大四学生的前端知识点面试学习记录
前端面试学习
开始于2021年3月17日。最后编辑于2022年3月20日
JavaScript基础
数据类型
基本类型:null、undefined、boolean、number、string、symbol、bigInt 、引用类型:object
-
当对字符串进行parseInt转换等其他转换时,返回的
NaN(NaN属于number)跟另一个字符串转换获得的NaN进行比较时会返回false。因'A'不是一个数字 ,'B'也不是一个数字,无法证明两者一样的!所以要用isNaN()方法来判断。NaN互不相等 -
JavaScript 能够准确表示的整数范围在
-2^53到2^53之间 -
栈去存放变量和其值。基本类型是它真实的值,引用类型保存的是对象在堆中的地址值。所以对基本类型比较时是比较实际的值。对引用类型(Object)比较的时候则是比较地址值,赋值也是赋值在堆区中的地址值。js是值传递
let a={}, b=a, c={}; console.log(`${a===b},${a==c}`); // true,false -
js跟java一样也有包装类型,如boolean->Boolean,number->Numbe类比java里的int->Integer,boolean->Boolean。当对基本类型调用方法或者获取属性时,会隐式的创建一个包装类,用完就销毁。 自动包装和拆箱
var str = 1; str.pro = 2; console.log(str.pro + 10); // NaN -
明白对象赋值是传递引用。对象深浅拷贝的问题就解决了,浅拷贝只拷贝对象里的第一层。
-
使用
typeof可以查看其属于的类型是什么,数组[]也是object哦,函数会返回function。typeof null返回object←历史遗留问题,因为js引擎对二进位前三位都为0就判为object,恰好null全0。(可以改,但没必要) -
对于Boolean的转换,除了
undefined,null,false,NaN,'',0,-0,其他所有值都转为true,包括所有对象。 -
Symbol最主要是用来定义一个独一无二的属性名,来避免重名和不被迭代
Symbol是ES6引入新的基础类型,类似唯一标识ID,通过
Symbol()来创建实例Symbol可以作为对象的键,且在序列化,Object.keys()或者for...in来枚举都不会被包含进去
所以还可以使用Symbol来定义类的私有属性/方法。
常见的代表了内部语言行为的Symbol,以此实现更高级的操作:
Symbol.iterator被for...of使用,需要满足迭代协议,参见GeneratorSymbol.toPrimitive将对象转化为基本数据类型的方法 ,这样对象就能作为基本数据类型操作Symbol.toStringTag被Object.prototype.toString()使用,相当于类型标签。比如Map Set等实例带有该属性 -
判断方法:typeof、instanceof、construtor、isPrototypeOf()、Object.getPrototypeOf() 、Object.prototype.toString.call() 类型、原型判断
原型和原型链
👈有名的js原型图
精简版
-
js通过原型和原型链来实现类似继承的机制。
在Java中可以使用Cat cat=new Cat(); cat.eat(); 调用属于类的方法也可以使用Cat.eat()直接调用。由于js的动态语言特性,可以在'类'中增加方法和属性。让其'实例对象'都可以调用到这个方法。同时继承也让'实例对象'知道它爹是谁。
-
只要是函数,其__proto__上一定找得到 Function.prototype
-
只要是对象,其__proto__上一定找得到 Object.prototype
- Object.prototype的__proto__是
null,代表原型链的终点
- Object.prototype的__proto__是
-
使用关键字function声明函数有
prototype属性,箭头函数创建的函数没有prototype属性const fun4 = (){ console.log('is func4!') } fun4(); // is func4 console.log(fun4.prototype); // undefined -
Function.prototype和Object.prototype是两个特殊的对象,它们由引擎来创建 -
除了以上两个特殊对象,其他对象都是通过构造器函数
new出来的 -
函数的
prototype是一个对象,也就是所说的原型 -
对象的
__proto__指向原型,__proto__将对象和原型连接起来组成了原型链 -
所有引用类型的
_proto_属性指向它构造函数的prototype -
Function.[[Prototype]] === Function.prototype; // true
-
Object.prototype是浏览器底层根据
ECMAScript规范创造的一个对象。
// TODO extends
面试问答:解释下原型和原型链?
原型的存在组成原型链,原型链将原型串起来,以此实现继承机制。proto就串起原型链的桥梁。当试图访问一个对象的属性时,它不仅仅在该对象上搜寻,还会通过原型链上搜寻。
原型(prototype):每个对象拥有一个原型对象,对象以其原型为模板、从原型继承方法和属性。
关键字new
-
使用
new FunctionName();来创建对象发生四件事:创建一个对象、链接到原型、绑定this、返回新对象 -
创建对象最好还是用字面量的方式
const a = { b: 1 }方法来创建,可读性高,性能好。 -
new内部默认返回this,如果手动返回一个引用类型则不会返回this,返回基本类型不生效
function _new(constructor,...args) { const obj = new Object() // 创建空对象 obj.__proto__ = constructor.prototype // 链接到原型 const result = constructor.call(obj, ...args) // 绑定this 执行构造函数 return typeof result === 'object' ? result : obj // 确保 new 出来的是个对象 }
关键字instanceof
-
判断对象的类型,通过判断其原型链上是否能找到类型(构造函数)的
prototypefunction _instanceOf(left/* 实例 */, right/* 类型 */) { while (true) { if (left === null) return false; // 遍历到原型链的尽头时结束查找 if (Object.getPrototypeOf(left) === right.prototype) return true; // 比较left.__proto__ 和 right.prototype left = left.__proto__; } } console.log(_instanceOf([], Array)) // true
关键字this
官方中文文档指路
https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Reference/Operators/this
- this是一个执行上下文(context)的属性,函数的调用方式决定了
this的值(运行时绑定) - 箭头函数不提供自身的 this 绑定(
this的值将保持为闭合词法上下文的值) - 可以用call、apply、bind可以改变函数的this指向 (对箭头函数无效)
- 在严格模式下,函数被直接调用(不作为对象的方法)时this为
undefined - 在非严格模式下,函数被直接调用(不作为对象的方法)时this为
window - 当一个函数用作构造函数时(使用new关键字)this为正在构造的新对象
- 定时器、立即执行函数的this为
window,事件绑定的为绑定事件的对象
var obj = {
bar() { // bar函数返回一个箭头函数,该箭头函数将返回this
return () => this ;
}
};
----babel: es5↓----
var obj = {
bar: function bar() {
var _this = this;
return function () {
return _this;
};
}
};
关键字var、let、const
- let跟const差不多,都是块级作用域,不能重复定义,不能再被声明前使用,存在暂时性死区。
- const不能更改值且必须定义时就赋初值
- 在变量提升的过程中,相同名的函数会覆盖上一个,且函数优先于变量提升
function f() {
console.log(tmp);
if (false) {
var tmp = 'hello world'; // 会导致内层变量会覆盖外层变量(变量提升的原因)
}
}
f(); // undefined
// ==循环陷阱问题==
for (var i = 0; i < 3; i++){}
关键字class
- 函数声明和类声明之间的一个重要区别在于, 函数声明会提升,类声明不会。
class Dog{
eat(){ console.log('eating shit!')}
}
// ==babel编译结果,剔除非关键代码==
var Dog = function() {
'use strict';
// 调用 constructor
function Dog() {
}
// 该函数作用:在其原型对象或者构造函数上(静态方法)添加属性
_createClass(Dog, [
{
key: 'eat',
value: function eat() {
console.log('shit');
},
}]);
return Dog;
}();
题目:下面这个 class 的四个属性分别属于这个 class 的什么,fn 和 f 有什么区别 (babel在线编一下就知道了)
class A {
static a = 1;
b = 2;
fn() {console.log(this)}
f = () => {console.log(this)};
}
相等 (==)
在两个操作数是不同类型会尝试转换成相同类型
- 数字和字符串比,尝试字符串转成数字 |
0 == '' // true - 有一个是Bool值,则将Bool值换成数字 |
false == 0 // true - 有一个是对象,则尝试使用对象的
valueOf()和toString()
Number和Number的比较:+0和-0视为相同值,NaN和NaN返回false
[] == false ?
- 应用规则2=>
[] == 0; - 对象类型会转换为其原始值=>
[].valueOf().toString() = '' '' == 0,''被转换为数字于0比较Number('') == 0
作用域
当创建函数时,该函数的作用域便已经声明,为所处的上下文,
函数中查找变量的过程中形成的链条就叫作用域链(当前作用域没查到就会向上一级作用域查找)
箭头函数
不能用new 、不绑定arguments、new.target 、 不绑定this、没有prototype属性
函数对象是一个支持[[Call]]、[[Construct]]内部方法的对象,不过箭头函数没有[[Construct]],所以不能new对象
闭包
有句话叫做:闭包是懒人的对象,对象是天然的闭包。闭包让无状态的函数有了状态,可以记录函数用到的变量。
-
闭包的产生条件:函数嵌套且嵌套的函数必须引用外部函数定义的变量/函数(不准确)
每一个函数都会产生闭包,无论 闭包中是否存在内部函数 或者 内部函数中是否访问了当前函数变量 又或者 是否返回了内部函数,因为闭包在当前函数预编译阶段就已经创建了。
-
不过闭包对于变量的引用,让引用类型一直被引用,无法被GC,若使用不当会导致内存泄漏的问题
-
基本类型存放: https://www.zhihu.com/question/482433315/answer/2083349992
// 供参考,VOAO的概念已被LE词法环境(Lexical environment)代替 var a = 1; function foo() { // foo函数在创建时也会创建一个内部的VO(变量对象):{ b:2; innerFoo:<函数地址引用> } // 同时建立作用域链,对外层的VO链接起来,这样就能够读取到变量 a var b = 2; return function innerFoo() { console.log(a,b); } } const foo1=foo(); foo1(); //1,2 因为闭包,函数innerFoo记录了他的上下文。b被引用了,就不被释放。(当前作用域产生对父作用域的引用) -
使用场景:能访问函数定义时所在的词法作用域,让变量私有化(防抖节流等),模拟块级作用域、函数懒执行(比如实现柯里化和反柯里化)、
深入理解:
- js引擎会分析子函数对父函数的LE中变量的使用,然后存到闭包对象中,然后这个闭包代替父函数的LE出现在其
[[Scopes]]中 - 闭包对象在当前函数预编译时确定,所有子函数使用同一个闭包对象
- 闭包相比outer链路,通过分析使用以减少内存使用代价
模块化
ES Modules就ES6才有的,静态导入、动态引用、导入导出的值都指向同一个内存地址CommonJs是 Node 独有的规范,浏览器不能直接用,动态导入- [javascript模块化演进及原理浅析] https://juejin.cn/post/6940163713345257486
CommonJs是动态的,提供了exports(导出) 和 require(导入) 两个属性。并在在运行时才确定引入然后再执行这个模块(相当于函数调用)。导出值是拷贝。this指向当前模块
// 以Webpack打包后的代码举例: 重写后的 require 函数
function __webpack_require__(moduleId) {
// 如果已经在缓存中,使用缓存
if (__webpack_module_cache__[moduleId]) {
return __webpack_module_cache__[moduleId].exports;
}
// cjs中的 module.exports 是长这样的
var module = (__webpack_module_cache__[moduleId] = { exports: {}/*默认值*/ });
// 原文件的require、module、exports(module.exports 的引用)被重写,既函数参数
__webpack_modules__[moduleId](module, module.exports, __webpack_require__);
return module.exports;
}
ES6 Module是静态的。是在代码正式运行前执行(编译阶段确定,只能写在头部,利于tree shaking)。导出的是值的内存的地址的引用(不能更改,相当于用const定义),this指向undefined
node中利用包装函数,为js文件执行时提供相应变量
function wrapper (script) {
return '(function (exports, require, module, __filename, __dirname) {'
+ script +
'\n})'
}
Promise
Promise 对象用于表示一个异步操作的最终完成 (或失败)状态及其结果值(MDN)
-
Promise让异步函数原来的回调函数处理变成链式处理
.then().then() ...,上一个处理完交给下一个then() -
一个promise可以接收多个then,每个then都返回一个新的Promise对象
-
Promise.prototype.catch(()=>{}) 等于 Promise.prototype.then(undefined,()=>{})
-
Promise.rejected有传递机制,会不断向下传递直到遇见
onRejected处理函数当一个没有绑定处理函数的 Promsie 被调用 reject 则会创建一个 微任务来再次检测这个 Promise 是否存在处理函数,如果此时还不存在则输出报错
-
内部有3个状态,未完成(用于收集依赖),成功和失败(将then/catch中的回调函数加入任务队列)
-
then的
onFulfilled可以返回一个thenable对象(包含then方法的任意对象)let p2 = Promise.resolve().then(() => { console.log(0); let p3 = Promise.resolve(4) return p3; })p2要达到Fulfilled,会先创建一个微任务并推入队列,然后当该任务被执行再调用p3.then()
microtask(() => { p3.then((value) => { ReslovePromise(p2, value) }) // 再次加入微任务队列 }) // https://juejin.cn/post/7055202073511460895#heading-30 -
手写 Promise类之内部重要组成部分
-
当前Promise实例的状态 'Pending' 'Fulfilled' 'Rejected' 三种之一 (转变后不能再转变)
-
当前Promise接受构造器执行完的结果 result,(作为依赖的参数值)
-
then方法传入的回调函数的队列 resolveQueue [] & rejectQueue []
-
改变Promise实例的状态的函数 _resolve & _reject,(调用收集的依赖,放入微任务队列)
-
-
Promise静态方法四兄弟
- Promise.all接收多个Promise实例,都成功时,返回结果数组(被then接收),当有一个失败时,发生短路返回第一个失败的实例(被catch接收)
- Promise.race接收多个实例,最先做完的被返回,是成功就被then接收,是失败就被catch接收
- Promise.allSettled都做完再执行成功回调
- Promise.any跟all相反,都失败了reject,一个成功就fulfiled
- all和race都具有短路特性,all有一个失败就reject,race参数中某个
promise解决或拒绝,返回的 promise就会解决或拒绝。
async&await
在ES2017中被定义
-
async关键字用来定义异步函数,该函数必定返回一个Promse对象。 -
await关键字用来在异步函数中等待一个Promise对象的结果。代替.then()的写法。 -
async和await是Generator 函数的语法糖 ,await跟yield命令作用一样。await必须在async函数的上下文中 -
异步函数体内有一个await表达式,async函数就一定会异步执行
async function foo() { await 1 } // 等价于 function foo() { return Promise.resolve(1).then(() => undefined) }
Generator
-
Generator 是 ES6 中新增的语法,和 Promise 一样,都可以用来异步编程
// 使用 * 表示这是一个 Generator 函数 // 内部可以通过 yield 暂停代码,并 声明内部状态的值 // 通过调用 next 恢复执行 function* test() { let a = 1 + 2; yield 2; yield 3; } let b = test(); console.log(b.next()); // > { value: 2, done: false } console.log(b.next()); // > { value: 3, done: false } console.log(b.next()); // > { value: undefined, done: true } -
从以上代码可以发现,加上
*的函数执行后拥有了next函数,也就是说函数执行后返回了一个对象。每次调用next函数可以继续执行被暂停的代码。 -
Generator函数内部遇到yield命令,那么就不往下执行了,就把执行权交出来给别的函数。别的函数做完,返还执行权后才继续执行。
Proxy
用来代理一个对象,通过Proxy可以轻松监视到对象的读写过程。
Reflect
Reflect 可以用于获取目标对象的行为,它与 Object 类似,它的方法与 Proxy 是对应的。
Map&Set
map和Object的区别 事件订阅用Map不错
来源:https://juejin.cn/post/6940945178899251230#heading-37
| Map | Object | |
|---|---|---|
| 意外的键 | Map默认情况不包含任何键,只包含显式插入的键。 | Object 有一个原型, 原型链上的键名有可能和自己在对象上的设置的键名产生冲突。 |
| 键的类型 | 任意类型 (any) | Object 的键必须是Number、 String 或Symbol |
| 键的顺序 | Map 中的 key 是有序的。因此,当迭代的时候, Map 对象以插入的顺序返回键值。 | 1. 数值键(升序) 2. 字符串键(加入时间升序) 3. symbol(加入时间升序) |
| Size | Map 的键值对个数可以轻易地通过size 属性获取 | Object 的键值对个数只能手动计算 |
| 迭代 | Map 是 iterable 的,所以可以直接被迭代。 | 迭代Object需要以某种方式获取它的键然后才能迭代。 |
| 性能 | 在频繁增删键值对的场景下表现更好。 | 在频繁添加和删除键值对的场景下未作出优化。 |
- 如果需要遍历键值对,并且考虑顺序,优先考虑 Map
- Map是纯Hash结构,对频繁增删键值对的场景表现更好
Set 对象允许你存储任何类型的唯一值,无论是原始值或者是对象引用。
map和weakMap区别:1. 只接受对象作为键 2. 键值任意类型 3. 不能遍历 4. 对键名是弱引用
XMLHttpRequest
const xhr = new XMLHttpRequest();
xhr.open("post", "http://localhost:8080/api/test");
xhr.setRequestHeader("Content-type", "application/json");
xhr.send(JSON.stringify({a: 1, b: 2 }));
xhr.onreadystatechange = function(){
if(xhr.status==200 && xhr.readyState==4){
let result=xhr.responseText;//获取到结果
alert(result);
}
}
XMLHttpRequest.status是标准的HTTP status codes,举个例子,status 200 代表一个成功的请求
- UNSENT(未发送) 0
- OPENED(已打开) 0
- LOADING(载入中) 200
- DONE(完成) 200
XMLHttpRequest.readyState是XMLHttpRequest 代理当前所处的状态。其取值如下:
| 值 | 状态 | 描述 |
|---|---|---|
0 |
UNSENT |
代理被创建,但尚未调用 open() 方法。 |
1 |
OPENED |
open() 方法已经被调用。这时候可设置请求头。 |
2 |
HEADERS_RECEIVED |
send() 方法已经被调用,并且头部和状态已经可获得。 |
3 |
LOADING |
响应体部分正在被接收。 |
4 |
`DONE | 请求操作已经完成。这意味着数据传输已经彻底完成或失败。 |
ajax!=XHR ajax是一种概念,XHR是基于浏览器是一种实现
fetch和XHR的区别
- fetch更加语义化和简洁、基于Promise实现、更加底层
- fetch不能检测请求进度,不能中断请求(abort)
fetch('http://example.com/movies.json')
.then(response => response.json())
.then(data => console.log(data));
for in & for of
for...of是ES6新增的,用来遍历数组、类数组对象,字符串、Set、Map 以及 Generator 对象。
// 普通对象使用for...of遍历 来自: https://juejin.cn/post/6940945178899251230#heading-77
var obj = {
a:1,
b:2,
c:3
};
//方法一:
obj[Symbol.iterator] = function(){
var keys = Object.keys(this);
var count = 0;
return {
next(){
if(count < keys.length)
return {value: obj[keys[count++]],done:false};
else
return {value:undefined,done:true};
}
}
};
for(var k of obj){
console.log(k);
}
// 方法二
obj[Symbol.iterator] = function*(){
var keys = Object.keys(obj);
for(var k of keys){
yield [k,obj[k]]
}
};
for(var [k,v] of obj){
console.log(k,v);
}
for...in主要是为了遍历对象,获取的是对象的键,以及会遍历到原型链上可枚举属性。所以性能差些。
const obj={a:1,b:2}
for (const key in obj) {
console.log(key);
}
JSON.stringify
列举一些注意事项
- 对于不能被序列化的转换值,可以添加
toJSON()方法(Date对象就自带),如RegExp,Error和function,且添加toJSON方法会覆盖对象默认的序列化行为 - 对象的属性值为undefined和Symbol的属性则会被忽略(在数组中变成
null) - NaN 和 Infinity 格式的数值及 null 都会被当做
null - 无法解决包含循环引用的对象,会抛出错误
- 只遍历可枚举属性,对于Set、Map等,默认返回
{}
事件循环
https://juejin.cn/post/7049385716765163534
主线程从"任务队列"中读取事件,这个过程是循环不断的,所以整个的这种运行机制又称为Event Loop,异步线程与主线程通讯靠的就是Event Loop(比如网络请求,定时器)
设计 Loop 机制和 Task 队列是为了支持异步,解决逻辑执行阻塞主线程的问题,设计 MicroTask 队列的插队机制是为了解决高优任务尽早执行的问题。
微任务:Promise.then/catch/finally、MutationObserver、process.nextTick(Node)
宏任务:script、setTimeout()、setInterval()、requestAnimationFrame()、I/O、Ajax
Timers等是先放到放到Event Table中,等满足触发条件才添加到宏任务队列中的(定时器线程处理)
简易描述:每次执行一个宏任务,然后执行所有微任务(清空微任务队列)!
首先事件循环从宏任务队列开始,有就取一个任务放入主进程(一个调用栈)中执行,然后检查微任务队列,并执行清空所有微任务队列。然后就检查是否需要视图更新(也有个更新队列),这样就算一个tick。
btw,在视图更新前会执行‘请求动画帧’的回调函数。浏览器只保证请求动画帧的回调在重绘前执行,没有确定时间。何时重绘有浏览器决定,且频率不高于主显示器的刷新率
Nodejs的事件循环与浏览器事件循环的区别
Node中的宏任务之间也有优先级,比如定时器 Timer 的逻辑就比 IO 的逻辑优先级高。
Timers Callback: 涉及到时间,肯定越早执行越准确,所以这个优先级最高很容易理解。
Pending Callback:处理网络、IO 等异常时的回调,有的 lniux 系统会等待发生错误的上报,所以得处理下。
Poll Callback:处理 IO 的 data、网络的 connection,服务器主要处理的就是这个。
Check Callback:执行 setImmediate 的回调,特点是刚执行完 IO 之后就能回调这个。
Close Callback:关闭资源的回调,晚点执行影响也不到,优先级最低。
process.nextTick方法总是发生在所有异步任务之前。(总是在当前"执行栈"的尾部触发,高优先级的微任务)
Event Loop 是 JS 为了支持异步和任务优先级而设计的一套调度逻辑,针对浏览器、Node.js 等不同环境有不同的设计(主要是任务优先级的划分粒度不同),Node.js 面对的环境更复杂、对性能要求更高,所以 Event Loop 设计的更复杂一些。
事件模型
“事件的本质是程序各个组成部分之间的一种通信方式,也是异步编程的一种实现。”
浏览器的事件模型,就是通过监听函数(listener)对事件做出反应。当事件发生后,浏览器监听到了这个事件,就会执行对应的监听函数。这是事件驱动编程模式(event-driven)的主要编程方式。
事件的操作和触发都定义在EventTarget接口,分别具有addEventListener、removeEventListener和dispatchEvent方法
element1.addEventListener('click', hello); // 注册事件,调用 hello方法,默认冒泡阶段触发
element1.removeEventListener('click',hello);// 移除事件,第二 、第三个参数都要一样才能移除
element1.dispatchEvent(new Event('click')); // 触发事件,传入一个事件对象(必须指定事件类型)
事件流
事件流包括三个阶段:事件捕获阶段、处于目标阶段、事件冒泡阶段。
捕获阶段是从window对象传导到目标节点
冒泡阶段是从目标节点导回到window对象
<p id="parent">父元素 <span id="child">子元素</span></p>父级先捕获→子级捕获→子级冒泡→父级冒泡
事件委托/代理
由于事件会在冒泡阶段向上传播到父节点,因此可以把子节点的监听函数定义在父节点上,由父节点的监听函数统一处理多个子元素的事件。这种方法叫做事件的代理(delegation)。
利用事件冒泡(里面往外面冒泡li>ul>body),只指定一个事件处理(ul)程序,就可以管理某一类型的所有事件。(公司前台MM帮忙取快递例子)
比如ul>li*6,不必为每个li绑定事件,ul绑定事件即可, 利用e.target即可知道触发的是哪个li了。
这样节省了绑定事件的数量,进而节省内存,提高性能。同时后面新来的元素也不用麻烦的添加事件函数,也能处理事件了
鼠标事件坐标
| 属性 | 说明 | 兼容性 |
|---|---|---|
| offsetX/Y | 以当前的目标元素左上角为原点,定位x/y轴坐标 | |
| clientX/Y | 以浏览器可视窗口左上角为原点,定位x/y轴坐标 | all |
| pageX/Y | 鼠标指针相对于整个文档(document)的X/y坐标; | |
| screenX/Y | 鼠标指针相对于全局(屏幕)的X/y坐标 | all |
元素视图尺寸
| 属性 | 说明 |
|---|---|
| offsetLeft/Top | 获取当前元素到定位父节点的left/top方向的距离 |
| offsetWidth/Height | 返回一个元素的布局宽度/高度(包含到border和padding) |
| clientWidth/Height | 表示元素的内部宽度/高度(包含padding,不包含border) |
| scrollWidth/Height | 包含clientWidth/Height以及溢出的内容(如果有) |
| scrollLeft/Top | 可以读取或设置元素滚动条到元素左/上边的距离 |
| Window.innerWidth/Height | 浏览器窗口可视区宽度/高度(不包含菜单栏、工具栏等) |
script标签中的async和defer
async:开启另外一个线程下载js文件,下载完成,立马执行。(此时才发生阻塞)
defer:开启另一个线程下载js文件,直到页面加载完成时才执行。(根本不阻塞)
在开发中,defer常用于需要整个DOM的脚步(依赖于执行顺序),async用于独立脚本如计数器或广告
有 defer 属性的脚本会阻止 DOMContentLoaded 事件,直到脚本被加载并且解析完成。
ES6(ES2015)
从以下方面数据类型、关键字、机制、对象、便利性
Symbol、const/let、Class与extend、ES Module 、解构、字符串模板、箭头函数、新的自带对象orApi( Set、Map、Promise、Promise、Genrator、Proxy、Refect) 、迭代器和for...of、函数默认值、对象属性名简写、以及自带对象再增强
ES2016-ES2020
- ES7:
includes()方法(更好的语义化和NaN比较) 、求幂运算符** - ES8:
async/await关键字 、Object.values,Object.entries等 - ES9: for await of(异步迭代)、改进正则表达式(命名捕获组、dotAll等) 、剩余运算符和对象扩展运算符
- ES10: flat/flatMap、catch变量可选、function.toString()等
- ES11: 可选的链接操作
?.、??运算符、Promise.allSettled、global this、动态引入import()、BigInt、String.prototype.matchAll()
CSS基础
文章推荐
- 一个比较全的总结:1.5 万字 CSS 基础拾遗(核心知识、常见需求): https://juejin.cn/post/6941206439624966152
- css篇--100道近两万字帮你巩固css知识点: https://juejin.cn/post/6844904185847087111
- 你未必知道的49个CSS知识点: https://juejin.cn/post/6844903902123393032
position 定位
- static:默认属性
- relative:相对其正常位置定位,不脱离文档流
- absolute:相对于最近定位为非static的父级元素进行定位,脱离文档流
- fixed:生成固定定位的元素,相对于浏览器窗口进行定位!
- sticky:集合了fixed和relative,但受控于父元素们。需要设置top属性,当具体元素距离上边距{{top}}时,由relative变成类似的fixed效果,但父元素滚动出去了它也要跟着出去,用于实现跟随窗口的效果
- inherit:继承父级元素的position属性值
overflow 溢出
来自:https://juejin.cn/post/6844904199772176392#heading-3
| 属性值 | 描述 |
|---|---|
| visible | 不剪切内容也不添加滚动条 默认值 |
| hidden | 不显示超过对象尺寸的内容,超出的部分隐藏掉 |
| scroll | 不管超出内容否,总是显示滚动条 |
| auto | 超出自动显示滚动条,不超出不显示滚动条 |
单文本溢出处理:
/*1. 先强制一行内显示文本*/
white-space: nowrap;
/*2. 超出的部分隐藏*/
overflow: hidden;
/*3. 文字用省略号...替代超出的部分*/
text-overflow: ellipsis;
多行文本溢出处理:
/* ★盒子模型*/
display: -webkit-box;
/*超出的部分隐藏*/
overflow: hidden;
/*文字超出用省略号*/
text-overflow: ellipsis;
/* ★显示的文本行数,3行*/
-webkit-line-clamp: 3;
/* ★子元素的垂直排列方式*/
-webkit-box-orient: vertical;
Flexbox
是一种一维的布局模型,它给 flexbox 的子元素之间提供了强大的空间分布和对齐能力。同时看起来更简洁优雅。
flex属性用于设置flex-item如何增大或缩小以适应其弹性容器中可用的空间。是以下三属性的简写。
flex-grow: 定义项目的放大比例(空间足够) e.g: 3个itme 1 2 1 相当于各占据25% 50% 25%
flex-shrink:定义项目的缩小比例(空间不足) 1 会缩小 0 不会 默认是1
flex-basis:定义在分配多余空间之前,item占据的主轴空间
单值语法:无单位数视为flex:<number> 1 0;,单位数视为flex-basis值
flex: initial == flex: 0 1 auto // 根据自身大小放置,空间不够缩小
flex: auto == flex: 1 1 auto // 会自适应,空间够就伸长,不够就缩小
flex: none == flex: 0 0 auto // 根据自身大小放置,不缩小也不伸长,完全非弹性
BFC 块级格式化上下文
“我不影响你,你别影响我”
BFC 就是页面上的一个隔离的独立容器(断绝空间内外元素间相互的作用),容器里面的子元素不会影响到外面的元素。反之也如此。计算BFC的高度会包含所有子元素进行计算。浮动盒区域不叠加到BFC上。
-
哪些条件可以触发
-
浮动元素:float 除 none 以外的值
-
绝对定位元素:position (absolute、fixed)
-
display 为 inline-block、table-cells、flex、grid
-
overflow 除了 visible 以外的值 (hidden、auto、scroll)【最常用】
-
-
BFC的应用
- margin重叠:当父元素和子元素发生 margin 重叠时。解决办法:给子元素或父元素创建BFC
- BFC区域不与float区域重叠(清除浮动原理:计算BFC的高度时,考虑BFC所包含的所有元素,连浮动元素也参与计算)
- 分栏布局:一边float,另一边BCF占满剩余空间 (浮动盒区域不叠加到BFC上)
来自:https://juejin.cn/post/6844904071497777165#heading-5
box-sizing 盒模型
盒的四个区域:内容、内边距、边框、外边距
- box-sizing:content-box; 默认值,只计算内容的宽度,border和padding不计算入width之内
- box-sizing:border-box; border和padding计算入width之内
CSS变量
// 定义在这个伪类确保所有选择器可以访问
:root{
--red: #ff0e0e; // 变量名必须 --开头 区分大小写
--tiny-shadow: 4px 4px 2px 0 rgba(0, 0, 0, 0.8);
}
// 使用
li {
color: var(--red,red); // 第二个可选参数是当第一个参数不生效时使用(备用选项)
box-shadow: var(--tiny-shadow);
}
CSS变量在管理颜色,主题切换,减少重复代码,增加易读性方面很有作用
在其他CSS变量中、calc()函数中也可以使用
z-index
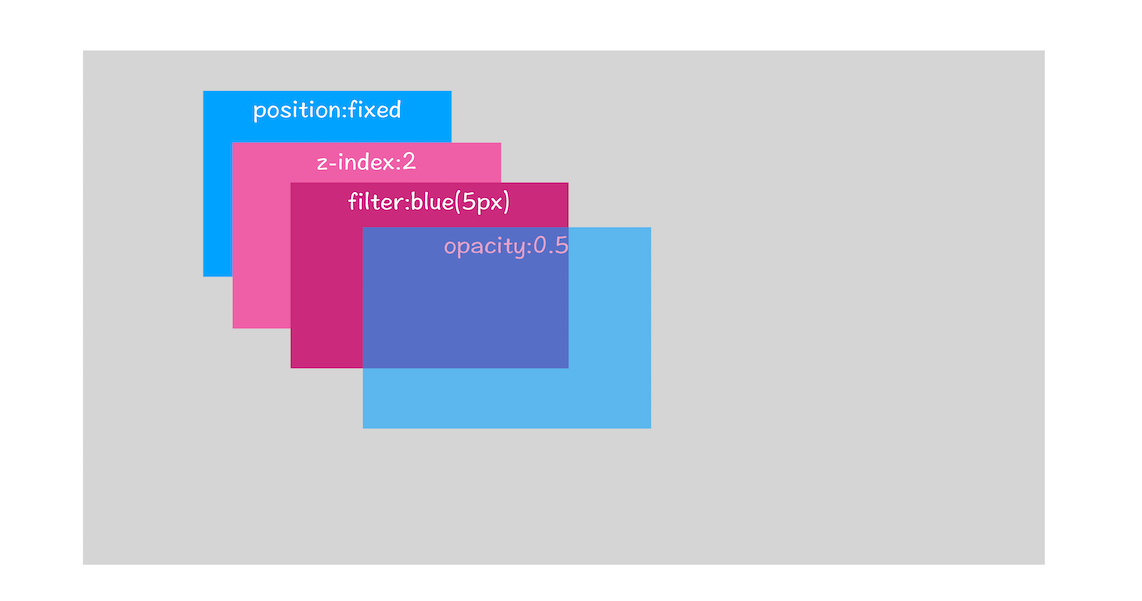
z-index只应用在定位的元素,默认z-index:auto;
在层叠上下文中 ,子级层叠上下文的z-index值只在父级容器中才有效(即在同一层叠上下文中)。其值只决定在同一父级容器中,同级子元素的堆叠顺序。

常用单位
- px:像素单位
- %:百分比
- em: 相对于元素的字体大小(font-size)
- rem:作用于非根元素时,是相对于根元素字体大小 (root em)
- vh/vw:v是view,视窗的意思 100vh就是100%的视窗高度
设备像素比 1px问题
DPR = 物理像素(设备像素) / 独立像素(CSS像素)
TODO
margin padding的百分比计算
padding-top/bottom,margin-top/bottom 取值为百分比的时候,参照的是父元素的宽度。
定位元素的top, left, right, bottom 取值百分比时相对于父级定位元素宽高
CSS元素分类
块级元素(block):能设置宽高,独占一行。
内联元素(inline):不能设置宽和高,不影响换行。
替换元素和非替换元素:非替换元素的表现由内容决定。替换元素相反可随意设置宽高,其展现效果不是由CSS来控制的。简单来说,它们的内容不受当前文档的样式的影响。 CSS 可以影响可替换元素的位置,但不会影响到可替换元素自身的内容。
| inline-level 元素分类 | 具体元素 | 默认特征 |
|---|---|---|
| 可替换元素 | img、input、iframe、video、canvas、 | 宽高可任意设定 |
| 非替换元素 | a、strong、code、label、span | 宽高由内容决定 |
inline inline-block block的区别
- block:
- block元素会独占一行,多个block元素会各自新起一行。默认情况下,block元素宽度自动填满其父元素宽度。
- block元素可以设置width和height属性。块级元素即使设置了宽度,仍然是独占一行。
- block元素可以设置margin和padding属性。
-
inline-block:
简单来说就是将对象呈现为inline对象,但是对象的内容作为block对象呈现。之后的内联对象会被排列在同一行内。比如我们可以给一个link(a元素)inline-block属性值,使其既具有block的宽度高度特性又具有inline的同行特性。
-
inline:
- inline元素不会独占一行,多个相邻的行内元素会排列在同一行里,直到一行排列不下,才会新换一行,其宽度随元素的内容而变化。
- inline元素设置width,height属性无效。
- inline元素的margin和padding属性,水平方向的padding-left, padding-right, margin-left, margin-right都产生边距效果;但竖直方向的padding-top, padding-bottom, margin-top, margin-bottom不会产生边距效果。
注: 一些inline元素同时又是可替换元素,比如img\input这些,本身带有width height属性,所以可以设置宽高
作者:homyeeking
链接:https://juejin.cn/post/6844904197435949064
伪类和伪元素
伪元素 (它表现像加入全新的HTML元素一样)
| 选择器 | 描述 |
|---|---|
::after |
匹配出现在原有元素的实际内容之后的一个可样式化元素。 |
::before |
匹配出现在原有元素的实际内容之前的一个可样式化元素。 |
::first-letter |
匹配元素的第一个字母。 |
::first-line |
匹配包含此伪元素的元素的第一行 |
::selection |
匹配文档中被选择的那部分。 |
伪类(它用于选择处于特定状态的元素)
| 选择器 | 描述 |
|---|---|
:active |
在用户激活(例如点击)元素的时候匹配 |
:checked |
匹配处于选中状态的单选或者复选框。 |
:focus |
当一个元素有焦点的时候匹配。 |
:hover |
当用户悬浮到一个元素之上的时候匹配。 |
:disabled |
匹配处于关闭/禁用状态的用户界面元素 |
| :nth-... | :nth-child、:nth-of-type 等等(从1开始) |
:visited |
匹配已访问链接。 |
ele:nth-of-type(n) 指父元素下第n个ele元素 (计算n时只纳入ele元素)
ele:nth-child(n) 指父元素下第n个元素且这个元素是ele元素才匹配
选择器优先级
按照权重排列 !important 拥有最高优先级
- 内联样式(style=“ ”) 1000
- id选择器(#myid) 100
- 类选择器(.myclass) 10
- 属性选择器(a[rel="external"]) 10
- 伪类选择器( :active , :hover) 10
- 元素选择器(div, h1,p,after) 1
- 关系选择器、通配符 0
- 继承样式
- 默认样式
transition和animation
transition:
语法:transition: CSS属性|all, 花费时间, 效果曲线(默认ease),延迟时间(默认0)
作用:为元素的变化添加过度效果
animation:
语法:animation:动画名称,一个周期花费时间,运动曲线(默认ease),动画延迟(默认0),播放次数(默认1),是否反向播放动画(默认normal),是否暂停动画(默认running)
.ball{
/* ...some props */
animation: swell 2s linear infinite
}
相关事件:
- animationstart
- animationend
- animationiteration
用于更好的控制动画和信息,可探测动画何时开始和重新循环。每个事件包含发生时间和触发事件的动画名称。
ball.addEventListener("animationstart", listener, false);
function listener(e) {
console.log(e.elapsedTime) // 发生时间
switch(e.type) {
case "animationstart":
break;
case "animationend":
break;
case "animationiteration":
break;
}
}
animation https://developer.mozilla.org/zh-CN/docs/Web/CSS/animation
display:none和visibility:hidden
display:none不会保留元素(不被渲染),位置会被之后正常的文档流覆盖。更改值后会触发reflow(回流)
visibility:hidden仍会保留元素,只是看不见。更改值后会触发repaint(重绘)
dom树:display:none和visibility:hidden
渲染树:visibility:hidden
此外 opacity:0 和 visibility:hidden 一样也只是隐身,但opacity:0可以触发点击等事件,visibility:hidden 不能。visibility属性可以被继承和修改,让父元素隐藏,子元素显现。
水平居中
- 已知宽度的元素设置文本内容水平居中:
text-align:center - 设置有宽度的块级元素水平居中:
margin:0 auto display:flex+justify-content:center设置子元素水平居中
垂直居中
- 已知高度的元素设置文本内容垂直居中:
line-height:高度或者给父元素设置display:table-cell;vertical-align:middle display:flex+aligin-items:center设置子元素垂直居中
水平+垂直居中
- 绝对定位居中除了
top/left:50%之外需要使用margin-top/left:高度/宽度的一半或者transform: translate(-50%, -50%)来让中心点而非左上角居中。 .box1 {display: grid;place-items: center;}最便捷实现水平+垂直居中.box1 {display: flex; justify-content: center; align-items: center;}` 第二便捷实现水平+垂直居中- 以上两种若有多个元素要居中,使用grid布局会在一列上放,flex布局会在一行上放(默认主轴方向为行)
三列布局
float(两边各自浮动到两边)、flex(flex属性)、grid(grid-template-columns)、table(display:table-cell)、position(都用绝对定位,中间使用left,right扩展开)
清除浮动
css系列之clear属性: https://juejin.cn/post/6931147937519304711
不清除子元素的浮动,可能会导致没东西撑起父元素,从而造成高度塌陷
最好的方案就使用伪元素,使用clear:both,不允许周围有浮动现象
clear属性表明该元素周围不能有浮动元素。设置后该元素就会跑到浮动元素的下面(单独一行),就像增加个上外边距。
.clearfix::after {
content: '';
display: block;
clear:both
}
其他不常用方法(面试官可能会问还有其他方式吗)
- 父级元素添加overflow属性 触发BFC
- 添加额外标签(再最后一个浮动标签后再添加一个新标签 给其设置clear:both)
扩大可点击区域
利用伪元素代替主元素响应鼠标交互
button {
position:relative;
/* ... */
}
button:before {
content:'';
position:absolute;
top:-10px;
right:-10px;
bottom:-10px;
left:-10px;
}
BEM命名规范
BEM的命名规矩很容易记:block-name__element-name--modifier-name,也就是模块名 + 元素名 + 修饰器名/状态。
一般来说,根据组件目录名来作为组件名字:
比如分页组件:/app/components/page-btn/
那么该组件模块就名为page-btn,组件内部的元素命名都必须加上模块名,比如:
<div class="page-btn"> <button type="button" class="page-btn__prev">上一页</button> <!-- ... --> <button type="button" class="page-btn__next">下一页</button> </div>
.header__logo{ border-radius: 50%; } .header__title{ font-size:16px; }
.page-btn__prev--loading{ background:gray; } .page-btn__prev--disabled{ cursor: not-allowed; }
在Sass中使用
.header {
&__title {
wdith: 100px;
padding: 20px;
}
&__button {
&--primary {
background: blue;
}
&--default {
background: white;
}
}
} // from https://juejin.cn/post/6969524904400011301#heading-6
SASS LESS
不同于CSS的地方
嵌套写法、使用运算符、继承、mixin、函数、条件循环
css匹配规则
由于每条规则可能存在嵌套,例如 #container p.content .title a {…},如果采用从左到右的方式读取css规则,那么大多数规则读到最后会发现是不匹配的,这样会做很多无用功。
如果从左开始匹配,要使用回溯从树根遍历DOM树。性能浪费大。
如果从右开始匹配,先找到对于节点,然后向上查找,直至根元素停止。能在第一步就快速筛选的不符合的最右节点。
Webpack基础
webpack编译项目从解析webpack.config.js开始,每完成特定的一步会调用响应的钩子。
- 首先是要解析入口文件,并将文件转换成AST(
@babel/parser)。 - 找出入口文件所有的依赖模块(
@babel/traverse) - 将文件转换成可执行的代码,并按照第二步这样递归下去重复执行1、2、3
- 重写
require函数,并按照步骤4生成依赖关系图,输出到bundle中
涉及到多个区块的代码打包,通过import()实现code spliting,利用jsonp加载 chunk 的运行时代码。
先从配置文件和shell语句读取参数并初始化Compiler对象,加载所有配置Plugin,执行run()开始编译。
webpack使用nodejs的fs模块,读取定义的入口entry文件,将文件转换成AST树,并递归地获取所依赖的模块文件。
调用对用的loader处理匹配后缀的文件,将遇到的模块文件都放入_webpack_modules_这个对象中,并用文件的相对src路径作为对象key。
对象key对应的值是一个函数,该函数的参数是模块、导出、导入三个对象和方法,方法内部利用eval()执行原本文件的js内容(被webpack用babel转成AST,进行遍历,再生成浏览器可执行的代码(一段IIFE),里面的用到的导入导出属性,就是由参数传进来的)。
function __webpack_require__(moduleId) {
if (__webpack_module_cache__[moduleId]) {
return __webpack_module_cache__[moduleId].exports;
}
var module = (__webpack_module_cache__[moduleId] = { exports: {}, });
// 原文件的require、module被重写了,值就是下面传入的那三个实参
__webpack_modules__[moduleId](module, module.exports, __webpack_require__);
return module.exports;
}
var __webpack_modules__ = {
"./src/add.js": ( __unused_webpack_module, __webpack_exports__,__webpack_require__) => {
eval(`__webpack_require__.r(__webpack_exports__);
__webpack_require__.d(__webpack_exports__, {
"default": () => __WEBPACK_DEFAULT_EXPORT__
});
var add = function add(a, b) { return a + b; };
const __WEBPACK_DEFAULT_EXPORT__ = (add);`);
},
"./src/index.js": (__unused_webpack_module,__webpack_exports__,__webpack_require__) => {
eval(
'__webpack_require__.r(__webpack_exports__);\n var _cute_js__WEBPACK_IMPORTED_MODULE_0__ = __webpack_require__("./src/cute.js");\n var _add_js__WEBPACK_IMPORTED_MODULE_1__ = __webpack_require__("./src/add.js");\n\n\n var num1 = (0,_add_js__WEBPACK_IMPORTED_MODULE_1__.default)(1, 2);\nvar num2 = (0,_cute_js__WEBPACK_IMPORTED_MODULE_0__.cute)(100, 22);\nconsole.log(num1, num2);'
);
},
}
// .d是给对象定义属性 .o是hasOwnProperty调用 .r 用于标识对象为'Module'
loader
loader是文件加载器(本质是一个函数,接受源代码输出处理后的结果),能对文件进行编译压缩等处理(webpack默认支持js),并将它们转换为有效模块,最后打包进去,loader的执行顺序和配置中相反。
在处理文件前,首先会经历patch阶段,pitich loader属性返回非undefined会产生熔断效果。
详解:https://juejin.cn/post/7036379350710616078
plugin
plugin是对webpack在运行的生命周期中广播出的事件进行处理,可通过Webpack的API改变结果。(基于Tapable )
Q: plugin1可以派发事件让plugin2监听吗?
A: webpack的事件机制是基于观察者模式的。plugin不仅能够监听事件,也能够广播事件和其他的插件进行通信。
// 广播事件
compiler.apply('event-name', params)
// 监听同名的事件,当这个事件触发的时候,回调函数就会被执行
compiler.plugin('event-name', params => {
。。。
})
// https://zhuanlan.zhihu.com/p/40930680
Q: 常见的loader 和 plugin 有哪些
file-loader:把文件输出到一个文件夹中,在代码中通过相对 URL 去引用输出的文件。
url-loader:把小文件转换成base64内联到代码中。
markdown-loader:把markdown文件转换成html文件
babel-loader:把转换js到需要支持的版本如es6->es5
ts-loader:把 TypeScript 转换成 JavaScript
转换样式文件相关的css、style、、sass、postcss、less-loader
css-loader:加载css,支持模块化、压缩、文件导入等
style-loader:通过js创建一个style标签注入到dom中
eslint-loader:通过eslint去检查代码
vue-loader:加载vue.js的单文件组件
Babel
核心就是利用一系列plugin来管理编译的案例,对不同es版本的js、甚至jsx。来把它们编译成所需要的js,来让更多浏览器支持该js的运行
解析、遍历、生成
babel.config.js 和.babelrc 有什么区别
全局配置 (babel.config.js) :即针对第三方代码也针对自己的代码
局部配置 (.babelrc):按目录加载 ,只影响版项目
Q: module、chunk、bundle、asset的区别?
asset:就是图片字体等资源文件
chunk:webpack处理时根据文件引用关系组成的chunk文件
moudule:每个文件都可以视为一个模块
bundle:处理chunk文件后,生成可在浏览器中运行的代码
https://blog.51cto.com/u_15283585/2957111
Q: Content Hash、Chunk Hash、Hash
hash一般是结合缓存使用。
Hash是根据文件是否更改而更改。也就是说每次文件改动,编译都会创建一个新的hash值, 并且所有文件的hash都是一样的。这样一来文件就不会被浏览器缓存,保证文件更新效率。整个项目hash都一样
Chunk Hash是每个chunk文件都一个hash值,不同的chunk会有不同的hash值。在生产环境中,对于公共库和第三方依赖,利用chunk hash单独打包,可以更合理利用浏览器缓存。
Content Hash是由文件内容产生的hash,不同内容就有不同hash。最常用的就是css单独抽离并引用。(你css变动了不管我js的事)可以更有效利用缓存。
打包体积优化
主要思路是分离&提取、按需加载、提取通用模块、压缩&混淆代码、Tree Shaking、图片压缩、
热更新原理
当启动一个服务之后(用的webpack-dev-server),浏览器和服务端是通过websocket进行长连接,webpack内部实现的watch(基于chokidar库)就会去监听文件修改。只要文件有修改,webpack就会重新打包编译到内存中,然后webpack-dev-server依赖中间件webpack-dev-middleware和webpack之间进行交互,每次热更新都会请求一个携带hash值的json文件和一个js,websocke传递的也是hash值,内部机制通过hash值检查进行热更新。
- 用
Hash值代表每一次编译的标识 - 编译完成后通过
websocket向客户端推送当前编译的hash戳 - 客户端的
websocket监听到有文件改动推送过来的hash戳,会和上一次对比- 一致则走缓存,不去请求
- 不一致则通过
ajax和jsonp向服务端获取最新资源,并替换删除缓存
- 使用内存文件系统(memfs)去替换有修改的内容实现局部刷新
- https://blog.csdn.net/chern1992/article/details/106893227/
- https://segmentfault.com/a/1190000020310371
- https://mp.weixin.qq.com/s/gG_FwVGHiJGjQOvt5rZheA (未看)
与Rollup的对比
Webpack强调的是前端模块化方案,侧重模块打包。Rollup简洁且打包出体积更小的文件(tree shaking)。
开发库的时候用Rollup多,比如Vue和React等。
Vite基础
主要特性
bundless,基于浏览器原生支持的ES module,相当于按需引入模块,跳过打包这个概念,还利用浏览器缓存策略提升速度。解决了dev server的性能。
生产环境下使用rollup打包编译(用esm发送太多请求是不如本地快滴)。开发和生产环境下共享同一套 Rollup 插件机制。
启动项目相比Webpack而言,Vite是直接启动一个devServer,劫持浏览器的请求,在服务器中进行相应处理并返回,过程中没有对文件进行打包编译。
预构建
预构建是用来提升页面重载速度,支持ts/jsx/js代码的转化,将 CommonJS、UMD 等转换为 ESM 格式,。预构建这一步由 esbuild 执行,这使得 Vite 的冷启动时间比任何基于 JavaScript 的打包程序都要快得多。Vite预编译之后,将文件缓存在node_modules/.vite/文件夹下。当依赖变化后,会重新与构建。
热更新
跟webpack-dev-server类似,服务端监听文件改动(通过给.vue文件注册Watcher)和编译资源,通过websocket想客户端发送消息,客户端进行逻辑判断(文件指纹)是否要更新。
基于ESM的devServer插件在启动时会先初始化服务器和加载对应插件。插件包括拦截请求,将其转换成浏览器可识别的ESM语法、对.ts、.vue的即使编译以及 sass 或 less 的预编译、与浏览器建立socket 连接,用于实现HMR。
启动一开始通过插件向向index.html注入代码,劫持/vite/hmr的请求,然后返回client.js 文件,该文件主要用于跟服务器(koa)建立websocket连接。
Plugin
基于Rollup设计的接口进行扩展,加上vite特有的钩子和属性来扩展。包括提供相关配置config设置和确认,配置开发服务器,添加中间件。转换index.html文件,和自定义HMR,同过ws发送自定义事件。
参考:https://juejin.cn/post/6854573209329598477
文章推荐:深入理解Vite核心原理
Nodejs基础
NodeJS 是基于Chrome V8引擎的 JavaScript 运行环境。NodeJS使用事件驱动,非阻塞型I/O的模型,使其轻量又高效。且有一堆优化的API类库调用(如c++的libuv)。
Nodejs异步编程最直接的体现就是回调。使得代码执行时没有阻塞或者等待文件I/O的操作,在读文件的同时执行接下来的代码,提高了程序性能。
http模块
const http = require('http')
const server = http.createServer((req,res)=>{
res.writeHead(200,{'content-type':'text/plain'})
res.write('hello,world!')
res.end()
})
server.listen(3000)
fs模块:操作文件、目录等
path模块:目录拼接、目录解析
事件循环
推荐直接看官方文档... Node.js 事件循环,定时器和process.nextTick
nodejs中事件循环比浏览器中划分更详细。其中与开发者相关的三个阶段分别是Timers、Poll、Check
Timer阶段执行timer的回调,并且是由Poll阶段控制。时间只确保尽快执行,不一定准确。
Poll阶段(轮询)会检查是否存在定时器,且到点了就执行它并回到Timer阶段、poll队列是否有回调函数要执行、setImmediate回调是否需要执行
Check阶段就是执行 setImmdiate 的回调,设计为一旦在当前 轮询 阶段完成, 就执行回调。
使用 setImmediate() 相对于setTimeout() 的主要优势是,如果setImmediate()是在 I/O 周期内被调度的,那它将会在其中任何的定时器之前执行,跟这里存在多少个定时器无关
TypeScrpit
Type 跟 Interface 的区别?
都是描述类型,差距不大。interface更注重于描述数据结构 ,type侧重于描述类型
interface Person{
name:string;
age: number;
}
type Sex = 'MALE'|'FEMALE'
type还有专属的联合类型
interface Dog {
name:string
}
interface Cat {
name:string
}
type Pet = Dog | Cat
let a:Dog={name:'1'} , b:Cat={name:'2'}
let c:Pet = a;
协变和逆变
协变: 允许子类型转换为父类型
let dog:Dog=new Dog(); let animal:Animal=dog; dog=animal; // Error,Aniaml不满足子类Dog(比如没有狗叫方法)逆变: 允许父类型转换为子类型
interface Animal{} interface Dog extends Animal{ bark:()=>void } let db:(d:Dog)=>void=function(d:Dog){ d.bark() } let ab:(a:Animal)=>void=function(a:Animal){} db = ab ab = db // TS Error animal没有bark方法 db({bark(){}}); // 调用原ab的函数,Dog发散为Aniamal,安全 ab({}) // 调用原db的函数,但{}并没有bark方法协变表示类型收敛,即类型范围缩小或不变。逆变反之(发散)
除了函数参数类型是逆变,都是协变
包管理器
依赖管理
yarn最先时候loack文件锁定版本,后npm也才增加上
都采用扁平化管理依赖,避免嵌套深、大量包重复安装的问题
pnpm使用硬链接来节省磁盘工具,对于重复的包或者代码,都会建立硬链接指向同一份文件。
pnpm利用软链接机制,还能控制包的访问,只有声明在package.json中的包才能访问,在node_module中只有一个对应模块(是个软链接文件,连接到.pnpm目录下具体的模块)。而yarn和npm的扁平化会可能导致非法访问
安装速速
yarn采用并行安装依赖方式,比串行的npm快些
npm模块安装机制
https://github.com/Advanced-Frontend/Daily-Interview-Question/issues/22
- 执行 package.json中的preinstall 钩子(如果有)
- 从首层依赖(dependencies 和 devDependencies),利用多线程递归解析子赖用到的模块。生成依赖树(可能带有重复模块)
- 模块扁平化,过程中会判断重复依赖版本是否存在交集,如果没有则后面的版本保留到依赖树中。有则使用兼容的版本。
- 更新项目中的node_modules,并相应钩子
浏览器原理
最推荐:一文看懂Chrome浏览器运行机制 (太长就看了一部分)
浏览器缓存
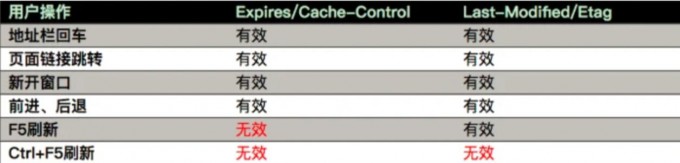
所谓用户行为对浏览器缓存的影响,指的就是用户在浏览器如何操作时,会触发怎样的缓存策略。主要有 3 种:
- 打开网页,地址栏输入地址: 查找 disk cache 中是否有匹配。如有则使用;如没有则发送网络请求。
- 普通刷新 (F5):因为 TAB 并没有关闭,因此 memory cache 是可用的,会被优先使用(如果匹配的话)。其次才是 disk cache。
- 强制刷新 (Ctrl + F5):浏览器不使用缓存,因此发送的请求头部均带有 Cache-control: no-cache(为了兼容,还带了 Pragma: no-cache),服务器直接返回 200 和最新内容。
缓存分类
memory cache:几乎所有的请求资源 都能进入 memory cache。
disk cache:严格根据HTTP头部信息来判断是否缓存。
service worker::定义更加灵活的存储。
缓存未命中后请求内容
-
根据 Service Worker 中的 handler 决定是否存入 Cache Storage (额外的缓存位置)。
-
根据 HTTP 头部的相关字段(
Cache-control,Pragma等)决定是否存入 disk cache -
memory cache 保存一份资源 的引用,以备下次使用。
小结(来自参考1)
- 调用 Service Worker 的
fetch事件响应 - 查看 memory cache
- 查看 disk cache。这里又细分:
- 如果有强制缓存且未失效,则使用强制缓存,不请求服务器。这时的状态码全部是 200
- 如果有强制缓存但已失效,使用对比缓存,比较后确定 304 还是 200
- 发送网络请求,等待网络响应
- 把响应内容存入 disk cache (如果 HTTP 头信息配置可以存的话)
- 把响应内容 的引用 存入 memory cache (无视 HTTP 头信息的配置)
- 把响应内容存入 Service Worker 的 Cache Storage (如果 Service Worker 的脚本调用了
cache.put())
浏览器原理
页面加载过程(仅为HTTP)
-
构建请求行(
GET / HTTP/1.1),然后检查强缓存,命中则直接使用不发起请求 -
进行DNS域名解析(现状在本机查找,没有则发起UDP请求查询)
-
通过三次握手建立TCP连接(通过SYN机制判断双方接受能力)
-
浏览器构造HTTP请求报文并发起请求
-
服务器处理请求并返回(响应行
HTTP/1.1 200 OK)处理结果给浏览器 -
当不需要连接时,任意一方可以发起关闭请求,通过四次挥手来关闭
-
解析HTML并生成
DOM树,CSS下载完后解析生成CSSOM树解析工作以及JS的执行都由主线程执行
-
当DOM和CSSOM树构建完毕后,确定元素位置,生成渲染树
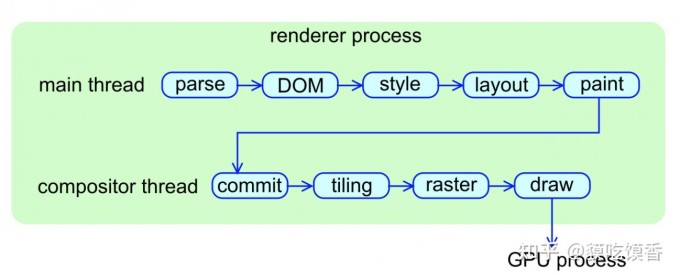
渲染流水线:JavaScript/CSS > 样式计算 > 布局 > 绘制 > 渲染层合并 > 光栅化
-
构建完渲染树之后,还会对特定节点进行分层,构建图层树,用于图层绘制并展现
-
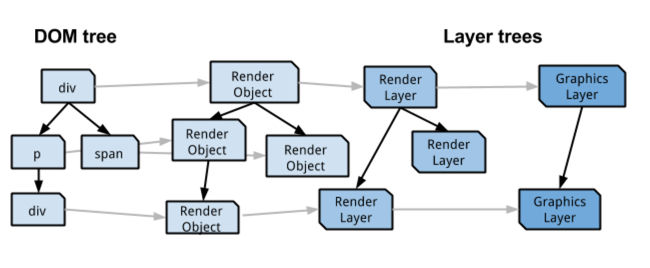
某些特殊的渲染层会被认为是合成层(Compositing Layers),合成层拥有单独的 GraphicsLayer,而其他不是合成层的渲染层,则和其第一个拥有 GraphicsLayer 父层共用一个绘图层(节点的图层默认属于父节点图层) (Composite)
-
对于拥有层叠上下文的节点属于显示合成,会提升为单独的一个合成层
![img]()
-
与显示合成对比的是隐示合成:在一个单独图层上还有层叠等级更高的节点,都会被提升为一个单独的图层,可能就会造成层爆炸,但浏览器也会尽力优化。
-
图层树构建后,就是图层绘制,渲染引擎会将图层的绘制拆成绘制指令,并组成绘制列表
-
准备完绘制列表,主线程会把绘制列表commit给合成线程(compositor thread)
-
合成线程会将图层分块(以便按需绘制),然后便是将视图附近的图块转换成位图(点阵图像)
由栅格化线程池完成转换工作,做的事就叫栅格化(过程中会使用GPU来加速生成)
-
合成线程发送绘制图块命令
DrawQuad给浏览器进程 -
浏览器进程根据
DrawQuad消息生成页面,并显示到显示器上
-
-
-To be continue
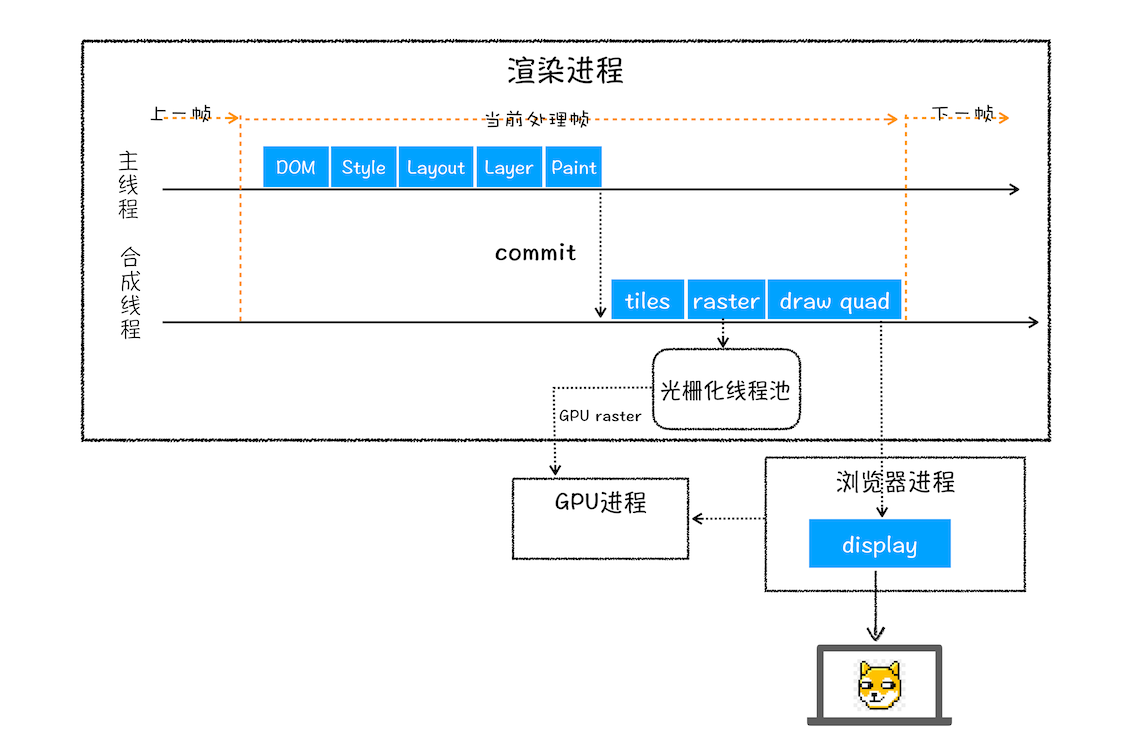
浏览器渲染
这是些零散的知识点记录。。。
https://fed.taobao.org/blog/taofed/do71ct/performance-composite/
合成,就是把图层(GraphicsLayer)合并!
绘制阶段,并不是真绘制,而是生成绘制指令列表!有了绘制列表在进行光栅化生成图片(位图)。
每一个图层都对应一张图片,合成线程有了这些图片之后,会将这些图片合成为“一张”图片,并最终将生成的图片发送到后缓冲区。合成操作是在合成线程上完成的。这也就意味着在执行合成操作时,是不会影响到主线程执行的。
能直接在合成线程中实现的是整个图层的几何变换,透明度变换,阴影等,这些变换都不会影响到图层的内容。比如滚动页面的时候,整个页面内容没有变化,这时候做的其实是对图层做上下移动,这种操作直接在合成线程里面就可以完成了。
合成层拥有独立的绘图层(GraphicsLayer),而其他不是合成层的渲染层(RenderLayer),则和其第一个拥有绘图层的父层共用一个绘图层。
-
合成层的位图,会交由 GPU 合成,比 CPU 处理要快得多;
-
渲染层决定渲染的层级顺序
-
当需要 repaint 时,只需要 repaint 本身,不会影响到其他的层;
-
元素提升为合成层后,transform 和 opacity 才不会触发 repaint,如果不是合成层,则其依然会触发 repaint。
![qVMoxx.jpg]()
优化:使用createDocumentFragment进行批量的 DOM 操作、对resize、scroll防抖 、为动画元素创建合成层、使用请求动画帧(rAF)
层爆炸:一个非显示合成层被渲染层的元素覆盖产生交叠(overlap),会导致覆盖元素也被提升到合成层(隐式合成),就可能产生此问题。但浏览器也会有对应处理,将隐式合成的多个渲染层压缩到同一个绘图层中进行渲染,但也是有极限的。
详细博客(★):https://www.cnblogs.com/goloving/p/7196840.html
像素的一生:https://manfredhu.com/broswer/2021-12-31.broswer-render.html
重排与重绘
-
只要元素位置大小发生改变,就是重排(css3-transform除外)
-
元素节点内部渲染如颜色阴影字体家族等变化才是重绘(无位置大小变动)
-
触发创建单独图层的,浏览器将其放在合成层,不影响默认复合图层,所以不影响DOM结构,属性的改变也交给GPU处理。(各个复合图层都是单独绘制,所以互不影响)
故transform和opacity改变的仅是图层的结合不会触发回流和重绘:
opactity是GPU在绘画时简单的降低了之前已经画好的纹理的alpha值来达到效果,故不会触发回流和重绘
-
降低重排的方式:要么减少DOM节点属性的读取,要么减少修改次数,要么降低影响范围,创建新的复合图层
-
重绘&回流与事件循环的关系 (渲染流程)
- 当一次事件循环结束后,会判断文档是否需要更新,这个间隔为16ms(60Hz为例)
- 浏览器发送垂直同步信号(Vsync), 表明新一帧的开始(Frame Start)
- 先会判断是否有
reize、scroll、touchmove事件(每帧只触发一次,自带节流) - 然后会判断是否触发媒体查询、并更新动画和发送事件、判断是否全屏操作
- 执行
requestAnimationFrame回调,该函数告诉浏览器——你希望执行一个动画,并且要求浏览器在下次重绘之前调用指定的回调函数更新动画。 - 执行
IntersectionObserver回调,该接口提供了一种异步观察目标元素与其祖先元素或顶级文档视窗(viewport)交叉状态的方法(元素是否可见) - 样式计算、布局、绘制、合成、光栅化、将合成帧发送给GPU(Frame End)
- 如果还有空闲时间会执行
requestIdleCallback回调
浏览器多进程
好处:避免单个线程崩溃导致进程卡死,更好利用多核优势,方便使用沙箱模型,提高稳定性
-
每个浏览器有一个浏览器
Browser进程负责协调和主控,以及插件进程,GPU进程 -
然后每个页面(Tab)都有一个进程,负责页面渲染和脚本执行、事件处理(★)
-
主线程★(main thread)负责HTML/CSS解析、对象树的构建和JavaScript解析执行
-
合成线程★(compositor thread)根据绘制指令分块、单独光栅化,最后变成一个位图,交给GPU进程绘制
-
事件触发线程:待补充
-
定时器触发线程:
setInterval与setTimeout所在线程,用来计时并触发,然后加入任务队列 -
异步HTTP请求线程,一个XHR开一个线程去请求
-
Worker threads 、Raster thread
-
-
Browser进程收到用户请求,获取页面,然后交给Tab的渲染进程。渲染的过程中可能会有Browser进程获取资源和需要GPU进程帮助渲染。渲染Render进程会讲结果传递给Browser进程。再由Browser进程接收并绘制。 -
GPU 进程(GPU Process)不是在 GPU 中执行的,而是负责将渲染进程中绘制好的 tile 位图作为纹理上传至 GPU,最终绘制至屏幕上。
垃圾回收
常见标记清除算法(JS引擎常用)和引用计数算法。标记清除算法就是打标记(0 | 1),实现简单,当变量进入执行环境时,被标记为“进入环境”,当变量离开执行环境时,会被标记为“离开环境”。但容易让内存碎片化,以及分配内存时要遍历一次(O(n)的操作)。
V8对GC的优化:
V8 的垃圾回收策略主要基于分代式垃圾回收机制(JVM也是),分成新老两代用不同策略来管理。新生代还有2个区域,一个使用区,一个空闲区,标记阶段会将活动对象复制到空闲区,在清理阶段将非活动对象(也就是原先的使用区)清掉。交换两个区的角色。多次不被清掉的、大的对象会被移入老生代。
其次就是并行回收,减少暂停时间。
内存泄漏
全局(window)属性、闭包、遗忘的定时器 总之就是可能存在引用,导致未被释放
vue中可能发生内存泄漏场景
例如使用v-if或者vue router跳转时从VNode中移除元素时,该元素由第三方库创建的,可能就会导致泄漏,要做好即使的清理工作
这些内存泄漏往往会发生在使用 Vue 之外的其它进行 DOM 操作的三方库时,没有正确调用销毁函数。
Service Worker
Service Worker实际上是浏览器和服务器之间的代理服务器,它最大的特点是在页面中注册并安装成功后,运行于浏览器后台,不受页面刷新的影响,可以监听和截拦作用域范围内所有页面的 HTTP 请求。
Service Worker的目的在于离线缓存,转发请求和网络代理。它有自己的生命周期。
网络基础
TCP 和 UDP 的差别
tcp 可靠,有序,面向连接要握手挥手,需要消耗更多的资源,速度较慢,适合少量数据,只能一对一,能全双工
upd 不可靠,无序,面向非链接,资源消耗更少,速度更快(实时性好),结构简单,可能丢包,适合大量数据,提供单播,多播,广播的功能。
TCP协议为什么需要三次握手?
- 表因:三次挥手是在信道不可靠的基础上,避免已失效的连接请求报文段让server端建立无用的连接(会白白浪费资源,一直等client端消息)。 三次通信是理论上的最小值
- 本质:因为通讯的双方维护一个序列号
seq,用于标识发送出去的数据包中, 哪些是已经被对方收到的。三次握手的过程即是通信双方相互告知序列号起始值, 并确认对方已经收到了序列号起始值的必经步骤。 - 如果只是两次握手, 至多只有连接发起方的起始序列号能被确认, 另一方选择的序列号则得不到确认(没被 确认就建立连接岂不是不行!)
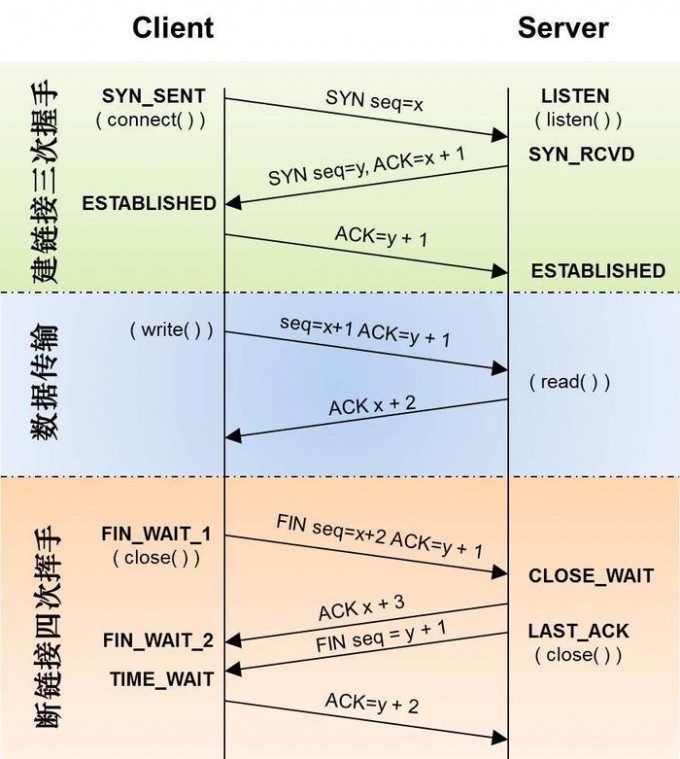
TCP协议为什么需要四次挥手?2MSL又是什么?
A:主动方 B:被动方
第二次挥手后(B→A),A不会再想B发送数据,但B还可以继续发(可用于发送没发完的数据)
第三次挥手后(B→A):③,B便进入LAST-ACK状态
第四次挥手(A→B):④,是在A接到第三次挥手后,立即发送确认应答,A会进入TIME-WAIT状态。该状态会持续2MSL时间。在这期间没B没请求,才会进入CLOSED状态。B在收到确认应答也便进入CLOSED状态。
第四次挥手原因也是要确保B能收到A的确认应答!如果A的确认应答(第四次挥手)丢失,会导致B无法正常关闭。因为B没有收到确实应答④的话,就不能确认A受否收到③,B就自动会重传③。不论是重传③或者收到④,A都需要等待,2MSL就是去MSL+来MSL的时间。B不重传就证明B收到了嘛。并会让B重传的FIN在网络中消逝。
摘要
- 来MSL+去MSL=2MSL,MSL:报文生存时间
- 不论是否要收到B的重传,A都得等。收到就重新应答,没收到就默认B收到,B不进行重传
- 确认B能收到A的确认应答,进而让B正常关闭
- 让B重传的FIN在网络中消逝
OSI和TCPIP模型
| 层级 | OSI七层模型 | TCP/IP四层 | 常用协议 |
|---|---|---|---|
| 7 | 应用层 | 应用层 | HTTPS、HTTP、SSH、DNS、FTP、SMTP(Email) |
| 6 | 表示层 | 应用层 | |
| 5 | 会话层 | 应用层 | |
| 4 | 传输层 | 传输层 | TCP、UDP |
| 3 | 网络层 | 网络层 | IP、ICMP、ARP |
| 2 | 数据链路层 | 网络接口层 | 用MAC地址访问介质 |
| 1 | 物理层 | 网络接口层 | 物理线路、光纤等处理连接网络的硬件部分 |
WebSocket
不受同源限制,是一个新的协议。一般需要HTTP协议来帮忙握手建立连接。后面就一直保持着全双工通信方式。
HTTP缓存
浏览器缓存通常分为两种:强缓存和协商缓存。
强缓存 在缓存期间不发起新请求,返回200
-
Expires,http1.0,是绝对时间的GMT格式字符串,在此时间前都有效
Expires: Wed, 21 Oct 2015 07:28:00 GMT -
Cache-Control,http1.1,max-age=xxx秒,代表缓存xxx秒,优先级高
Cache-Control: max-age=<seconds> -
二者都是响应中携带的字段,用来表示资源缓存时间,Expires使用绝对时间,当服务器与客户端时间偏差大可能就会导致缓存混乱。
-
强制刷新F5时,请求中会携带Cache-Control:no-cache和Pragma:no-cache
Cache-Control的常用指令:
no-cache:不使用本地缓存,需要使用协商缓存(校验新鲜度)no-store:禁用缓存,没次都从原始服务器获取public:响应可以被任何对象(浏览器、代理)缓存private: 只能被浏览器缓存,代理服务器不得缓存
协商缓存 如果缓存过期了,就要用协商缓存,需要一次请求,如果缓存有效,返回304
- Last-Modify (in 响应头)和If-Modify-Since (in 请求头)是一对的,值是资源最后修改时间(GMT格式字符串)
- Etag 和If-None-Match也是一对的,是文件的校验码,文件变动则变动,用来判断是否命中缓存
- 服务器会优先验证ETag,当If-None-Match和Etag一致则返回
304 - ETag 对比Last-Modified优势:
- 一些文件可能内容不变,但修改时间便了,但这并不算是修改
- Last-Modified精度是秒,要是文件修改频繁也可能认不出
- 可能服务器不能精确获取文件的最后修改时间
HTTP Header
请求字段(Request)
| 字段 | 描述 | 实例 |
|---|---|---|
| Accept | 可接受的类型(MIME) | Accept: text/plain |
| Accept-Charset | 可接受的字符集 | Accept-Charset: utf-8 |
| Accept-Encoding | 可接受的编码 | Accept-Encoding:gzip, deflate |
| Accept-Language | 可接受的语言 | Accept-Language: en,zh |
| Accept-Ranges | 定义范围请求的单位 | Accept-Ranges: bytes |
| Range | 以字节为单位,传输0到499字节范围的内容 | Range: bytes=0-499 |
| Authorization | 用于超文本传输协议的认证的认证信息 | Authorization: token字符串 |
| Cache-Control | 强缓存相关 | Cache-Control: no-cache |
| Cookie | 由服务端返回的Cookie | Cookie: $Version=1; Skin=new; |
| Content-Length | 请求内容长度 | Content-Length: 348 |
| Content-Type | 请求体的MIME类型 | Content-Type: application/x-www-form-urlencoded |
| Referer | 请求来路 | Referer: http://www.baidu.com |
| Upgrade | 协议转换(如果支持) | Upgrade: HTTP/2.0, SHTTP/1.3, IRC/6.9, RTA/x11 (Websocket也是) |
| User-Agent | 浏览器的浏览器身份标识字符串 | Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537 Chrome/98 Safari/537 |
响应字段
| 字段 | 描述 | 实例 |
|---|---|---|
| Set-Cookie | 设置Http Cookie | Set-Cookie: UserID=JohnDoe; Max-Age=3600; |
| Content-Encoding | 返回内容的压缩编码类型 | Content-Encoding: gzip |
| Content-Length | 返回内容的长度 | Content-Length: 9951 |
| Date | 原始服务器消息发出的时间 | Date: Thu, 10 Feb 2022 14:06:04 GMT |
| Location | 重定向到新位置 | Location: http://www.baidu.com |
| Keep-Alive | 便于连接复用 | Keep-Alive: 300 |
| Allow | 对某网络资源的有效的请求行为,不允许则返回405 | Allow: GET, HEAD |
内容系列
Accpet-* 代表可接受的类型
Content-* 代表要返回的类型
协商缓存系列
ETag --- If-None-Match
Last-Modified --- If-Modified-Since
Cache-Control 请求头和响应头都支持这个属性
请求头的host,origin,refer的区别是什么
host:表示当前请求要被发送的目的地(仅包括域名和端口)
origin:表示当前请求资源所在页面的协议和域名。一般只存在CORS请求中。
referer:表示当前请求资源所在页面的协议、域名和查询参数(无锚点)。
HTTP状态码
- 1xx:表示还在协议处理的中间状态,例如要建立websocket链接
- 2xx:表示成功,204与200相同,但响应头后没有body数据,206表示部分内容,用于HTTP分块下载和断点续传,搭配响应头字段
Content-Range - 301:永久重定向, 302:临时重定向,304:协商缓存命中
- 400:错误请求, 401:未授权, 403:禁止访问,405:请求方法不允许,408:超时
- 500:服务器错误, 503 服务器忙不可用
HTTP流式传输
判断数据流结束的方法
-
Content-Length 对于已知大小的数据,可以在请求头中添加。
-
Transfer-Encoding:chunk 分块发送,由一个标明长度为0的chunk标示结束。
每个Chunk由头+正文组成(
CRFL分割),头部内容指定正文的字符总数(16进制),正文就是实际内容
HTTP断点续传
HTTP1.1开始支持,通过Header的两个参数实现。客户端发送请求时对应Range,服务端响应Content-Range,同时响应头变成HTTP/1.1 206 Partial Content
Range: bytes=0-499 //以字节为单位,传输0到499字节范围的内容
👆请求----响应👇
Content-Range: bytes 0-499/22400 //0-499 是指当前发送的数据的范围,22400则是文件的总大小
Accept-Ranges: bytes // 服务器支持按字节下载
搭配If-Range可判断实体是否发生改变(判断Etag或者Last-Modified返回值)
补充:
前端使用localStorage记录已上传切片的Hash值。
HTTPS
HTTP协议通常承载于TCP协议之上,有时也承载于TLS或SSL协议层之上,这个时候,就成了我们常说的HTTPS。(TLS是更为安全的的升级版SSL)
Http+加密+认证+完整性保护=Https
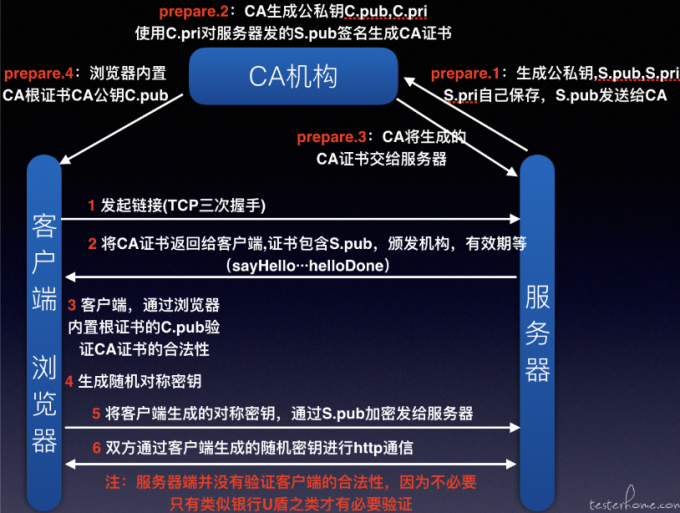
证书的验证:浏览器查找操作系统中内置的受信任证书颁发机构CA,与之对比。然后用CA的公钥,对服务端发来的证书进行解密。然后使用MD5验证数据是否被篡改。
HTTPS页面中发送HTTP请求
HTTP请求的默认会被浏览器阻止(Mixed Content错误),而不是跨域错误。
混合内容又分为主动混合内容和被动混合内容。
- 被动混合内容是指不与页面其余部分进行交互的内容,包括图像、视频和音频内容 ,以及无法与页面其余部分进行交互的其他资源。
- 主动混合内容指的是能与页面交互的内容,包括浏览器可下载和执行的脚本、样式表、iframe、flash、Ajax请求等
借助被动混合内容可以突破限制
const img = new Image();
img.src = 'http的请求地址'
HTTP2.0
增强核心便是二进制分帧层。
帧是最小通信单位。不同数据流(Stream)的帧可以交错发送(并发!),然后接收端根据帧头重新组装。之前HTTP/1x中,一个连接每次只能交互一个响应(串行)。
2.0的分帧突破了这个限制,这让级联文件,雪碧图,域名分片不是成为必要的优化。就这就是多路复用
二进制帧结构:https://juejin.cn/post/6844904100035821575#heading-97
其次是头部压缩:建立索引查表,让请求头字段得到极大程度的精简和服用,还利用霍夫曼编码对整数和字符串处理,压缩头部,减少大小。
最后就是服务端推送,比如在返回HTML的基础上,还把HTML引用的其他资源一起返回给客户端,减少客户端等待时间。
GET POST 区别
Cookie
每个cookie:name、value、Domain、Path、Expires/Max-Age、size、HttpOnly、Secure、SameSite、SameParty、Priority
Set-Cookie: session=abc123; SameSite=None
字段详解:
| 字段 | 解释 |
|---|---|
| Domain | 指定域(对子域生效),在指定域下的请求会携带此Cookie,需要.开始 |
| Path | 指定路径(对子路径生效),且同Domain,需要/结尾 |
| Expires/Max-Age | 有效期,一个是几点到期(GMT格式),另一个是能活多久(单位秒) |
| HttpOnly | true 或 false。true时不允许Javascript操作此cookie |
| Secure | true 或 false。true时在HTTPS下才传输此cookie |
| SameSite | Strict、Lax或None。用来限制第三方 Cookie(可以参考阮一峰的文章) |
Cookie 隔离
请求资源的时候不要让它带cookie怎么做,以此降低请求头大小
使用非主要域名
框架对比
共同点
两者都是数据驱动视图(声明式编程),组件化,单向数据流、虚拟DOM+基于key的同层diff,提升开发效率,还提供跨平台的能力。
不同点
Vue核心是数据跟视图绑定以及响应式编程,数据收集组件的render函数,数据可直接修改,在数据变化时以最小代价生成vnode并diff children,且内置功能多,自带编译优化。
react是函数式思想,推崇纯组件,数据不可变,通过js操作一切(api少,灵活),修改数据通过setState,当组件状态变化,以该组件为根,重新渲染整个组件子树。在超大量数据的首屏渲染速度上,React 有一定优势,因为 Vue 的渲染机制启动时候要做的工作比较多。生态很多,百花齐放。
React的更新粒度
在不优化的情况,所有层次都会重新render,生成VDOM并通过diff算法决定要更新的视图部分。不过利用Fiber提供异步渲染,进行弥补,利用memo和shouldComponentUpdate进行优化。
Vue的更新粒度
通过依赖收集对应组件进行精确更新。
当父组件更新时,会重新计算子组件的props,保证只有更变数据所对应的render被调用。
框架特性、生态、开发体验、社区评价、性能、源码等多个角度
聊聊 Redux 和 Vuex 的设计思想(未看)
https://github.com/Advanced-Frontend/Daily-Interview-Question/issues/45
Hooks
通常来说hook是特定事件下的所触发回调函数。在react中,hooks是一些列以“use"作为开头的方法,以在函数式组件中完成生命周期、状态管理、逻辑复用等能力。在vue中,hooks是以”use"开头的,一系列提供组件复用、状态管理等开发能力的方法。
hook对比mixins,可以更好的追溯属性的来源、避免属性冲突、多次使用、更高的代码聚合度,以提供更好的状态逻辑复用和代码阅读性。
其他
低代码
基于可视化和模型驱动的理念,减少代码量,降低开发成本。常见的有动态表单的创建。对于短期简单变动少的页面挺有帮助
微前端
微前端是一种类似于微服务的架构,是一种由独立交付的多个前端应用组成整体的架构风格,将前端应用分解成一些更小、更简单的能够独立开发、测试、部署的应用,而在用户看来仍然是内聚的单个产品。
简而言之,微前端就是将大而恐怖的东西切成更小、更易于管理的部分,然后明确地表明它们之间的依赖性。
需要一个主应用作为容器,通过路由切换到不同微应用。
https://juejin.cn/post/6854573213813473294
PWA
前端体系
解密国内BAT等大厂前端技术体系-完结篇(未看)
https://juejin.cn/post/6844904031798689806
测试驱动开发TDD
Canvas 和 SVG 区别
Canvas依赖分辨率,文本渲染能力弱,颜色丰富,适合图像密集型,方便保存图像
SVG(Scalable Vector Graphics)使用XML定义,基于矢量,易于编辑,有事件机制
Element 和 Node 区别
Node是基类,node是相对tree这种数据结构而言的。tree就是由node组成!
Element就是Node的子类,Text节点,document 也是Node的子类。Element扩展了更多的方法
HTMLCollection 和 NodeList
都是实时变动的(live)的伪数组,document上的更改会反映到相关对象上(例外:document.querySelectorAll返回的NodeList不是实时的)
MutationObserver
提供了监视对DOM树所做更改的能力,其监听是异步触发,在所有的DOM操作完成后才触发使回调函数进入微任务队列。
字符编码
ASCII:编码的规范标准
Unicode:将世界上的字符包含着一个集合中。是ASCII的超级。
而UTF-32、UTF-16、UTF-8 都是Unicode码的编码形式
UTF-8:用可变长度的字节来表示每个码点。
函数式编程
- 函数式编程是运算过程的抽象
- 函数式编程讲究就是一个纯,不能有副作用,无状态和数据不可变
- 可抽象出细粒度的函数,可以组合为更强大的函数
- 复用性好,方便测试和优化,方便理解
圈复杂度CC
圈复杂度(Cyclomatic complexity,CC)也称为条件复杂度,是一种衡量代码复杂度的标准,其符号为V(G)。
节点判定法:V (G) = P + 1,常见P(判定点):
- if 语句
- while 语句
- for 语句
- case 语句
- catch 语句
- and 和 or 布尔操作
- ? : 三元运算符
降低圈复杂度的方法
- 简化、合并条件表达式
- 将条件判定提炼出独立函数
- 将大函数拆成小函数
- 以明确函数取代参数
- 替换算法
正则表达式
贪婪(.)和惰性(.?)
iframe安全
iframe内容获取: iframe.contentWindow、iframe.contentDocument、window.frames['ifr1']
iframe获取父级内容: window.top(最顶级)、window.parent
嵌套检测:window.self === window.top | top.location.host === self.location.host(限定域名)
禁止被作为iframe: CSP、X-Frame-Options、framekiller,以下进行列举
- 设置HTTP响应头:
Content-Security-Policy:(frame-ancestors 'none | self | xx.com') - 设置HTTP响应头:
X-Frame-Options:(deny、sameorigin、allow-from xxx.com) - 写脚本进行嵌套检测
同源和跨域
同源:同源就是"协议+域名+端口"三者都相同
CORS:主要利用HTTP头的Access-Control-Allow-Origin 来指示请求的资源能共享给哪些域。
JSONP:只支持get,通过创建script并添加全局回调
proxy:反向代理,例如NGINX
server {
listen 80;
server_name client.com;
location /api {
proxy_pass server.com;
}
}
postMessage:H5 API 类似消息订阅机制,可在不同域的页面发送跨域消息
document.domain: 在同个基础域名的前提下,设置该属性为基础域名,实现不同页面间跨域操作
在chrome101版本中将要变成可读属性,添加Origin-Agent-Cluster
window.name: 可以直接操作该属性,因此可以向不同域的页面发送消息
软链接和硬链接
- 硬链接: 与普通文件没什么不同,
inode(指针)都指向同一个文件在硬盘中的区块。由文件系统维护一个引用计数,当计数为0时改文件才被释放。硬链接文件是文件的另一个入口 - 软链接: 保存了其代表的文件的绝对路径,是另外一种文件,在硬盘上有独立的区块,访问时替换自身路径。 软链接是另外一种类型的文件,在符号连接中,文件实际上是一个文本文件,其中包含的有另一文件的位置信息。(类似windows的快捷方式)
https://blog.csdn.net/weixin_43990363/article/details/121757838
线程与进程的区别,各自之间如何通信
进程 Process:
指在系统中正在运行的程序,是系统进行资源分配的最小单位。是指令、数据的集合。需要分配内存,每个程序至少一个主线程,同个进程中的线程并发执行。
线程 Thread:
是系统分配处理器(CPU)时间和调度的基本单元。是程序执行最小的单位, 需要分配栈。
通信
进程之间可以通过管道、消息队列(通过数据块交互)、共享内存、信号量(本质是个计数器,是个同步手段,以及Socket(比如微信跟微信服务器通信)等机制实现通信
线程之间主要通过共享变量
SourceMap理解
构建处理前以及处理后的代码之间的一座桥梁,方便定位bug出现的位置
开启source-map后文件末尾会保存map文件的url,map文件中,mappings属性保存这源码对应信息
第一层是行对应,以分号(;)表示,每个分号对应转换后源码的一行。所以,第一个分号前的内容,就对应源码的第一行,以此类推。
第二层是位置对应,以逗号(,)表示,每个逗号对应转换后源码的一个位置。所以,第一个逗号前的内容,就对应该行源码的第一个位置,以此类推。
第三层是位置转换,以VLQ编码表示,代表该位置对应的转换前的源码位置。
以"mappings": "AAAA;AACA,c"为例子,分号;分隔的内容是行对应,逗号,分隔前的转换后的位置对应,后面是转换前的位置,所有可以得出转换后的源码分成两行,第一行有一个位置,第二行有两个位置。字母由VLQ编码而成。
Webpack 中的 Source Map主要分为内联和外部两种。开发dev环境推荐eval-source-map内联速度也快,信息也完整些。
路由库原理Hash&History
Hash
- 原理是用
hashchange监听hash变化 # - URL中的hash部分不会被浏览器发出去
History H5
- 原理是用
popState监听URL的变化 - 利用H5提供的pushState 和 repalceState 两个 API 来操作实现 URL 的变化
- 对于原生a标签,可以拦截a标签的点击事件以支持URL变化监听
- 服务端要进行相应配置
try file,应对资源不存在时,返回默认index页面
调用history.pushState()或history.replaceState()不会触发popstate事件 (go back forward可以)
vue-router是监听当前url的变化(this.$router.data.current = to),让router-view动态渲染,对应组件
状态库原理
vuex将状态抽离到全局,形成一个Store,vuex内部利用vue的响应式功能来讲数据进行响应式化。与vue高度契合。useStore方法内部使用inject获取install vuex时provide的store
// in vuex/src/store-util.js
export function resetStoreState(store, state, hot){
// 使用 vue.reactive 定义响应式state
store._state = reactive({ data: state })
// 使用 vue.computed 缓存getter
computedCache[key] = computed(() => computedObj[key]())
}
XSS和CSRF
xss:攻击者在网站上注入的恶意代码,通常是存储型:例如评论中的script标签,可以检查输入输出和httpOnly进行防范。
- 对HTML标签转义
- 对于链接属性
href|src和事件方法,禁用恶意代码
csrf:利用(冒充)用户的cookie恶意发起请求,进行非用户预期请求的攻击,比如修改删除等。可用验证码,token严重,referer检查进行预防
User->黑网站->黑网站要求访问正常网站->正常网站不知道请求是用户自己主动发出的->接受了恶意请求
预渲染
https://zhuanlan.zhihu.com/p/395828896
https://juejin.cn/post/7046898330000949285
指在服务端完成页面的html拼接处理,然后发送浏览器。为了更好的SEO支持,以及更快的首屏渲染。
源码在经过Webpack build时,会分成两份,Server Bundle&Client Bundle
客户端阶段
同步服务端的一些状态数据,避免造成两端组件状态不一致,在挂载vue时,判断mount的dom是否含有data-server-rendered属性,如果有就跳过渲染阶段,执行组件生命周期的钩子。
前端错误监控
参考:前端项目使用Sentry错误监控实践#Sentry实现原理、前端错误监控指南、
错误类型
- 代码执行错误
- 资源加载错误
收集方案
-
window.onerror:能对语法异常和运行时异常处理,代码侵入性小
/** * @param {string} messsage 错误信息 * @param {string} source 引发报错的脚本url * @param {number} lineno 错误的行号 * @param {number} colno 错误的列号 * @param {object} error 错误的对象 */ window.onerror = function(message, source, lineno, colno, error) { ... } -
监听
unhandledrejection事件,能处理promise的错误 -
对于srcipt标签和img标签添加 onerror属性处理错误
-
vue框架可以实现实例的
errorHandler属性
上报方法
- 利用
navigator.sendBeacon - 利用图片方式上报
上报时机
- 页面加载、刷新、关闭、可见或路由切换
如何设计一个埋点功能
页面性能提升
前端性能涉及方方面面,优化角度切入点都有所不同。我认为,大的方向上不妨从:页面工程优化和代码细节优化两大方向切入。
- 选择合适的缓存策略,升级HTTP协议到HTTP/2
- 对于代码文件,文件名添加
hash值,文件名变化立即更新文件 - 对于频繁变动的资源,可以使用
Cache-Control: no-cache并配合ETag使用 - 对于无需缓存的资源 ,可以使用
Cache-control: no-store表示资源无需缓存 - HTTP2能更有效地使用 TCP 连接(多路复用),头部更小,对于首次访问可以主动推送相关资源,减少请求
- 对于代码文件,文件名添加
- webpack方面使用ES6开启
tree shaking、优化图片、代码/路由分割、代码压缩等 - 懒执行 & 懒加载 &预执行 & 预加载 (待补全)
- 图片配合CDN,根据屏幕宽度选择适合的图片资源(大小,格式等)
- 其他静态资源也使用CDN加载,即提高加载速度也避免占用单域名的并发请求(最大6个)
- 使用
requestAnimationFrame优化动画效果,更合理地控制动画更新频率 - 使用
Intersection Observer API代替Element.getBoundingClientReact检测元素是否出现 - 将长时间运行的 JavaScript 从主线程移到 Web Worker,帮忙完成一些计算工作。
- 使用
transform和opacity,will-change建立独立图层,减少paint涉及的范围 或者 减短渲染流水线 - 减少不合理的访问元素的布局属性或计算属性,避免触发Force Layout
参考:https://blog.towavephone.com/front-end-performance-optimization-2021/
前端性能优化总结(较全) https://zhuanlan.zhihu.com/p/350333912
前端页面性能优化总结(很多) https://zhuanlan.zhihu.com/p/433408114
从负一步开始的性能优化https://hpoenixf.com/posts/11026/
性能监控-埋点
(web beacon)
通常使用1px gif图(或直接new Image() )。好处如下:不造成阻塞,无需服务端有消息体回应,不会有跨域报错,执行过程无阻塞。服务端返回"204 No Content",即“服务器成功处理了请求,但不需要返回任何实体内容”。
还可以css实现埋点
.link:active::after{
content: url("/log?action=...");
}
<a class="link">点击链接发送买点数据</a>
性能监控-指标
const nav = window.performance.getEntries()[0]
const start = 0 // 统计起始点 建议从fetchStart开始
// dns解析时间
let dnsTime = nav.domainLookupEnd - nav.domainLookupStart
// tcp建立时间
let tcpTime = nav.connectEnd - nav.connectStart
// 请求发起到接收到第一个字节的数据的耗时(这里指index.html)
let resTime = nav.responseStart - nav.requestStart
// 从接收到第一个字节的数据到最后一个字节数据的耗时(下载时间)
let reqTime = nav.responseEnd - nav.responseStart
// 读取页面第一个字节的时间
let firstByteTime = nav.responseStart
// 白屏时间: 页面开始解析的时间,即将进入渲染环节
let blankTime = nav.domInteractive
// 解析dom花费的时长 dom.readyState从interactive变成complete的耗时
let domReadyTime = nav.domComplete - nav.domInteractive
// 当浏览器完成页面所有资源加载的耗时
let loadTime = nav.loadEventEnd

白屏时间
此时页面资源加载完成,即将进入渲染环节
首屏时间
首屏时间是指页面第一屏所有资源完整展示的时间,但难以统计衡量的指标。
具备一定意义上的指标可以使用,domContentLoadedEventEnd - fetchStart,甚至使用 loadEventStart - fetchStart ,此时页面DOM树已经解析完成并且显示内容。
数据监控-埋点
TODO
扫码登陆
简易原理
- 用户请求登陆的二维码图片,并生成一个uuid,作为该页面唯一标识,存入redis中
- 浏览器拿到二维码和uuid后就不断轮询查看该uuid是否已经登陆成功,是就跳转
- 手机端扫码后会将uuid和token提交给服务端,并把uuid 和userid 存储redis
- 轮询的具体就是看uuid和userid这个键值对是否存在,在就返回用户信息和token等
安全
二维码设置过期时间、限制二维码使用次数、二维码长度足够长,防止穷举、使用HTTPS
单点登陆
1、用户访问A系统,系统A发现用户未登录,跳转至sso认证中心,并把自己的地址作为参数。
2、sso认证中心发现用户未登录,则引导用户到登录页面。
3、用户输入用户名和密码提交登录。
4、sso认证中心验证用户信息,创建用户->sso之间的会话(全局会话),同时创建授权令牌。
5、sso认证中心带着令牌跳转到A系统
6、系统A拿到令牌,去sso认证中心校验令牌是否有效。
7、sso认证中心校验令牌,返回有效,注册系统A。
8、系统A使用该令牌创建与用户的会话(局部会话),返回请求资源。
9、用户访问系统B。
10、系统B发现用户未登录,跳转至sso认证中心,也将自己的地址作为参数。
11、sso认证中心发现用户已登录,跳转到系统B,并附上令牌。
12、系统B拿到令牌,去sso认证中心校验令牌是否有效。
13、sso认证中心校验令牌,返回有效,注册系统B。
14、系统B使用该令牌创建与用户的局部会话,返回请求资源。
OAuth2
OAuth 2.0 是一个授权协议,它允许软件应用代表(而不是充当)资源拥有者去访问资源拥有者的资源。应用向资源拥有者请求授权,然后取得令牌(token),并用它来访问资源,并且资源拥有者不用向应用提供用户名和密码等敏感数据。
参考
JS - 前端面试之道 - http://caibaojian.com/interview-map/frontend/
js常见面试题总结 - 大厂面试题每日一题
金九银十,你准备好面试了吗?(太多了,暂时没看) - https://juejin.cn/post/6996841019094335519
浏览器灵魂之问,请问你能接得住几个? - https://juejin.cn/post/6844904021308735502
浏览器渲染流程 - https://zhuanlan.zhihu.com/p/162722524
迟到的大厂前端面试记录(面试题+部分答案)- https://juejin.cn/post/7017655711291146253

 浙公网安备 33010602011771号
浙公网安备 33010602011771号