

2020年寒假假期总结0118
爬取首都之窗信件列表保存到TXT(上)
我们需要对首都之窗的界面元素进行确定,打开网页进行元素检查可以发现:

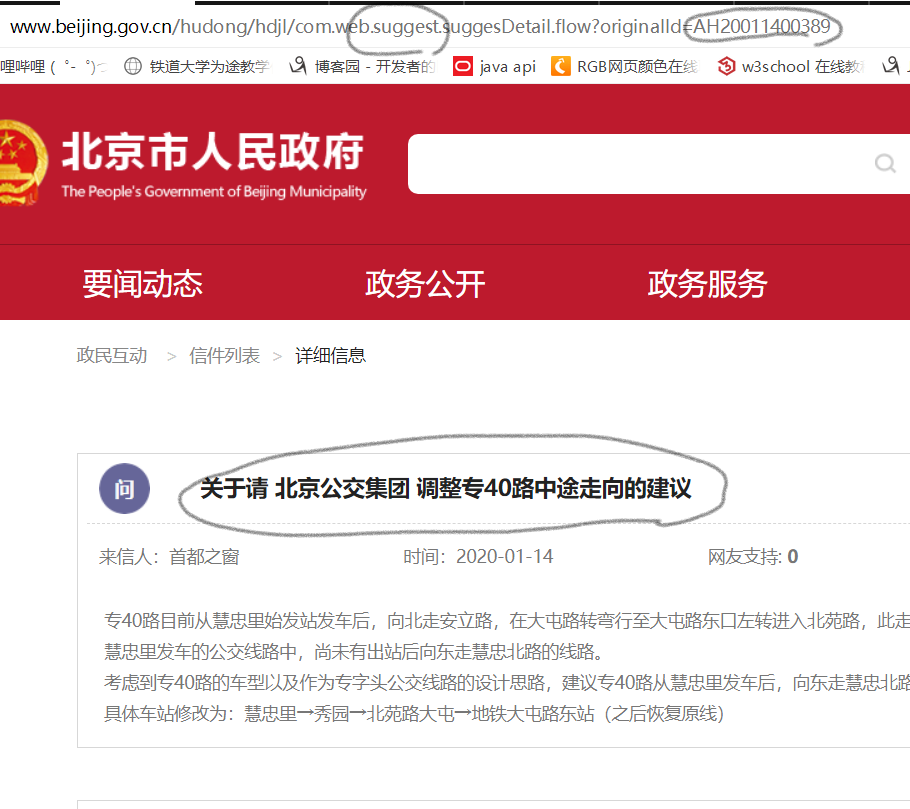
这样我们就发现了信件详情页和信件列表页之间的关系,所以想要从列表页跳转至详情页我们只需要获取整个a标签的onclick属性就可以了,或者是从a标签中提取出信件类型,和SugID也是可以的。
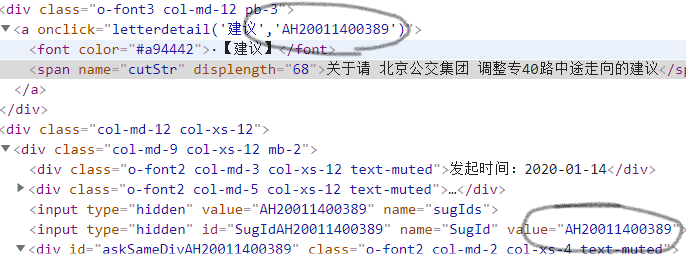
这里我们先使用后者,这是一开始最先使用的方法,后面也会提到前者。代码如下:
List<String> listType = page.getHtml().regex("·【(.*?)】").all(); List<String> listID =page.getHtml().regex("name=\"SugId\" value=\"(.*?)\">").all();
在先前的测试中会发现爬取会有些问题,爬取的有时候不是我们需要的,我们需要加上一个判断,两个数量都要大于1,防止爬取错了。
这样我们就获取了详情页的网址的最重要的参数,然后使用字符串拼接为网址,我们打开网页源代码可以看到,信件类型分为三种:

所以剩下的就是拼接网址,并且将这些网址加入爬取的队列:page.addTargetRequest(NewUrl);


if(listType.get(i).equals("建议")){ String NewUrl="http://www.beijing.gov.cn/hudong/hdjl/com.web.suggest.suggesDetail.flow?originalId="+listID.get(i); page.addTargetRequest(NewUrl); }else if(listType.get(i).equals("咨询")){ String NewUrl="http://www.beijing.gov.cn/hudong/hdjl/com.web.consult.consultDetail.flow?originalId="+listID.get(i); page.addTargetRequest(NewUrl); }else if(listType.get(i).equals("投诉")){ String NewUrl="http://www.beijing.gov.cn/hudong/hdjl/com.web.complain.complainDetail.flow?originalId="+listID.get(i); page.addTargetRequest(NewUrl); }
进而我们进入信件的详情页,对要爬取的元素进行检查,这里便不再赘述,由于代码是写的有点早,在css选择器上使用产生了误解,所以就不贴出来了,我们可以通过检查看到,class的属性名大多都含有空格,所以我们只需要将空格替换成 .(点)即可,这样就可以准确的抓取,这是后期才发现的。
然后将爬取的数据都放到一个bean中进行保存,最后写到TXT文件中。
