微服务架构设计基础之立方体模型
背景
对于现在的微服务架构的应用来说,对大量并发的及时响应是一项制胜能力。据用户行为分析平台统计,随行付的某一款APP产品每日请求就达到上千万次用户请求、加解密服务3000万次/日等等。这些微服务每时每刻在处理如此高强度的请求,对数据层的应对能力要求极高。如果我们把对速度的需求放在复杂的分布式数据架构背景下,是很难想象如何让应用应对如此巨大的数据访问量的。但很幸运,我们有方法做到。即立方体模型。
立方体模型
可扩展的分布式系统架构设计有一个朴素的理念,就是:通过加机器就可以解决容量和可用性的问题。
对于一个迅速增长的应用而言,容量和性能是首当其冲要面临的问题。但随着时间的向前推移、应用规模不断的快速增长,除了面对性能与容量的问题外,还需要解决功能与模块数量上增长带来的系统复杂性问题、业务变化带来的差异化服务问题等。而多数情况下应用设计之初出于诸多因素的考量,并没有充分考虑或在设计之初就将此类问题提上日程,导致系统的重构成为常态,从而影响业务交付能力。对此,「架构即未来」一书中提出了更加系统的可扩展模型,可扩展模型是一个富有启发性的方法,描述了微服务三个维度的扩展方法,可以通过它来了解微服务架构的扩展维度。
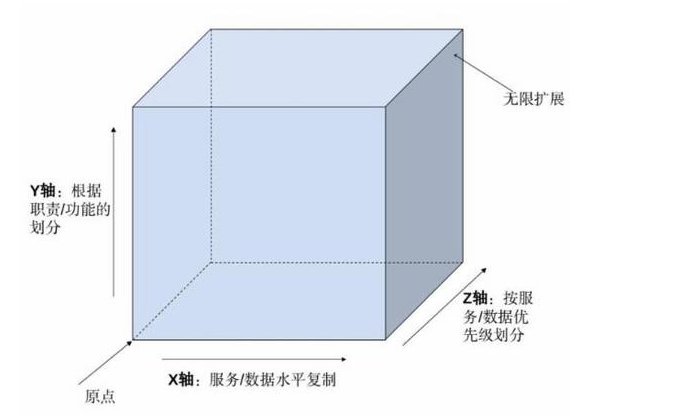
- X轴:横向扩展模式,关注水平的数据和服务克隆
- Y轴:功能分解模式,关注应用中的职责的划分
- Z轴:数据分区模式,关注服务和数据的优先级划分
X轴扩展
X轴扩展是通过绝对平等的复制服务和数据,以解决容量和可用性的问题。以乘坐火车为例,因春运高峰集中,乘客人数也是平时时的几倍、甚至几十倍。12306为了提高运力都会采用复制的方法:增加火车数量。增加火车数量有效的提高春运运力、提高乘客出行体验。
对于软件工程而言,比如加解密微服务的性能峰值1000TPS,通常我们需要提高TPS,会采取复制加解密服务:增加服务提供者。这就是X轴扩展的一个完美示例,说明了X轴扩展的思路,把工作无偏向的分配给「复制品」,各个「复制品」之间不共享任何内容、能独立提供服务。而对于软件技术来讲,X轴扩展主要有负载均衡和数据复制两种技术方式。
负载均衡
负载均衡是将用户的访问请求通过负载均衡器,均衡分配到由各个「复制品」组成的集群中去。当某个「复制品」出现故障,也能轻易地将相应「工作」转移给其它的复制品来「代为完成」。常用的硬件负载有F5、A10,软件负载Nginx。
这中间涉及到的技术点包括了反向代理、DNS轮询、哈希负载均衡算法(一致性哈希)、动态节点负载均衡(如按CPU,I/O)等。它的难点在于要求集群中的「复制品」是不共享任何内容,也就是我们常说的无状态。
数据复制
数据复制是指在数据存储层进行绝对平等地数据迁移,用于解决存储层I/O瓶颈以及可用性上的问题。有多个「复制品」存储,使得每个「复制品」提供无差异的数据服务,我们需要在「复制品」之间同步或异步的复制数据。
数据复制的方式包括了主从同步(读写分离)、双主同步等。因为数据存储天生就是有状态的,数据复制的难点在于如何保证一致性。为保证一致性,衍生了很多复杂的技术和中间件,比如Paxos选举算法、随行付Porter数据同步中间件等。
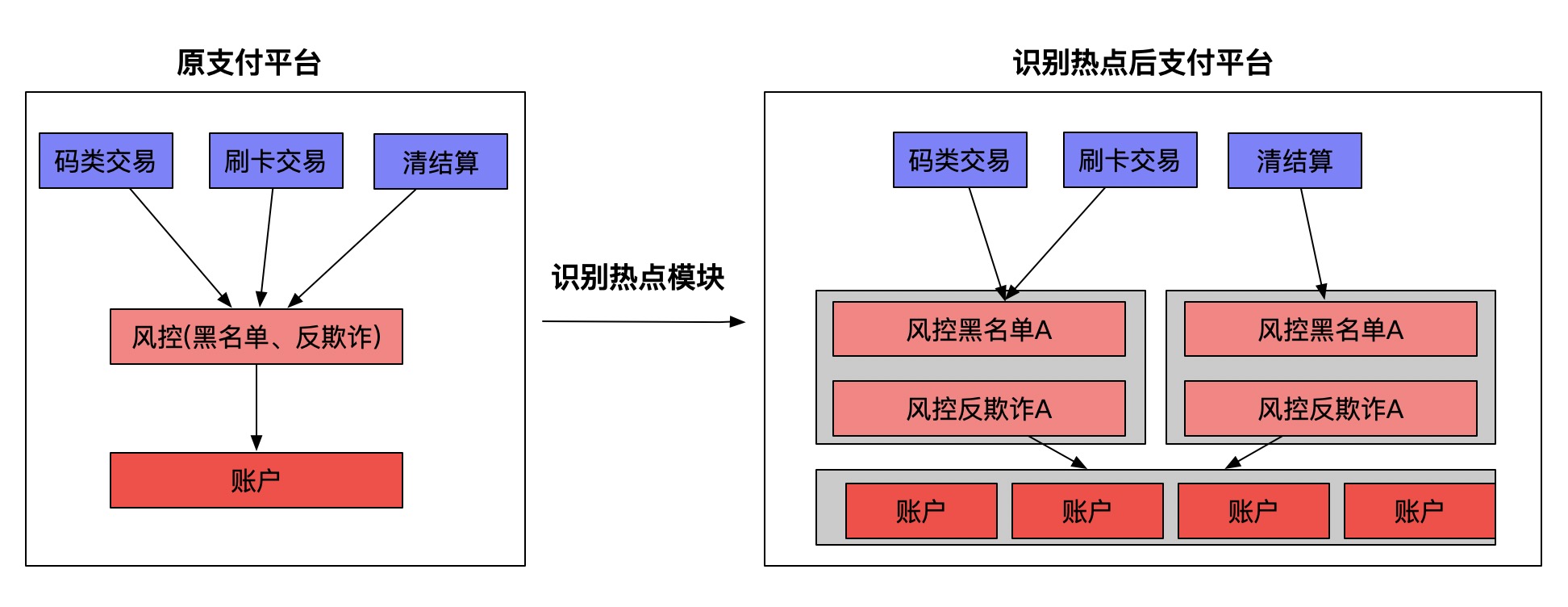
识别热点服务
多数情况下我们的应用中都会存在热点模块,我们可以理解为越基础的模块越容易成为热点模块。热点模块更加容易成为整个平台的瓶颈点,所以热点模块要尽早的采取扩展措施,扩展措施一般都采用X轴扩展方式。
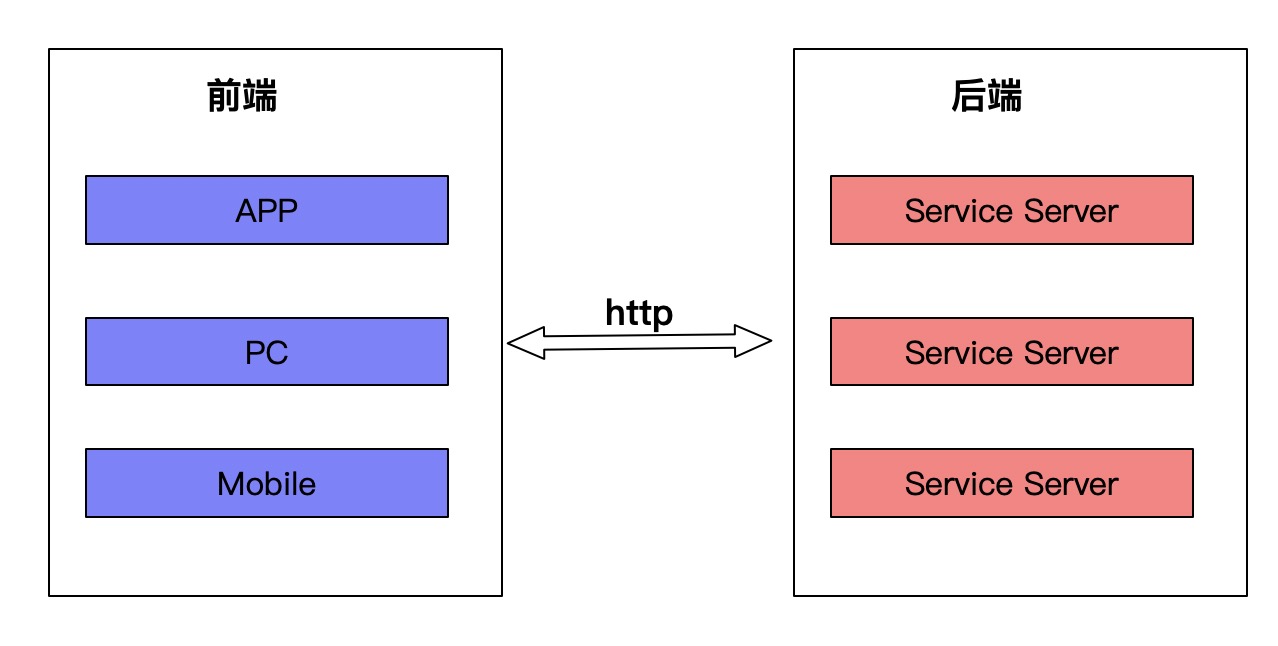
前后端分离
其实在我们开发过程中,经常会给pc端、mobile、app端各自研发一套前端。其实对于这三端来说,大部分端业务逻辑是一样的。唯一区别就是交互展现逻辑不同。如果controller层在后端手里,后端为了这些不同端页面展示逻辑,分别维护这些controller,徒增和前端沟通端成本、在扩展性上面也不能达到很方便的扩展。前后端分离的好处在于:
- 提升适配性
- 提升响应速度
- 提升性能(分后端可分别优化)
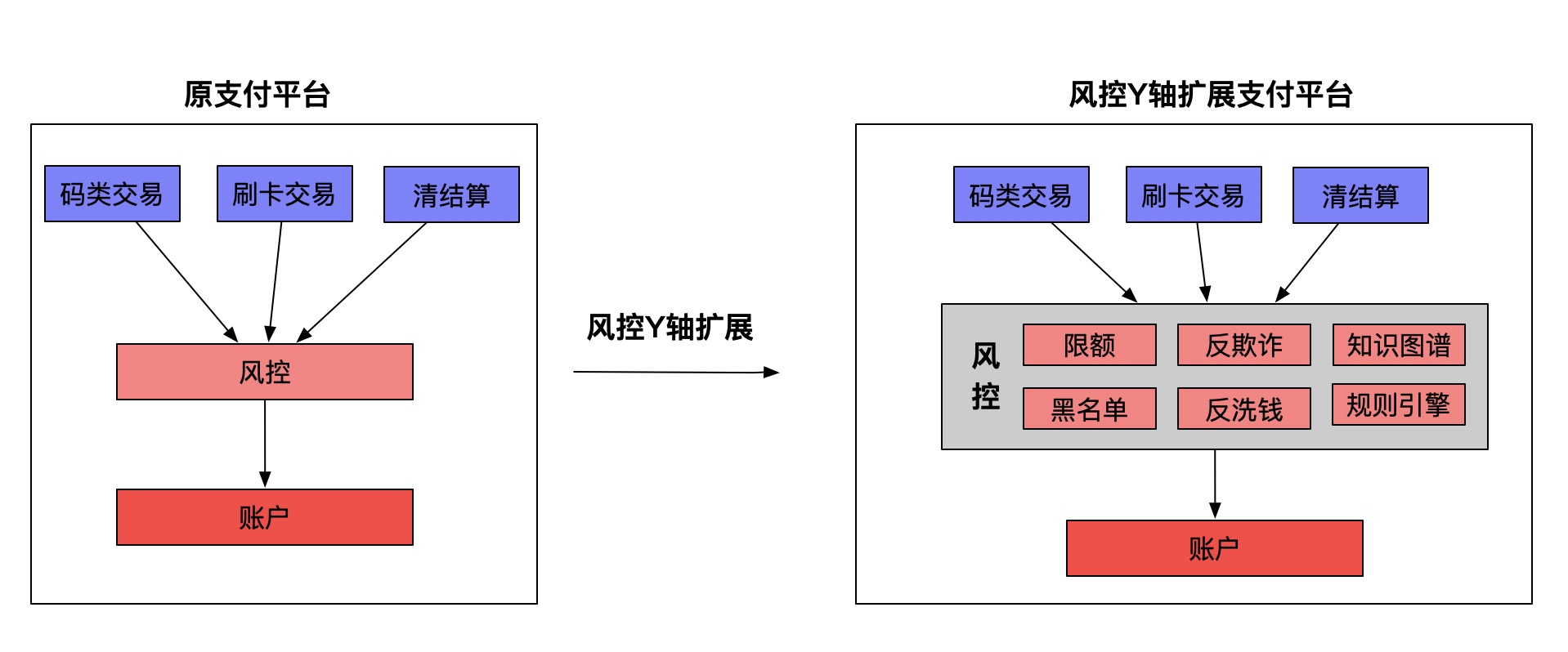
Y轴扩展
Y轴扩展是根据数据的类型或者交易执行的类型(或者两者都有)来划分工作职责。一般称为面向服务或面向资源的扩展。
我们再以火车来举例,12306根据起点和终点的不同,划分了多条火车线路。每条火车线路的周期归属运输,交付着乘客的出行服务。这样做的好处是明显的,每条火车线路的任务更简单,从而能更高效的提供出行服务。
与火车分工类似,为了降低系统复杂度,Y轴扩展会将庞大的整体应用拆分为一组服务。每个服务实现一组相关的功能,如核心交易、风险控制等。而在软件上常见的方案是服务化架构(SOA)、微服务化架构(Micro Service)。
Z轴扩展
Z轴扩展是指基于请求者或用户独特的需求,进行系统划分,并使得划分出来的子系统是相互隔离但又是完整的。继续以火车举例,12306为了更好发展业务,交付出行体验。在中国建立N多个铁路局,各个铁路局个行其责,分别提供出行服务。这就是一种Z轴扩展。
对于软件而言,Z轴扩展一般是为了满足差异性的需求、安全隔离而采取的扩展措施。比如,为了提供VIP用户服务,可以将系统完整地复制一份出来,与普通用户所使用的系统完全隔离;针对不同的地域用户,系统自动切换到对应地域的子系统,为用户提供服务,都是Z轴扩展。另外,在系统的灰度部署上,我们也通常使用Z轴扩展来完成。
软件领域常见的Z轴扩展有以下两种方案:分离化部署和数据分区。
分离化部署
在分布式服务设计领域,一个烟筒状就是满足某个分区所有业务操作的自包含闭环。如上面我们说到的Y轴扩展的微服务架构,客户端对服务端节点的选择一般是随机的,但是,如果在此加上Z轴扩展,那服务节点的选择将不再是随机的了,而是每个烟筒状自成一体。
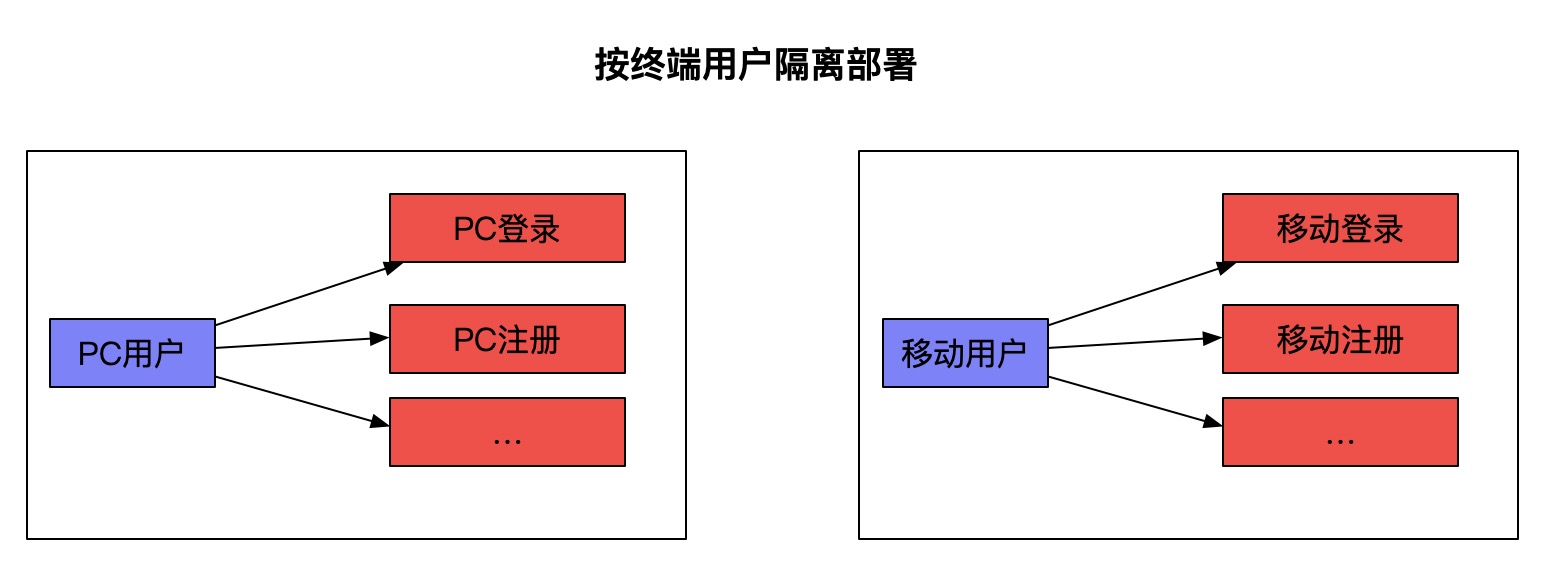
数据分区
为了性能及数据安全考虑,我们将一个完整的数据集按一定的维度划分出不同的子集。 一个分区(Sharding),就是是整体数据集的一个子集。比如用尾号来划分用户,那同样尾号的那部分用户就可以认为是一个分区。数据分区为一般包括以下几种数据划分的方式:
- 数据类型(如,业务类型)
- 数据范围(如,时间段、用户)
- 数据热度(如,用户活跃度)
- 按读写分(如,描述,库存)
当然,数据分区也是有代价的,它将增加数据运维的难度,关联搜索的复杂度增加等。
总结
X轴上扩展是平台或系统的交易量或工作量增长,虽然X轴扩展能够很好处理交易量的增长,但当系统复杂度的大幅度增加,或用户数量增加以及差异化服务需求出现,X轴扩展就难以应付了。但我们可以通过Y轴扩展来处理系统复杂度增长、Z轴扩展来处理差异性化需求。XYZ三个轴可以根据实际情况酌情使用其中一个、两个或三个,三个轴既可以无限向下扩展也可以无限向上扩展。我们在设计系统架构时可将扩展立方体模型作为理论指导,设计完之后回过头来验证是否可以做相应的扩展。
一个扩展性良好的系统,会充分考虑三个维度上的可扩展性,熟练运用三个维度的扩展性,使得系统性能改善上有更多的方向,但在系统性能优化上,代码层面、框架层面、设计层面也是更加的至关重要。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号