

2020年寒假假期总结0119
爬取首都之窗信件列表保存到TXT(下)
按照上一篇的操作,我们便可以得到之前列表页整个一页的操作了,当我们想要实现下一页操作的时候我们发现网页的地址并没有发生变化,也就是说下一页的按钮只是调动了js方法,从服务器端获取了数据,然后再重新对页面进行了刷新。打开检查,查看network可以看到传输的数据:
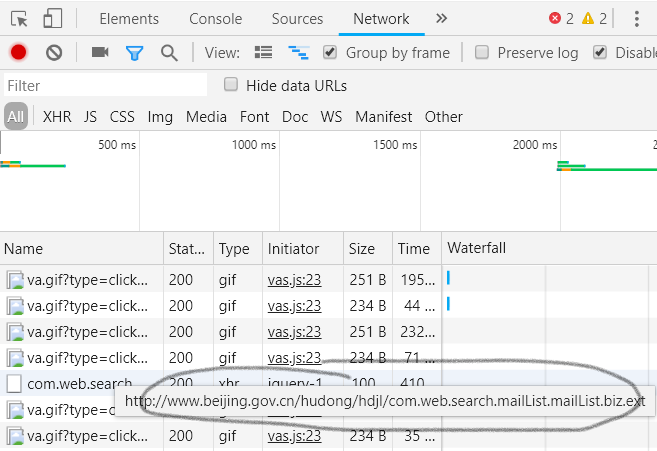
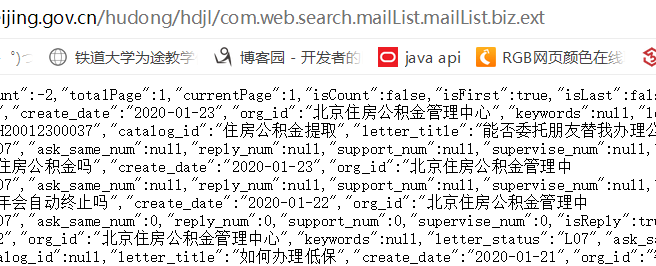
从而验证了我的想法,但是如何获取这些数据呢?最后选择了selenium库来实现浏览器自动化。首先添加依赖:


<dependency>
<groupId>org.seleniumhq.selenium</groupId>
<artifactId>selenium-java</artifactId>
<version>3.141.59</version>
</dependency>
注意点:这里选择的浏览器的火狐,所以我们需要从github上面下载火狐浏览器的驱动:geckodriver,地址:https://github.com/mozilla/geckodriver/releases这里我们就下载最新版就可以了,注意自己的操作系统和位数,另外安装的火狐浏览器版本不要过高,否则驱动器可能在打开之后无法输入网址进行跳转。
private void AddNewPage(Page page){ //定义gecko driver的获取地址 String driverPath="E:/geckodriver/geckodriver.exe"; System.setProperty("webdriver.gecko.driver",driverPath); //如果火狐浏览器没有默认安装在C盘,需要自己确定其路径 System.setProperty("webdriver.firefox.bin", "C:\\Program Files\\Mozilla Firefox\\firefox.exe"); //创建一个叫driver的对象,启动火狐浏览器 WebDriver driver=new FirefoxDriver(); driver.get("http://www.beijing.gov.cn/hudong/hdjl/com.web.search.mailList.flow"); /** Selenium 执行JS*/ String js = "beforeTurning("+Utils.Page+")"; ((FirefoxDriver) driver).executeScript(js); String PageSourse=null; try { //线程暂停一段时间,防止网速过慢超时连接失败 Thread.sleep(1000); System.out.println("Page数值为:"+Utils.Page); Utils.Page++; PageSourse=driver.getPageSource(); } catch (InterruptedException e) { e.printStackTrace(); } if(PageSourse!=null){ try { AddUrl(driver,page); }catch (Exception e){ System.out.println("Error!!"); }finally { driver.close(); } } } private void AddUrl(WebDriver driver,Page page){ List<WebElement> listType=driver.findElements(By.cssSelector("div#mailul a")); System.out.println("元素的个数为:"+listType.size()); for (WebElement e:listType ) { AddTargetRequest(e,page); } } private void AddTargetRequest(WebElement e,Page page){ String onClick=e.getAttribute("onclick"); String[] list=onClick.replace("letterdetail('","").replace("')","").split("','"); if(list[0].equals("建议")){ String NewUrl="http://www.beijing.gov.cn/hudong/hdjl/com.web.suggest.suggesDetail.flow?originalId="+list[1]; page.addTargetRequest(NewUrl); }else if(list[0].equals("咨询")){ String NewUrl="http://www.beijing.gov.cn/hudong/hdjl/com.web.consult.consultDetail.flow?originalId="+list[1]; page.addTargetRequest(NewUrl); }else if(list[0].equals("投诉")){ String NewUrl="http://www.beijing.gov.cn/hudong/hdjl/com.web.complain.complainDetail.flow?originalId="+list[1]; page.addTargetRequest(NewUrl); } }
因为selenium驱动的是真正的浏览器,所以并不需要添加header。这样就获取了下一页的信件中的网址,然后再依据前文对网址详情页的信件信息进行爬取即可。
