
Lecture 09 Cache
motivation:Memory Wall
CPU速度比内存的速度快,但数据和指令只能来源于内存。因此内存墙会极大地限制处理器的性能。
Cache algorithm
基本思路
- 在CPU和主存之间添加一块较小而快的cache
- 可以集成在cpu内部或位于主板上
- cache中存放了主存中部分信息的副本
工作流程
-
检查:CPU试图访问主存中的某个字时,首先检查字是否在cache中
-
处理:
-
命中:如果在cache中,则把这个字传给cpu
-
未命中:将主存中包含这个字的固定大小的块读入cache中,再从cache传送该字给cpu
并不是直接从主存中读取,不是直接读取这个字
-
如何判断是否命中?
未命中时为什么不直接读取,为什么不只读取一个字?
使用Cache多了很多中间步骤,为什么还会节省时间?
判断是否命中
CPU通过位置唯一标记一个字,因此在Cache中存放数据时,不仅需要存放数据内容,还需要存放它的位置
Cache通过标记 tags来标识位置
未命中时操作的解释
\(Lemma\) 程序访问的局部性原理
处理器频繁访问主存中相同位置或相邻位置的现象(并不总是成立,比如多维数据按行存放时按列访问)
- 时间局部性:在相对较短的时间周期内,重复访问特定的信息(相同位置)
- 空间局部性:在相对较短的时间周期内,访问相邻存储位置的数据(相邻位置)
- 当数据被线性排列和访问时会出现顺序局部性
利用了cpu对内存的访问的规律,而不是简单地作为随机访问处理
-
利用时间局部性
对于未命中的数据,先把其放在Cache中,由时间局部性可知在短期内可能会重复访问,再访问时就可以直接命中。
-
利用空间局部性
未命中时,将目标字所在的块放在cache中,由空间局部性可知在短期内附近的数据可能会被访问,此时就可以直接命中。
Cache效率的讨论
\(T_A=p*T_C+(1-p)*(T_C+T_M)\)
\(=T_C+(1-p)*T_M\)
为了保证使用Cache效率变高:
\(T_A<T_M\rightarrow p>\frac{T_C}{T_M}\)
在利用了程序局部性原理后,p很高接近1,因此平均访问时间\(T_A\)接近\(T_C\)
因此一顿操作看似很复杂,但实际还是提升了效率。
Design
Cache的设计要素
- 容量
- 映射功能
- 替换算法
- 写策略
- 行大小
- Cache数目
容量
扩大容量的结果:
- 提高命中率
- 成本上升,增加了访问时间\(T_C\)
为什么会增加访问时间?
主存的访问是随机的,不同地址对应的访问时间几乎一样。但访问cache则类似于查找,因此容量越大,每次寻找的时间就变大。
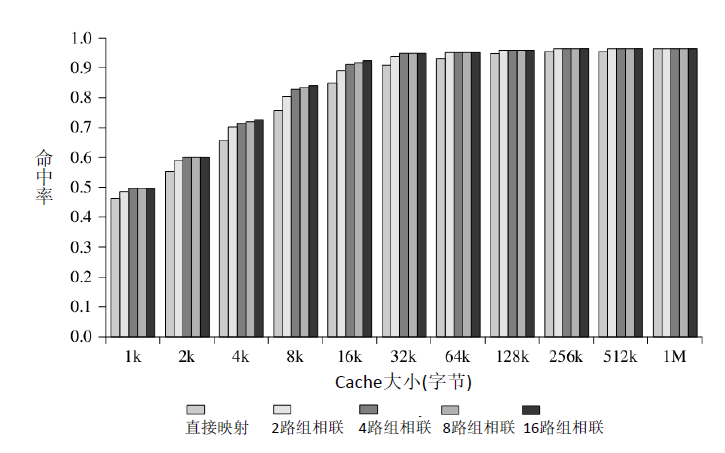
为什么随着Cache大小增加,命中率增加变缓?
cache较小时不利于命中的原因:
- Cache中可容纳的块数很少,需要频繁更新。当下次访问之前访问过的内容时,已经被替换了,不能充分利用时间局部性原理,命中率降低。
- 提高Cache可容纳块数,但降低单个块的大小。这样就不能充分地利用空间局部性原理,命中率降低。
上述两个原因都是因为限制了程序局部性原理的利用,而程序局部性原理也有一定的范围(即“局部”的大小),当Cache大小能够Cover掉这个范围时,再增加Cache大小收益就没那么高了。
映射
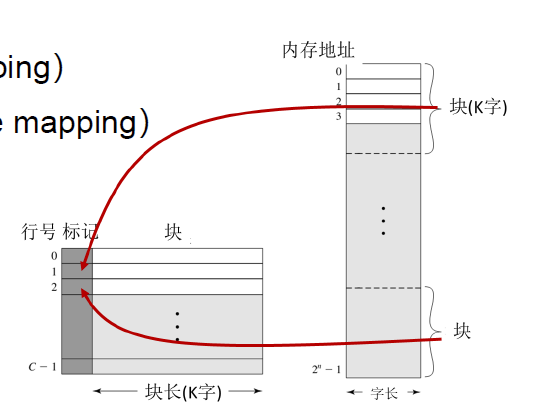
如何编块号?
对于确定的块大小\(2^k\),同一个块的低\(k\)位不同而高位相同,且不同块之间高位不同。故可直接取高位作为块号。
映射策略
直接映射
映射方式
主存中的每个块映射到一个固定可用的cache行中。
映射规则显然有很多,该如何选择一个合理的规则?
采用同余来确定映射到同一行的块
\(i = j\space mod\space C\), 其中\(i\)为cache行号,\(j\)为块号, \(C\)是cache行数
这样的设计保证了连续的块分别映射在不同的行中,因为根据局部性原理,访问完一块后,访问相邻块的概率更大。
标记位
标记位的作用:标识该行的块号。但由于取模的映射规则,可能储存在同一行的块低\(log_2C\)位相同。故\(n=log_2M-log_2C\)
一个主存地址就被拆分成了下图:

优缺点分析
- 简单,映射迅速,检查快速(由上图可知,直接从主存地址取中间几位就能得到需要映射到的cache行号,而从标记得到块号也是常数级)
- 会产生抖动现象,如果一个程序反复访问两个需要映射到同一行中且来自不同块的字,则命中率降低。
适合大容量cache
电路级实现
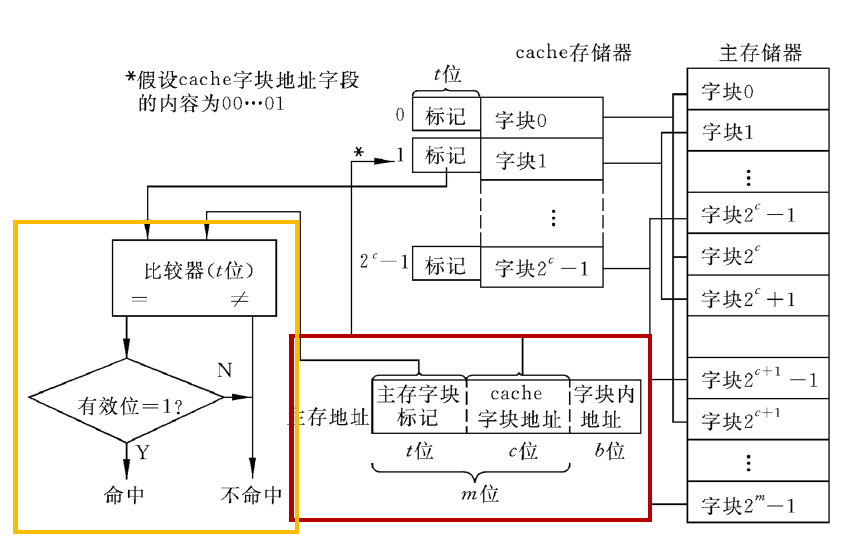
- 映射:直接取地址高\(t\)位得到cache中标记位,再将块内数据存入数据区。
- 检查:将cache中标记位和行号取出与访存地址高\(t+c\)位比较
关联映射
映射方式
一个块装入cache任意一个空行
标记位
由于没有直接映射的规律性,因此标记位必须保存完整的块号。

优缺点
- 避免抖动
- 实现较为复杂,检查时需要遍历每一行。
适合容量较小的cache
组关联映射
映射方式
Cache分成若干组,每个组包含相同数量的行,每个主存块被映射到固定组的任意一行(结合上面两种方式)
s是组号,j是块号,S是组数
K-路组关联映射
C是cache行数,S是组数,K是每组内的行数
标记位
标记位\(n=log_2M-log_2S\)

优缺点
折中方案,吸收了上述两种优缺点
不同映射方式的比较
-
相关性
\(K=1\), 组关联等同于直接映射
\(K=C\), 组关联等同于关联映射 -
关联度:一个块在cache中可能存放的位置个数
- 关联度越低,命中率越低,检查时间越短,标记所占额外空间越小
替换算法
一旦cache行被占用,当新的数据块装入cache中时,原先存放的数据块将会被替换掉。对于直接映射,没有选择的机会,而对于关联映射和组关联映射,每个数据块有多种选择,这就需要替换算法来决定替换哪一行。(通过硬件来实现)
基本思路:替换掉当前行中最不可能再被访问的行
最近最少使用算法
假设:最近使用过的数据块更有可能会被再次使用
策略:替换掉在cache中最长时间未被访问(since last use)的数据块。(序:距离上次使用的时间)
实现:\(K=2\)
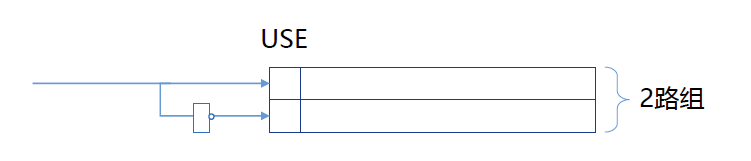
每行包含一个USE位,当同一组的某行被访问时,将其USE位设为1,同时将另一行的USE位设为0.当新的数据块读入该组时,替换掉USE为0的数据块。
\(K=2\)时,最长时间未被使用所蕴含的时序关系退化为两种状态,即上次使用和上次未使用,不需要保存更复杂的时序信息。
先进先出算法
假设:最近由主存载入Cache的数据块更有可能被使用
策略:替换掉Cache中停留时间最长的块(序:进入Cache的时间 )
实现:ring buffer
为了实现ring buffer只需要一个header标识下一个被替换的行即可。当一行被替换时,标识位设为1,下一行设为0,如果替换的是最后一行则第一行设为0。每次替换标识位为0的行。
为什么需要一次设置两行的标识位?
在写程序时,可以采用一个变量记录当前header的位置。但这里设计硬件算法时,为了降低复杂性,不去采用一个额外的“变量”记录header位置(这可能需要锁存器译码器等),而是将header的信息嵌入行内(使得header行有别于其它行即可)。为了达到这个目的,每次替换时,将原来的header修改为普通状态,将下一行修改为header状态。
最不经常使用算法
假设:访问越频繁的数据块越有可能被再次使用
策略:替换掉cache中被访问次数最少的数据块(序:访问次数)
实现:为每一行设置计数器(较为复杂)
随机替换算法
假设:每个数据块被再次使用的可能性相同
策略:随机替换
有趣的是,看似要求极低的随机替换算法,性能上只稍逊于使用其它替换算法。
写策略
前面对于cache的讨论都集中于“读”这一访存操作。而cache中的数据只是主存中数据的副本,这就存在“写操作”如何同步的问题。
cpu总是优先访问cache,因此写也是优先更新cache中的数据。当cache中的数据被修改时,下次再访问还是通过cache。但当它被替换时就需要考虑一致性问题(不考虑并行)。
- 没被修改,则可直接被替换。
- 修改过,需要写回到主存
有两种写回方式
写直达
所有写操作都同时对cache和主存进行
主存中的数据总是和cache中的数据一致,但会产生大量对主存的访问操作
多核并行时,这种时刻一致性是必要的。同时还要求主存更新时通知另一个cpu的缓存更新。
写回法
先更新cache中的数据,当cache中某个数据块被替换时,如果修改了则写回主存。
利用一位表示块是否被修改
- 减少了访问主存的次数
- 部分主存数据可能不是最新的,I/O模块存取时可能无法获得最新的数据
行大小
行大小对应于块的大小
假设cache的容量一定,行的大小增加对命中率是先增加后减小(近似,实际是很复杂的)的作用。
假设行的大小从一个字增加到cache容量
- 一开始行的较小,行数较大。随着行大小的增加,每次有更多相邻的数据作为一个块装入,命中率提升。与此同时,行数减小也利于时间局部性的发挥(行数较大时,装入的数据很久没有更新,白占了cache)
- 当行大小增加到一定大小时,较大的行会导致Cache中的行数变少,数据块的数量减少进而造成数据块被频繁替换(抖动性)。与此同时,每个数据块包含的数据在主存中的位置扁圆,不利于空间局部性发挥(与上述类似都是浪费了cache)
Cache数目
多级Cache
一级Cache与处理器置于同一芯片,减少了处理器在外部总线上的活动。
多级Cache之间的关系
当前一级cache未命中时,访问下一级cache
分立Cache
- 统一的Cache:更高的命中率,在获取指令和数据的负载之间自动进行平衡
- 分立的Cache:消除流水线中产生的数据竞争

 浙公网安备 33010602011771号
浙公网安备 33010602011771号