
#Sprapy爬虫框架初了解
Scrapy的安装
cmd命令提示符下: 执行pip install scrapy命令
maybe你会用到的指令或安装(如果用pip指令安装不了,你可以在CSN或度里面找资源):
- pip install Django
- install win32api
- install mysql-python
Scrapy爬虫框架结构
- 爬虫框架是实现爬虫功能的一个软件结构和功能组件结构
- 爬虫框架是一个半成品,能够帮助用户实现网络爬虫
5+2结构
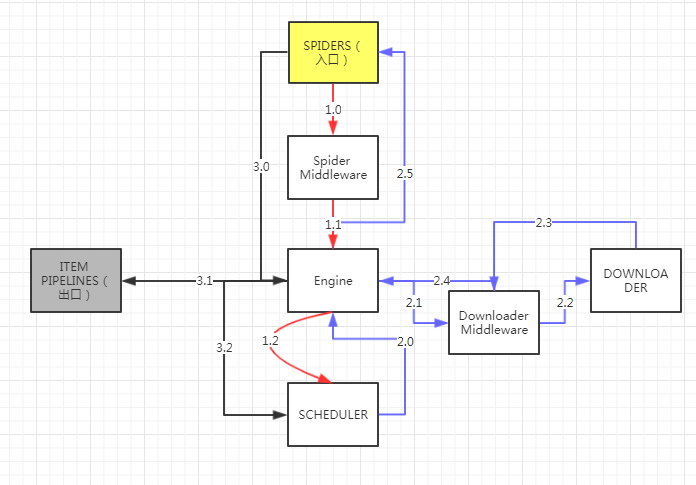
-
ENGINE(发动机) 不需要用户修改
- 控制所有模块之间的数据流
- 根据条件出发事件
-
SCHEDULER(调度程序)不需要用户修改
- 对所有爬取请求进行调度管理
-
ITEM PIPELINES (项目管道组件)
- 以流水线方式处理Spider产生的爬取项。
- 由一组操作顺序组成,类似流水线,每个操作是一个Item Pipeline类型
- 操作包括:对Item内容 清理、检验、查重爬取项中的HTML数据、将数据存储到数据库
-
SPIDERS(蜘蛛侠) 用户主要编写
- 解析Downloader返回的响应(Response)
- 产生爬取项(scraped item)
- 产生额外的新的爬取请求(Request)
-
DOWNLOADER (下载侠)不需要用户修改
- 根据用户提供的请求下载网页
- 根据用户提供的请求向网络中提交一个请求,最终获得返回的一个内容
-
中间键1 Downloader Middleware
- 目的:实施Engine ->Downloader这段过程时进行用户可配置的控制
- 功能:修改、丢弃、新增请求或响应
-
中间键2 Spider Middleware
- 目的:对Spiders和Engine之间的Request、Response、和Item操作进行处理
- 功能:修改、丢弃、新增请求或爬取项
3条主要数据流路径
-
SPIDERS->ENGINE->SCHEDULER
-
SCHEDULER->ENGINE->DOWNLOADER->ENGINE->SPIDERS
-
SPIDERS->ENGINE->ITEM PIPELINES & SCHEDULER
Requests vs Scrapy
相同点
- 都可以进行页面请求和爬取,Python爬虫的两个重要技术路线
- 可用性都好,文档丰富,入门简单
- 都没有处理JS、提交表单、应对验证码等功能
不同点
- Request:页面级爬虫、功能库、并发性考虑不足、性能差、重点在于页面下载、定制灵活、上手十分简单。
- Scrapy:网站级爬虫、框架、并发性好,性能较高、重点在于爬虫结构、一般定制灵活,深度定制困难、入门稍难。
选择哪个技术路线开发爬虫
- 小需求,requests库
- 不小的需求,Scrapy框架
- 定制成都很高的需求,自搭框架,Requests>Scrapy
scrapy帮助命令行
scrapy -h
常用命令
-
startproject 创建一个新工程
-
genspider 创建一个爬虫
-
settings 获得爬虫配置信息
-
crawl 运行一个爬虫
-
list 列出工程中所有爬虫
-
shell 启用url调试命令行
