实现Keepalived高可用项目架构
Keepalived的作用是检测服务器 的状态,如果有一台web服务器宕机 ,或工作出现故障,Keepalived将检 测到,并将有故障的服务器从系统中 剔除,同时使用其他服务器代替该服 务器的工作,当服务器工作正常后 Keepalived自动将服务器加入到服务 器群中,这些工作全部自动完成,不 需要人工干涉,需要人工做的只是修 复故障的服务器。
Keepalived基础
Keepalived基本概念和技术概括
高可用(High Availability )高可用集群,英文原文为High Availability Cluster,简称HA Cluster,简单的说,集群(cluster)就是 一组计算机,它们作为一个整体向用户提供一组网络资源。这些单个的计算 机系统 就是集群的节点(node)。高可用性集群(HA cluster)是指如单系统一样地运行并支持(计算机)持续正常运行的一个主机群。 高可用集群的出现是为了使集群的整体服务尽可能可用,从而减少由计算机 硬件和软件易错性所带来的损失。如果某个节点失效,它的备援节点将在几 秒钟的时间内接管它的职责。因此,对于用户而言,集群永远不会停机。高可用集群软件的主要作用就是实现故障检查和业务切换的自动化。
高可用(High Availability ) HA(High Available), 高可用性群集是通过系统的可靠性(reliability)和可维护性(maintainability)来度量的。工程上,通常用平均无故障时间(MTTF) 来度量系统的可靠性,用平均维修时间(MTTR)来度量系统的可维护性。于 是可用性被定义为:
HA=MTTF/(MTTF+MTTR)*100%
具体HA(可用性)衡量标准:
99% 一年宕机时间不超过4天
99.9% 一年宕机时间不超过10小时
99.99% 一年宕机时间不超过1小时
99.999% 一年宕机时间不超过6分钟
高可用工作方式: 主从方式 (非对称方式)、双机双工方式(互备互 援)、集群工作方式(多服务器互备方式)
高可用的资源分类:网络高可用、服务器高可用、存储高可用、服务 高可用等
开源高可用解决方案:
- keepalived:通过实现vrrp协议来实现地址 漂移;
- heartbeat(开源社区项目),cman+rgmanager (RHCS: redhat cluster suite);
- corosync+pacemaker(大型解决方案, 一个用于心跳检测,一个用于资源转移。两个结合起来使用,可以实现对高可用架构的自动管理。)
Keepalived的原理和配置
配置文件简单:配置文件比较简单,可通过简单配置实现高可用功能
稳定性强:keepalived是一个类似于layer3, 4 & 7交换机制的软件 ,具备我们平时说的第3层、第4层和第7层交换机的功能,常用于前端负载均衡器的高可用服务,当主服务器出现故障时,可快速进 行切换,监测机制灵活,成功率高。
成本低廉:开源软件,可直接下载配置使用,没有额外费用。
应用范围广:因为keepalived可应用在多个层面,所以它几乎可以对所有应用做高可用,包括LVS、数据库、http服务、nginx负载均衡等等
支持多种类型:支持主从模式、主主模式高可用,可根据业务场景 灵活选择。
Keepalived工作流程图
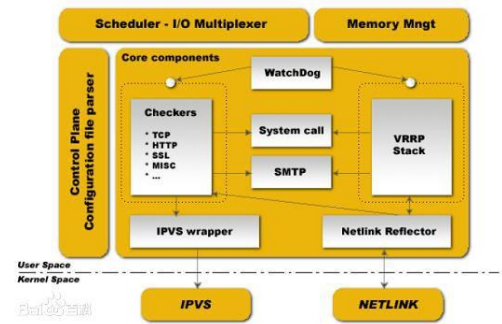
如上图,keepalived主要是模块是VRRP Stack和Cheackers,实现HA集群中失败切换(Failover)功能。
Keepalived通过VRRP功能能再结合LVS负载均 衡软件即可部署一个高性能的负载均衡集群系统。Cheackers主要实现可 实现对服务器运行状态检测和故障隔离。,其中ipvs和realserver健康状态检 查通过配置文件配置就可以实现,而其他服务高可用则需要通过自己编写脚本,然后配置keepalived调用来实现。
Keepalived运行有3个守护进程。父进程主要负责读取配置文件初始化 、监控2个子进程等;然后两个子进程,一个负责VRRP,另一个负责 Cheackers健康检查。其中父进程监控模块为WacthDog,工作实现:每个子进程打开一个接受unix域套接字,父进程连接到那些unix域套接字并向子 进程发送周期性(5s)hello包。
上图是Keepalived的功能体系结构,大致分两层:用户空间(user space) 和内核空间(kernel space)。 内核空间:主要包括IPVS(IP虚拟服务器,用于实现网络服务的负载均衡) 和NETLINK(提供高级路由及其他相关的网络功能)两个部份。
VRRP(Virtual Router Redundancy Protocol,虚拟路由冗余协议) 可以认为是实现路由器高可用的协议,简单的说,当一个路由器故障时可以 由另一个备份路由器继续提供相同的服务。 VRRP根据优先级来确定虚拟路由器中每台路由器的角色(Master路由 器或Backup路由器)。VRRP优先级的取值范围为0到255(数值越大表明 优先级越高),可配置的范围是1到254,优先级0为系统保留给路由器放弃 Master位置时候使用,255则是系统保留给IP地址拥有者使用。优先级越高 ,则越有可能成为Master路由器。当两台优先级相同的路由器同时竞争 Master时,比较接口IP地址大小。接口地址大者当选为Master。
Keepalived的应用场景
在网络层、数据链路层,运行着4个重要的协议:互联网协议IP、互联网控制报文协议 ICMP、地址转换协议ARP以及反向地址转换协议RARP。Keepalived在网络层采用的最常见的工作方式是通过ICMP协议向服务器集群中的那个节点发送一个ICMP数据包(类 似于ping实现的功能),如果某个节点没有返回响应数据包,那么认为此节点发生了故 障,Keepalived将报告次节点失效,并从服务器集群中剔除故障节点。 在传输层,提供了两个主要的协议:传输控制协议TCP和用户数据协议UDP。传输控制 协议TCP可以提供可靠的数据传输服务、Ip地址和端口代表TCP的一个连接端。要获得 TCP服务,需要在发送机的一个端口上和接收机的一个端口上建立连接,而Keepalived 在传输层就是利用TCP协议的端口连接和扫描技术来判断集群点是否正常的。比如,对于常见的WEB服务默认的80端口、SSH服务默认的22端口等,Keepalived一旦在传输 层探测到这些端口没有响应数据返回,就认为这些端口发生异常,然后强制将此端口对应得节点从服务器集群组中移除。 在应用层,可运行FTP、TELNET、HTTP、DNS等各种不同类型的高层协议, Keepalived的运行方式也更加全面化和复杂化,用户可以通过自定义Keepalived的工作方式;例如:用户可以通过编写程序来运行keepalived。而keepalived将根据用户的设 定检测各种程序或服务是否运行正常,如果Keepalived的检测结果与用户设定不一致时 ,Keepalived将把对应的服务从服务器中移除。
Keepalived软件包组成
程序包:Keepalived可直接yum安装
/etc/keepalived/keepalived.conf #主配置文件
/etc/rc.d/init.d/keepalived #启动脚本
/etc/sysconfig/keepalived #启动时的添加参数
/usr/sbin/keepalived #启动程序
Keepalived配置文件讲解
global_defs { #全局配置 notification_email { #realserver故障时通知邮件的收件人地址,可 以多个 root@localhost } notification_email_from root_keepalived #发件人信息(可以随意伪装,因为邮件系统不会验证处理发件人信息) smtp_server 127.0.0.1 #发邮件的服务器(一定不可为外部地址) smtp_connect_timeout 30 #连接超时时间 router_id KEEPALIVED #路由器的标识(可以随便改动) } vrrp_instance VI_1 { #配置虚拟路由器的实例,VI_1是自定义的实例名称 state MASTER #初始状态,当state指定的instance的初始化状态,两台服务器都启动后,优先级高的成为MASTER, 这里的MASTER并不是表示此台服务器一直是MASTER interface eth0 #通告选举所用端口 virtual_router_id 51 #虚拟路由的ID号(一般不可大于255) priority 101 #优先级信息 #备节点必须更低 advert_int 1 #VRRP通告间隔,秒 authentication { auth_type PASS #认证机制 auth_pass 5344 #密码(尽量使用随机) } nopreempt #非抢占模式(NOTE: For this to work, the initial state of this entry must be BACKUP.) virtual_server 192.168.18.240 80 { #设置一个virtual server:VIP:Vport delay_loop 3 # service polling的delay时间,即服务轮询的时间间隔 lb_algo rr #LVS调度算法:rr|wrr|lc|wlc|lblc|sh|dh lb_kind DR #LVS集群模式:NAT|DR|TUN #persistence_timeout 120 #会话保持时间(持久连接,秒),即以用户在120秒内被分配到同一个后端 realserver nat_mask 255.255.255.255 protocol TCP #健康检查用的是TCP还是UDP real_server 192.168.18.251 80 { #后端真实节点主机的权重等设置, 主要,后端有几台这里就要设置几个 weight 1 #给每台的权重,rr无效 # inhibit_on_failure #表示在节点失败后,把他权重设置成0,而不是IPVS中删除 url { path / status_code 200 } TCP_CHECK { connect_timeout 2 #连接超时时间 nb_get_retry 3 #重连次数 delay_before_retry 1 #重连间隔 } } }
Keepalived进阶
实现keepalived企业级高可用基于LVS-DR模式的应用实战
lvs-server-master VIP:172.18.64.7 DIP:172.18.64.100 开启路由功能配置,
keepalived lvs-server-backup VIP:172.18.64.107 DIP:172.18.64.100 开启路由功能配置
keepalived rs01 RIP:172.18.64.17 VIP:172.18.64.100
keepalived rs02 RIP:172.18.64.106 VIP:172.18.64.100
master和backup端只需配置配置文件和路由功能即可,rip端需要手动加lo:0的IP、广播、路由等(参见lvs)
实现keeaplived故障通知机制
在企业中,高可用服务,是保证整个系统稳定性的重要前提,确 保高可用服务能正常工作和运转,也是非常重要的工作。 除了服务上线前的充分测试之外,也需要确保对高可用服务的监 控机制,keepalived自身具备监控和通知机制,可在发生主从切换 、故障转移时,通过自定义命令或者脚本,实现通知功能,从而让 管理员在第一时间得知系统运行状态,确保整个服务的稳定性和可 用性。
可在配置文件中,在instance配置中,通过keepalived通知功能notify,可 实现定制化脚本功能,如下所示:
notify_backup "/etc/keepalived/notify.sh
backup" notify_master "/etc/keepalived/notify.sh
master" notify_fault "/etc/keepalived/notify.sh fault"
实现keeaplived故障通知机制脚本:
#!/bin/bash
contact='root@localhost' notify() {
mailsubject="$(hostname) to be $1: vip floating" mailbody="$(date +'%F %H:%M:%S'): vrrp transition, $(hostname) changed to be $1"
echo $mailbody | mail -s "$mailsubject" $contact
}
case $1 in
master)
notify master
exit 0
;;
backup)
notify backup
exit 0
;;
fault)
notify fault
exit 0
;;*)
echo "Usage: $(basename $0) {master|backup|fault}" exit 1
;;
esa
实现keeaplived自定义脚本功能
vrrp_script chk_down {
script “[[ -f /etc/keepalived/down ]] && exit 1 || exit 0 ”
interval 2 # check every 2 seconds
weight -5
}
track_script {
chk_down
}
在配置文件中,可实现以下配置,定义一个脚本,并在对应的实例中调用, 也可以用于检测服务是否有异常,异常的话进行切换
vrrp_script chk_sshd {
script "killall -0 sshd" # cheaper than pidof
interval 2 # check every 2 seconds
weight -4 # default prio: -4 if KO
fall 2 # require 2 failures for KO
rise 2 # require 2 successes for OK
}
track_script {
chk_sshd
}
实现keepalived主主架构和主从模式基本相同,就是多加一对instance而已,且互为主从。
思考问题:
1、keepalived是做什么用的?
2、如何实现keepalived高可用功能?
3、keepalived的抢占模式和非抢占模式区别?
4、keepalived实现高可用是基于什么协议的?
5、如何写keepalived状态切换脚本?
6、keepalived如何实现基于lvs的高可用功能?
7、keepalived和heartbeat都可实现高可用,区别是什么?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号