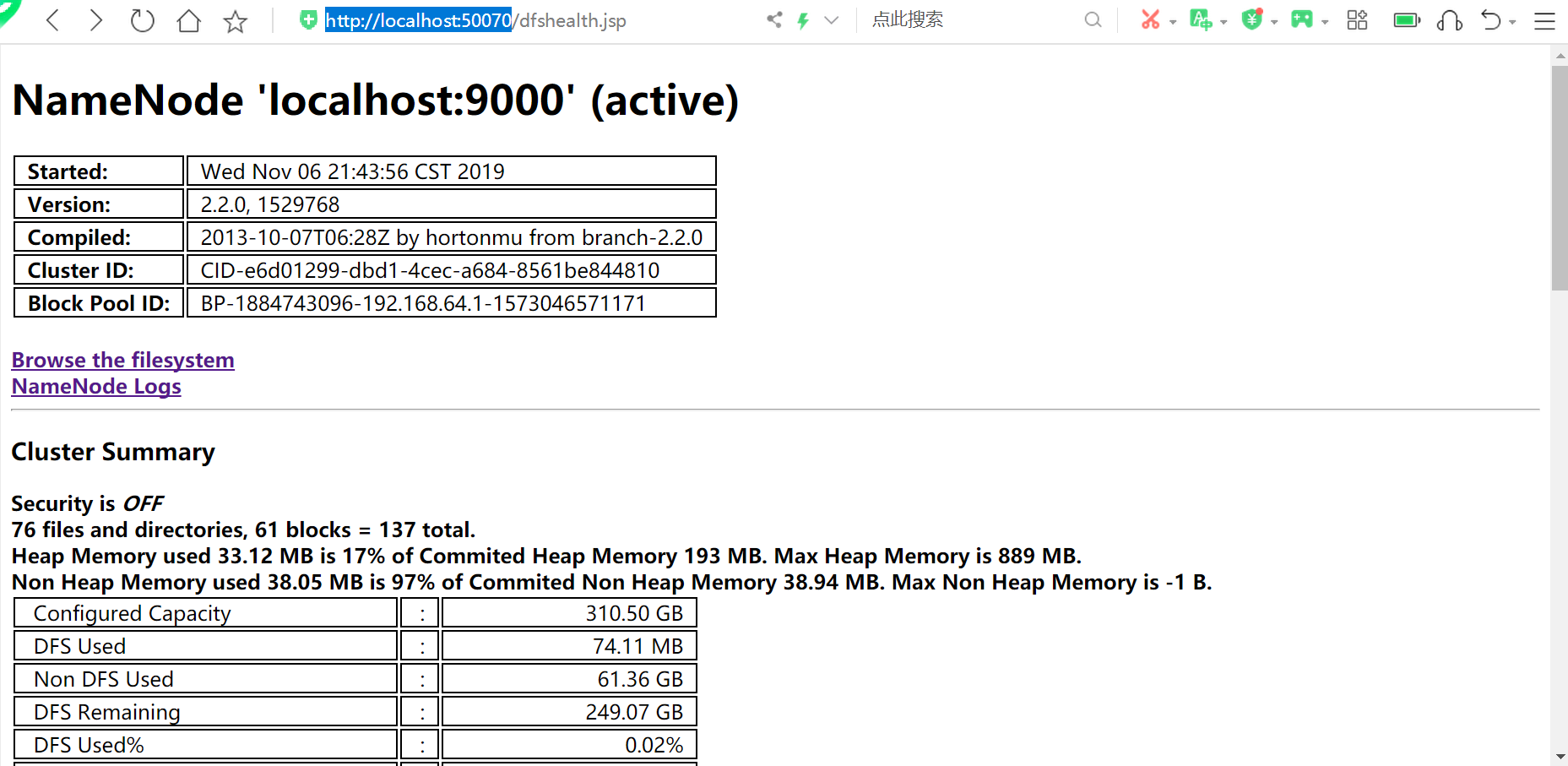
通过jps命令可以看到4个进程都拉起来了,到这里hadoop的安装启动已经完事了。接着我们可以用浏览器到localhost:8088看mapreduce任务,到localhost:50070->Utilites->Browse the file system看hdfs文件。如果重启hadoop无需再格式化namenode,只要stop-all.cmd再start-all.cmd就可以了。
上面拉起4个进程时会弹出4个窗口,我们可以看看这4个进程启动时都干了啥:
访问http://localhost:8088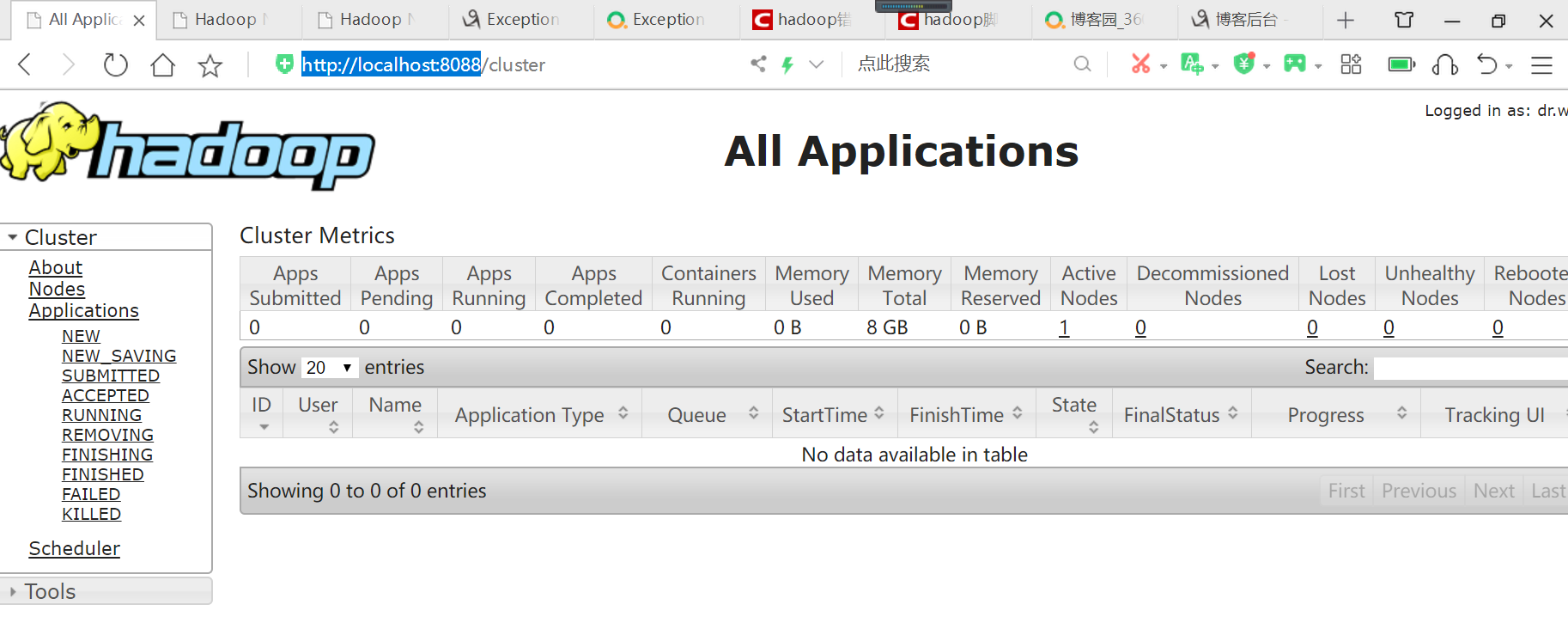
访问http://localhost:50070
到此,Hadoopan安装完毕,
参考博客:https://www.cnblogs.com/xinaixia/p/7641612.html
参考博客:https://www.cnblogs.com/wuxun1997/p/6847950.html
目前还存在一个问题,hbase 中使用mapreduce 统计表命令时,一开始缺少dll文件一直报nativeIO,有人说去改hadoop-common的jar包底下的nativeIO类,试过了没有用,hadoop bin中加了dll文件之后,报下面的错误,目前还没有解决,猜测是mapred-site.xml这个文件需要新增属性配置。
统计命令:hbase org.apache.hadoop.hbase.mapreduce.RowCounter 表名称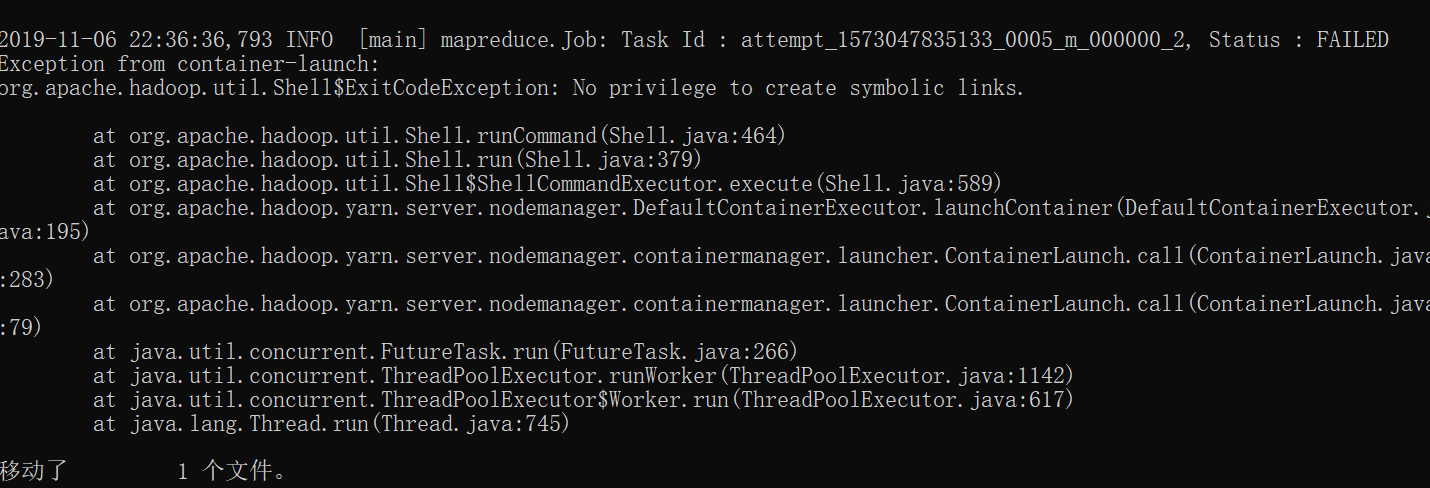


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· winform 绘制太阳,地球,月球 运作规律
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· AI 智能体引爆开源社区「GitHub 热点速览」
· 写一个简单的SQL生成工具