1.逻辑回归是怎么防止过拟合的?为什么正则化可以防止过拟合?(大家用自己的话介绍下)
A 逻辑回归是怎么防止过拟合
1. 增加样本量,这是万能的方法,适用任何模型。
2. 如果数据稀疏,使用L1正则,其他情况,用L2要好,可自己尝试。
3. 通过特征选择,剔除一些不重要的特征,从而降低模型复杂度。
4. 如果还过拟合,那就看看是否使用了过度复杂的特征构造工程,比如,某两个特征相乘/除/加等方式构造的特征,不要这样做了,保持原特征
5. 检查业务逻辑,判断特征有效性,是否在用结果预测结果等。
B 为什么正则化可以防止过拟合
特征变量过多会导致过拟合,为了防止过拟合会选择一些比较重要的特征变量,而删掉很多次要的特征变量。以sigmoid为例,当w趋于0时(忽略偏置b),激活值趋于0,此时位于激活函数的线性趋于,神经网络就变成一个线性网络,不容易过拟合。
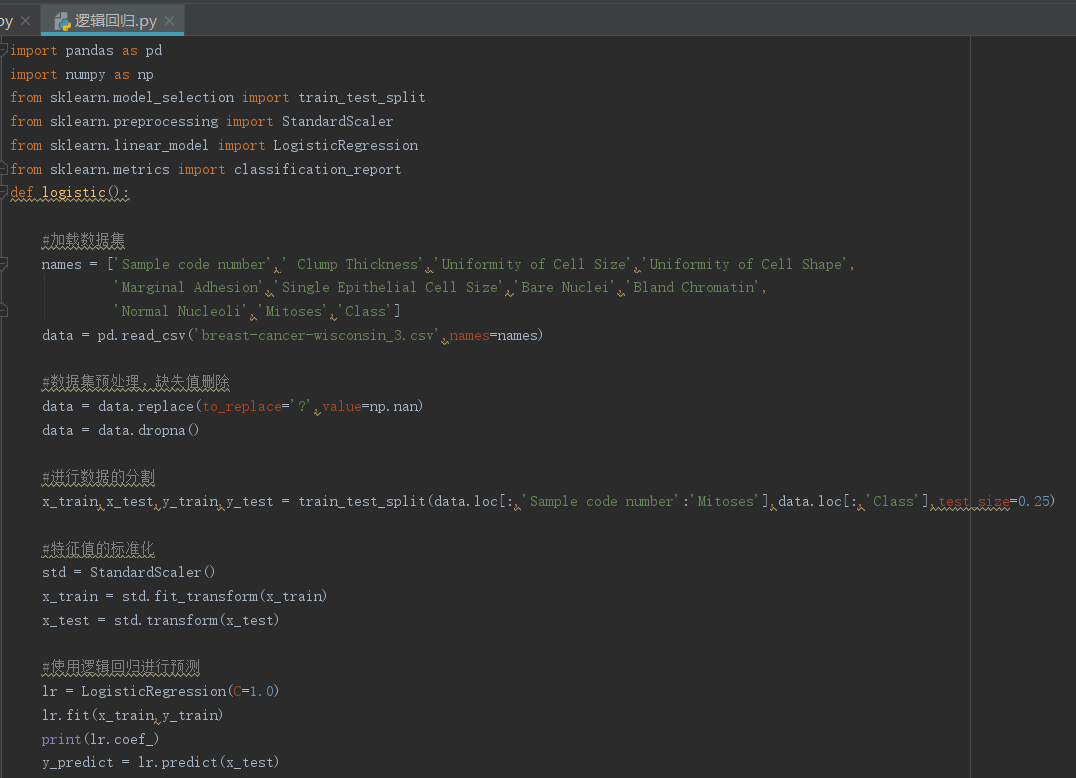
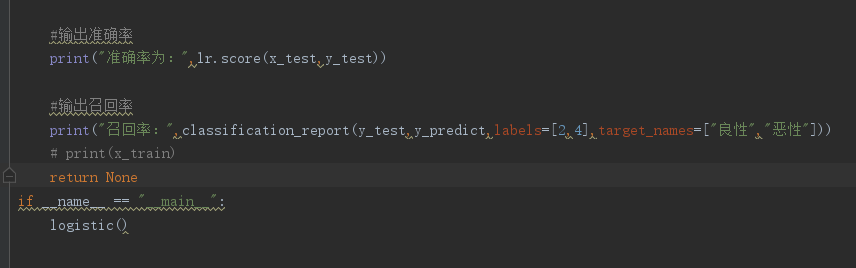
2.用logiftic回归来进行实践操作,数据不限。
采用老师提供的数据表
代码:
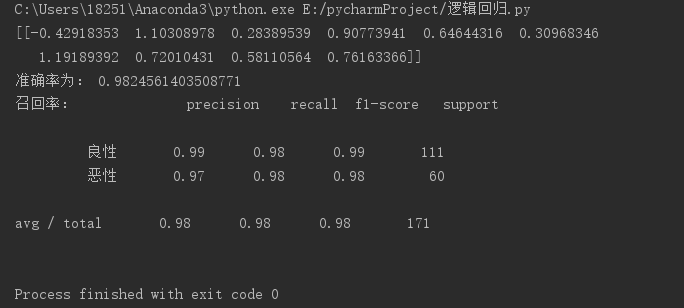
运行结果: