并发编程之:synchronized
大家好,我是小黑,一个在互联网苟且偷生的农民工。
之前的文章中跟大家分享了关于Java中线程的一些概念和基本的使用方法,比如如何在Java中启动一个线程,生产者消费者模式等,以及如果要保证并发情况下多线程共享数据的访问安全,操作的原子性,使用到了synchronized关键字。今天主要和大家聊一聊synchronized关键字的用法和底层的原理。
为什么要用synchronized
相信大家对于这个问题一定都有自己的答案,这里我还是要啰嗦一下,我们来看下面这段车站售票的代码:
/**
* 车站开两个窗口同时售票
*/
public class TicketDemo {
public static void main(String[] args) {
TrainStation station = new TrainStation();
// 开启两个线程同时进行售票
new Thread(station, "A").start();
new Thread(station, "B").start();
}
}
class TrainStation implements Runnable {
private volatile int ticket = 10;
@Override
public void run() {
while (ticket > 0) {
System.out.println("线程" + Thread.currentThread().getName() + "售出" + ticket + "号票");
ticket = ticket - 1;
}
}
}
上面这段代码是没有做考虑线程安全问题的,执行这段代码可能会出现下面的运行结果:
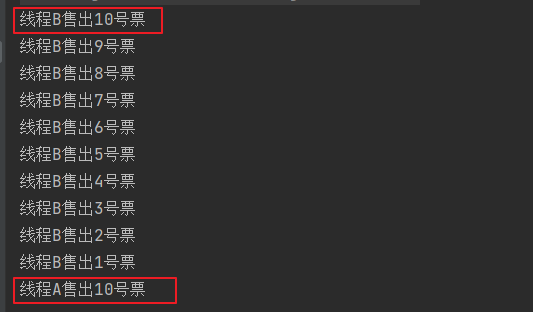
可以看出,两个线程都买出了10号票,这在实际业务场景中是绝对不能出现的。(你去坐火车有个大哥说你占了他的座,让你滚,还说你是票贩子,你气不气)
那因为有这种问题的存在,我们应该怎么解决呢?synchronized就是为了解决这种多线程共享数据安全问题的。
使用方式
synchronized的使用方式主要以下三种。
同步代码块
public static void main(String[] args) {
String str = "hello world";
synchronized (str) {
System.out.println(str);
}
}
同步实例方法
class TrainStation implements Runnable {
private volatile int ticket = 100;
// 关键字直接写在实例方法签名上
public synchronized void sale() {
while (ticket > 0) {
System.out.println("线程" + Thread.currentThread().getName() + "售出" + ticket + "号票");
ticket = ticket - 1;
}
}
@Override
public void run() {
sale();
}
}
同步静态方法
class TrainStation implements Runnable {
// 注意这里ticket变量声明为static的,因为静态方法只能访问静态变量
private volatile static int ticket = 100;
// 也可以直接放在静态方法的签名上
public static synchronized void sale() {
while (ticket > 0) {
System.out.println("线程" + Thread.currentThread().getName() + "售出" + ticket + "号票");
ticket = ticket - 1;
}
}
@Override
public void run() {
sale();
}
}
字节码语义
通过程序运行,我们发现通过synchronized关键字确实可以保证线程安全,那计算机到底是怎么保证的呢?这个关键字背后到底做了些什么?我们可以看一下java代码编译后的class文件。首先来看同步代码块编译后的class。通过javap -v 名称可以查看字节码文件:
public static void main(java.lang.String[]);
descriptor: ([Ljava/lang/String;)V
flags: ACC_PUBLIC, ACC_STATIC
Code:
stack=2, locals=4, args_size=1
0: ldc #2 // String hello world
2: astore_1
3: aload_1
4: dup
5: astore_2
6: monitorenter // 监视器进入
7: getstatic #3 // Field java/lang/System.out:Ljava/io/PrintStream;
10: aload_1
11: invokevirtual #4 // Method java/io/PrintStream.println:(Ljava/lang/String;)V
14: aload_2
15: monitorexit // 监视器退出
16: goto 24
19: astore_3
20: aload_2
21: monitorexit
22: aload_3
23: athrow
24: return
注意看第6行和第15行,这两个指令是增加synchronized代码块之后才会出现的,monitor是一个对象的监视器,monitorenter代表这段指令的执行要先拿到对象的监视器之后,才能接着往下执行,而monitorexit代表执行完synchronized代码块之后要从对象监视器中退出,也就是要释放。所以这个对象监视器也就是我们所说的锁,获取锁就是获取这个对象监视器的所有权。
接下来我们在看看synchronized修饰实例方法时的字节码文件是什么样的。
public synchronized void sale();
descriptor: ()V
//方法标识ACC_PUBLIC代表public修饰,ACC_SYNCHRONIZED指明该方法为同步方法
flags: ACC_PUBLIC, ACC_SYNCHRONIZED
Code:
stack=3, locals=1, args_size=1
0: aload_0
1: getfield #2 // Field ticket:I
// 省略其他无关字节码
可以看到synchronized修饰实例方法上之后不会再有monitorenter和monitorexit指令,而是直接在这个方法上增加一个ACC_SYNCHRONIZED的flag。当程序在运行时,调用sale()方法时,会检查该方法是否有ACC_SYNCHRONIZED访问标识,如果有,则表明该方法是同步方法,这时候还行线程会先尝试去获取该方法对应的监视器(monitor)对象,如果获取成功,则继续执行该sale()方法,在执行期间,任何其他线程都不能再获取该方法监视器的使用权,知道该方法执行完毕或者抛出异常,才会释放,其他线程可以重新获得该监视器。
那么synchronized修饰静态方法的字节码文件是什么样呢?
public static synchronized void sale();
descriptor: ()V
flags: ACC_PUBLIC, ACC_STATIC, ACC_SYNCHRONIZED
Code:
stack=3, locals=0, args_size=0
0: getstatic #2 // Field ticket:I
// 省略其他无关字节码
可以看出synchronized修饰静态方法和实例方法没有区别,都是增加一个ACC_SYNCHRONIZED的flag,静态方法只是比实例方法多一个ACC_STATIC标识代表这个方法是静态的。
以上的同步代码块,同步方法中都提到对象监视器这个概念,那么三种同步方式使用的对象监视器具体是哪个对象呢?
同步代码块的对象监视器就是使用的我们synchronized(str)中的str,也就是我们括号中指定的对象。而我们在开发中增加同步代码块的目的是为了多个线程同一时间只能有一个线程持有监视器,所以这个对象的指定一定要是多个线程共享的对象,不能直接在括号中new一个对象,这样不能做到互斥,也就不能保证安全。
同步实例方法的对象监视器是当前这个实例,也就是this。
同步静态方法的对象监视器是当前这个静态方法所在类的Class对象,我们都知道Java中每个类在运行过程中也会用一个对象表示,就是这个类的对象,每个类有且仅有一个。
对象锁(monitor)
上面说了线程要进入同步代码块需要先获取到对象监视器,也就是对象锁,那在开始说之前我们先来了解下在Java中一个对象都由哪些东西组成。
这里先问大家一个问题,Object obj = new Object()这段代码在JVM中是怎样的一个内存分布?
想必了解过JVM知识的同学应该都知道,new Object()会在堆内存中创建一个对象,Object obj是栈内存中的一个引用,这个引用指向堆中的对象。那么怎么知道堆内存中的对象到底由哪些内容组成呢?这里给大家介绍一个工具叫JOL(Java Object Layout)Java对象布局。可以通过maven在项目中直接引入。
<dependency>
<groupId>org.openjdk.jol</groupId>
<artifactId>jol-core</artifactId>
<version>0.9</version>
</dependency>
引入之后在代码中可以打印出对象的内存分布。
public static void main(String[] args) {
Object obj = new Object();
// parseInstance将对象解析,toPrintable让解析后的结果可输出
System.out.println(ClassLayout.parseInstance(obj).toPrintable());
}
输出后的结果如下:
java.lang.Object object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 01 00 00 00 (00000001 00000000 00000000 00000000) (1)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) e5 01 00 f8 (11100101 00000001 00000000 11111000) (-134217243)
12 4 (loss due to the next object alignment)
Instance size: 16 bytes
Space losses: 0 bytes internal + 4 bytes external = 4 bytes total
从结果上可以看出,这个obj对象主要分4部分,每部分的SIZE=4代表4个字节,前三行是对象头object header,最后一行的4个字节是为了保证一个对象的大小能是8的整数倍。
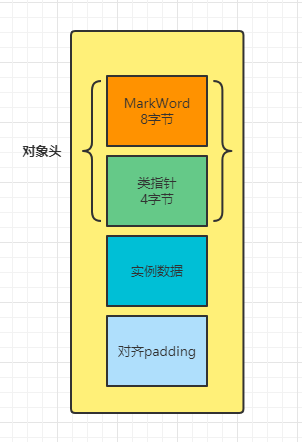
我们再来看看对于一个加了锁的对象,打印出来有什么不一样?
public static void main(String[] args) {
Object obj = new Object();
synchronized (obj){
System.out.println(ClassLayout.parseInstance(obj).toPrintable());
}
}
java.lang.Object object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 58 f7 19 01 (01011000 11110111 00011001 00000001) (18478936)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) e5 01 00 f8 (11100101 00000001 00000000 11111000) (-134217243)
12 4 (loss due to the next object alignment)
Instance size: 16 bytes
Space losses: 0 bytes internal + 4 bytes external = 4 bytes total
可以很明显的看到,最前面的8个字节发生了变化,也就是Mark Word变了。所以给对象加锁,实际就是改变对象的Mark Word。
Mark Word中的这8个字节具有不同的含义,为了让这64个bit能表示更多信息,JVM将最后2位设置为标记位,不同标记位下的Mark word含义如下:
|------------------------------------------------------------------------------|--------------------|
| Mark Word (64 bits) | State |
|------------------------------------------------------------------------------|--------------------|
| unused:25 | identity_hashcode:31 | unused:1 | age:4 | biased_lock:1 | lock:2 | 无锁态 |
|------------------------------------------------------------------------------|--------------------|
| thread:54 | epoch:2 | unused:1 | age:4 | biased_lock:1 | lock:2 | 偏向锁 |
|------------------------------------------------------------------------------|--------------------|
| ptr_to_lock_record:62 | lock:2 | 轻量级锁 |
|------------------------------------------------------------------------------|--------------------|
| ptr_to_heavyweight_monitor:62 | lock:2 | 重量级锁 |
|------------------------------------------------------------------------------|--------------------|
| | lock:2 | GC标记 |
|------------------------------------------------------------------------------|--------------------|
其中最后两位的锁标记位,不同值代表不同含义。
| biased_lock | lock | 状态 |
|---|---|---|
| 0 | 00 | 无锁态(NEW) |
| 0 | 01 | 偏向锁 |
| 1 | 01 | 偏向锁 |
| 0 | 00 | 轻量级锁 |
| 0 | 10 | 重量级锁 |
| 0 | 11 | GC标记 |
biased_lock标记该对象是否启用偏向锁,1代表启用偏向锁,0代表未启用。
age:4位的Java对象年龄。在GC中,如果对象在Survivor区复制一次,年龄增加1。当对象达到设定的阈值时,将会晋升到老年代。默认情况下,并行GC的年龄阈值为15,并发GC的年龄阈值为6。由于age只有4位,所以最大值为15,这就是-XX:MaxTenuringThreshold选项最大值为15的原因。
identity_hashcode:25位的对象标识Hash码,采用延迟加载技术。调用方法System.identityHashCode()计算,并会将结果写到该对象头中。当对象被锁定时,该值会移动到管程Monitor中。
thread:持有偏向锁的线程ID。
epoch:偏向时间戳。
ptr_to_lock_record:指向栈中锁记录的指针。
ptr_to_heavyweight_monitor:指向管程Monitor的指针。
锁升级过程
既然会有无锁,偏向锁,轻量级锁,重量级锁,那么这些锁是怎么样一个升级过程呢,我们来看一下。
新建
从前面讲到对象头的结构和我们上面打印出来的对象内存分布,可以看出新创建的一个对象,它的标记位是00,偏向锁标记(biased_lock)也是0,表示该对象是无锁态。
偏向锁
偏向锁是指当一段同步代码被同一个线程所访问时,不存在其他线程的竞争时,那么该线程在以后访问时便会自动获得锁,从而降低获取锁带来的消耗,提高性能。
当一个线程访问同步代码块并获取锁时,会在 Mark Word 里存储线程 ID。在线程进入和退出同步块时不再通过 CAS 操作来加锁和解锁,而是检测 Mark Word 里是否存储着指向当前线程的偏向锁。轻量级锁的获取及释放依赖多次 CAS 原子指令,而偏向锁只需要在置换 ThreadID 的时候依赖一次 CAS 原子指令即可。
轻量级锁
轻量级锁是指当锁是偏向锁的时候,有其他线程来竞争,但是该锁正在被其他线程访问,那么就会升级为轻量级锁。或者还有一种情况就是关闭JVM的偏向锁开关,那么一开始锁对象就会被标记位轻量级锁。
轻量级锁考虑的是竞争锁对象的线程不多,而且线程持有锁的时间也不长的情景。因为阻塞线程需要CPU从用户态转到内核态,代价较大,如果刚刚阻塞不久这个锁就被释放了,那这个代价就有点得不偿失了,因此这个时候就干脆不阻塞这个线程,让它自旋这等待锁释放。
在进入同步代码时,如果对象锁状态符合升级轻量级锁的条件,虚拟机会在当前想要竞争锁的线程的栈帧中开辟一个Lock Record空间,并将锁对象的Mark Word拷贝到Lock Record空间中。
然后虚拟机会使用CAS操作尝试将对象的Mark Word更新为指向Lock Record的指针,并将Lock Record中的owner指针指向对象的Mark Word。
如果操作成功,则表示当前线程获得锁,如果失败则表示其他线程持有该锁,当前线程会尝试使用自旋的方式来重新获取。
轻量级锁解锁时,会使用CAS操作将Lock Record替换回到对象头,如果成功,则表示没有竞争发生。如果失败,表示当前锁存在竞争,锁就会膨胀成重量级锁。
重量级锁
重量级锁是指当有一个线程获取锁之后,其余所有等待获取该锁的线程都会处于阻塞状态。是依赖于底层操作系统的Mutex实现,Mutex也叫互斥锁。也就是说重量级锁会让锁从用户态切换到内核态,将线程的调度交给操作系统,性能相比会很低。
整个锁升级的过程通过下面这张图能更全面的展示。

有需要原图的朋友,关注我的公众号【小黑说Java】后台回复“锁升级”获取。
好的,今天的内容就到这里,我们下期再见。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号