
RNN
RNN
转自:https://blog.csdn.net/zhaojc1995/article/details/80572098
RNN(Recurrent Neural Network)是一类用于处理序列数据的神经网络。基础的神经网络只在层与层之间建立了权连接,RNN最大的不同之处就是在层之间的神经元之间也建立的权连接。
基本结构
图中O代表输出,y代表样本给出的确定值,L代表损失函数,x是输入。V、W、U是权值,同一类型的权连接权值相同 。
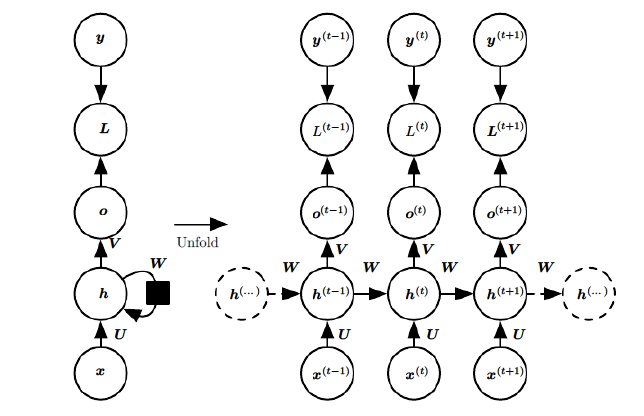
标准RNN的还有以下特点:
- 权值共享,图中的W全是相同的,U和V也一样。
- 每一个输入值都只与它本身的那条路线建立权连接,不会和别的神经元连接。
前向传播算法其实非常简单,对于t时刻:
其中ϕ()为激活函数,一般来说会选择tanh函数,b为偏置。
t 时刻的输出为:
最终模型的输出为:
其中σ\sigmaσ为激活函数,通常RNN用于分类,故这里一般用softmax函数。
反向传播
RNN的损失也是会随着时间累加的,所以不能只求t时刻的偏导:
当 t = 3 时:
再写成一般形式:
梯度消失
我们会发现累乘会导致激活函数导数的累乘,进而会导致“梯度消失“和“梯度爆炸“现象的发生。
sigmod:

tanh:
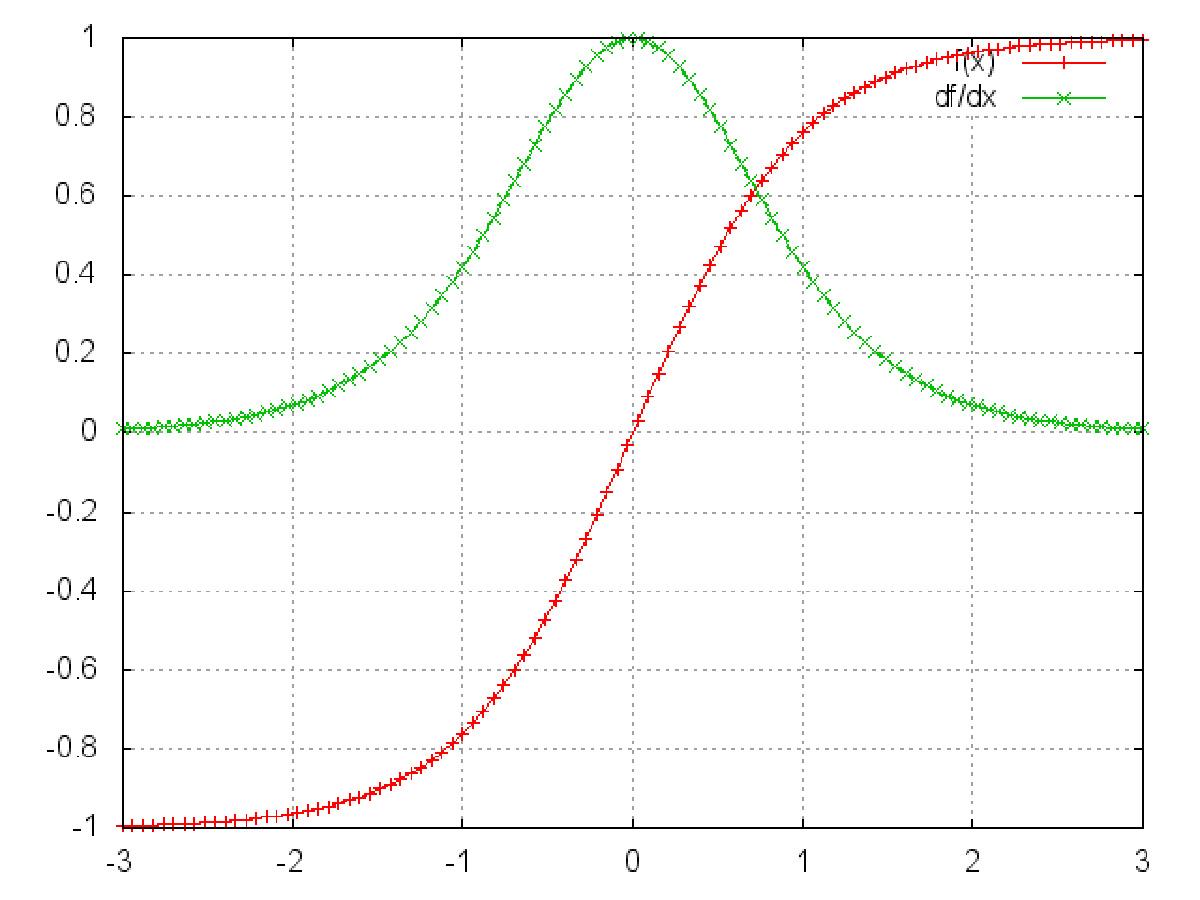
在上面式子累乘的过程中,如果取sigmoid函数作为激活函数的话,那么必然是一堆小数在做乘法,结果就是越乘越小。随着时间序列的不断深入,小数的累乘就会导致梯度越来越小直到接近于0,这就是“梯度消失“现象。其实RNN的时间序列与深层神经网络很像,在较为深层的神经网络中使用sigmoid函数做激活函数也会导致反向传播时梯度消失,梯度消失就意味消失那一层的参数再也不更新,那么那一层隐层就变成了单纯的映射层,毫无意义了,所以在深层神经网络中,有时候多加神经元数量可能会比多家深度好。
你可能会提出异议,RNN明明与深层神经网络不同,RNN的参数都是共享的,而且某时刻的梯度是此时刻和之前时刻的累加,即使传不到最深处那浅层也是有梯度的。这当然是对的,但如果我们根据有限层的梯度来更新更多层的共享的参数一定会出现问题的,因为将有限的信息来作为寻优根据必定不会找到所有信息的最优解。
tanh函数相对于sigmoid函数来说梯度较大,收敛速度更快且引起梯度消失更慢。
sigmoid函数还有一个缺点,Sigmoid函数输出不是零中心对称。sigmoid的输出均大于0,这就使得输出不是0均值,称为偏移现象,这将导致后一层的神经元将上一层输出的非0均值的信号作为输入。关于原点对称的输入和中心对称的输出,网络会收敛地更好。
RNN的特点本来就是能“追根溯源“利用历史数据,现在告诉我可利用的历史数据竟然是有限的,这就令人非常难受,解决“梯度消失“是非常必要的。这里说两种改善“梯度消失”的方法:
- 选取更好的激活函数
- 改变传播结构
RELU
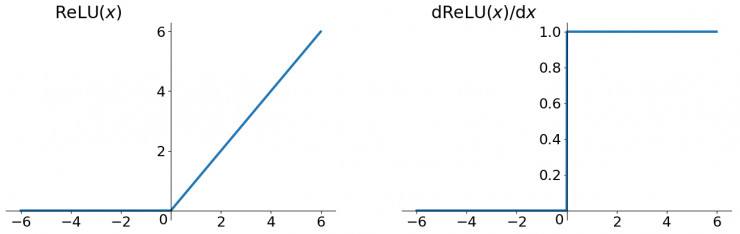
ReLU函数的左侧导数为0,右侧导数恒为1,这就避免了小数的连乘,但反向传播中仍有权值的累乘,所以说ReLU函数不能说完全解决了“梯度消失”现象,只能说改善。有研究表明,在RNN中使用ReLU函数配合将权值初始化到单位矩阵附近,可以达到接近LSTM网络的效果。但恒为1的导数容易导致“梯度爆炸“,但设定合适的阈值可以解决这个问题。还有一点就是如果左侧横为0的导数有可能导致把神经元学死,不过设置合适的步长(学习率)也可以有效避免这个问题的发生。
总结一下,sigmoid函数的缺点:
- 导数值范围为(0,0.25],反向传播时会导致“梯度消失“。tanh函数导数值范围更大,相对好一点。
- sigmoid函数不是0中心对称,tanh函数是,可以使网络收敛的更好。
LSTM 网络
Long Short Term 网络—— 一般就叫做 LSTM ——是一种 RNN 特殊的类型,可以学习长期依赖信息。

LSTM 的关键就是细胞状态,水平线在图上方贯穿运行。细胞状态类似于传送带。直接在整个链上运行,只有一些少量的线性交互。信息在上面流传保持不变会很容易。
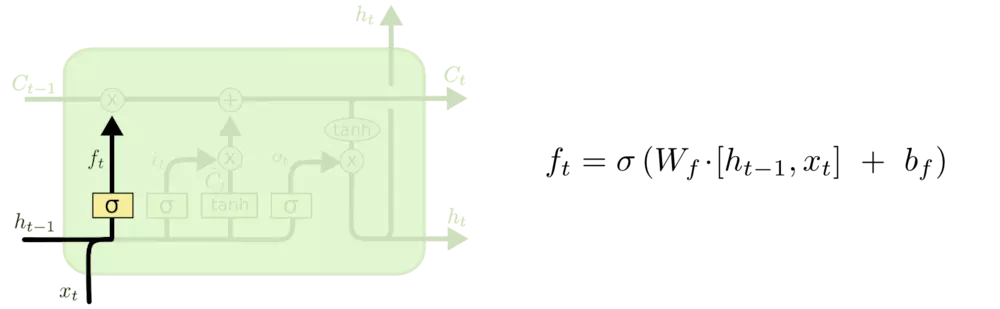
1.选择性遗忘
f t 为 。1 表示“完全保留”,0 表示“完全舍弃”
2.新信息选择
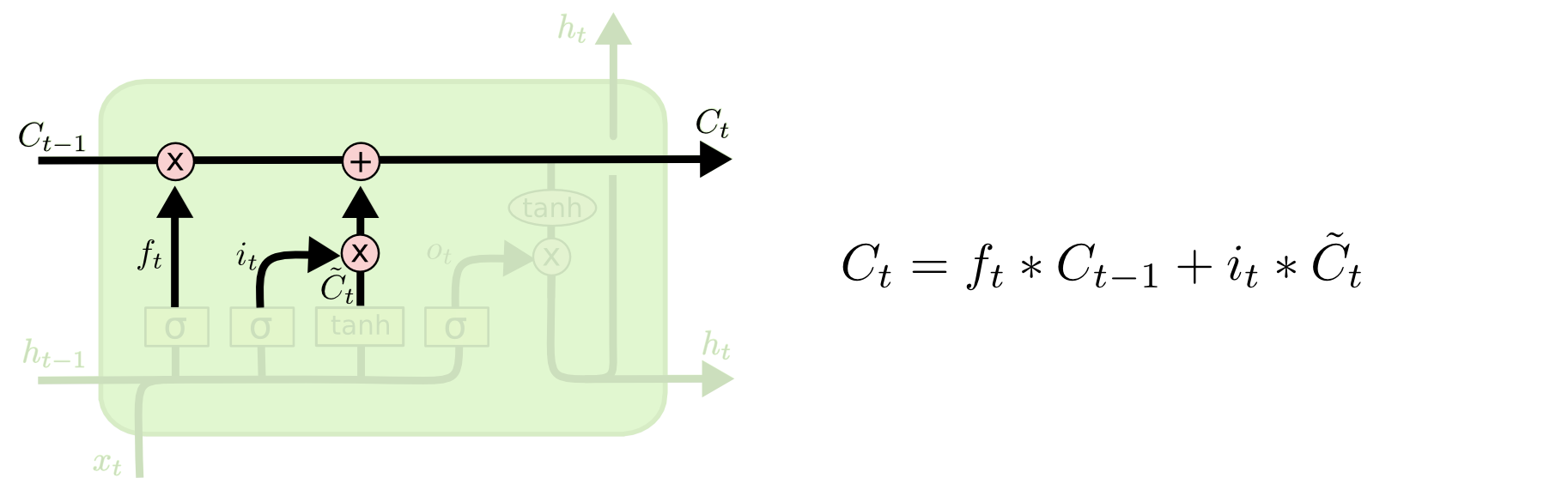
3. 确定输出值
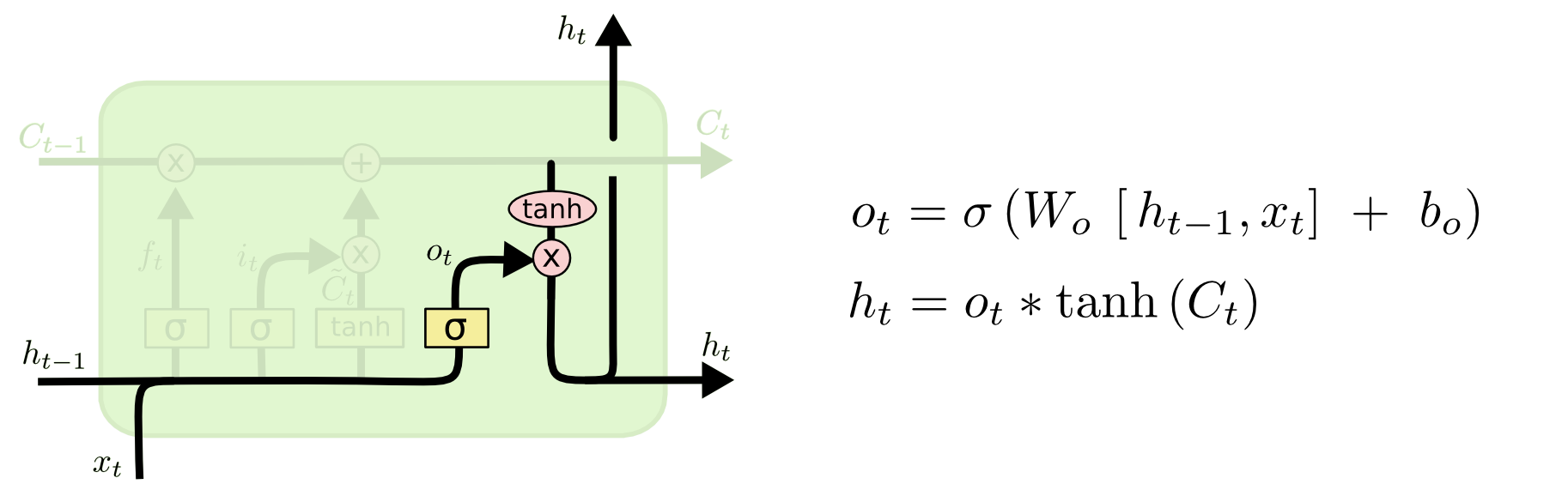
这三个门虽然功能上不同,但在执行任务的操作上是相同的。他们都是使用sigmoid函数作为选择工具,tanh函数作为变换工具,这两个函数结合起来实现三个门的功能。
import copy , numpy as np
np.random.seed(0)
#compute sigmoid nonlinearity
def sigmoid_out_to_derivative(output):
output = 1/(1+np.exp(-x))
return output
#convert output of sigmoid function to its derivative
def sigmoid_output_to_derivative(output):
return output*(1-output)
# training dataset generation
int2binanry = {}
binary_dim = 8
largest_number = pow(2,binary_dim)
binary = np.unpackbits( #unpackbits函数可以把整数转化成2进制数。
np.array([range(largest_number)],dtype=np.uint8).T, axis=1)
for i in range(largest_number):
int2binanry[i] = binary[i]
# input variables
alpha = 0.1
input_dim = 2
hidden_dim = 16
output_dim = 1
# initialize neural network weights
synapse_0 = 2*np.random.random((input_dim,hidden_dim))-1
synapse_l = 2*np.random.random((hidden_dim,output_dim))-1
synapse_h = 2*np.random.random((hidden_dim,hidden_dim))-1
synapse_0_update = np.zeros_like(synapse_0)
synapse_l_update = np.zeros_like(synapse_l)
synapse_h_update = np.zeros_like(synapse_h)
# training logic
for j in range(10000):
# generate a simple addition problem (a+b = c)
a_int = np.random.randinit(largest_number/2) # int version
a = int2binary[a_int] # binary encoding
b_int = np.random.randint(largest_number/2) # int version
b = int2binary[b_int] # binary encoding
#true answer
c_int = a_int + b_int
c = int2binary[c_int]
#whera we will store our best guess (binary encoded)
d = np.zeros_like(c) # Return an array of zeros with the same shape and type as a given array.
overallError = 0
layer_2_deltas = list()
layer_1_values = list()
layer_1_values.append(np.zeros(hidden_dim))
# moving along the positions in binary encoding
for position in range(binary_dim):
#generate the input and output
x = np.array([[a[binary_dim - position -1],b[binary_dim - position -1]]])
y = np.array([[c[binary_dim - position -1]]]).T
#hidden layer (input -+ prev_hidden)
layer_1 = sigmoid(np.dot(X,synapse_0) + np.dot(layer_1_values[-1],synapse_h))
#output layer (new bianry representation)
layer2 = sigmoid(np.dot(layer_1,synapse_l))
#error
layer_2_error = y - layer_2
layer_2_deltas.append((layer_2_error)*sigmoid_output_to_derivative(layer_2))
overallError += np.abs(layer_2_error[0])
#decode estimate so we can print it out
d[binary_dim - position -1] = np.round[layer_1]
future_layer_1_delta = np.zeros(hidden_dim)
for position in range(binary_dim):
X = np.array([[a[position],b[position]]])
layer_1 = layer_1_values[-position-1]
prev_layer_1 = layer_1_valuesp[-position-2]
# error at output layer
layer_2_delta = layer_2_deltas[-position-1]
# error at hidden layer
layer_1_delta = (future_layer_1_delta.dot(synaose_h.T)) + layer_2_delta.dot(synapse_l.T)*sigmoid_out_to_derivative(layer_1)
# update all weights
synapse_l_update += np.atleast_2d(layer_1).T.dot(layer_2_delta)
synapse_h_update += np.atleast_2d(prev_layer_1).T.dot(layer_1_delta)
synapse_0_update += X.T.dot(layer_1_delta)
future_layer_1_delta = layer_1_delta
synapse_0_update *= 0
synapse_l_update *= 0
synapse_h_update *= 0
if(j%1000 ==0):
print "Error: " + str(overallError)
print "Pred:" + str(d)
print "true:" + str(c)
out = 0
for index,x in enumerate(reversed(d)):
out += x*pow(2,index)
print str(a_int ) + "+" + str(b_int) + " = " + str(out)
print " .. .. .. "

