
为什么要编码?编码的类型?乱码的产生?
我们知道计算机处理的数据实际上都是二级制的数据,也就是计算机实际上只识别0和1两种状态。发明计算机的过程中人们需要解决的第一个问题就是文字的处理问题,也就是我们如何将文字符号转化为二级制数据,同时我们也需要能够将转化后的二进制数据重新转化为文字符号供我们阅读。前面的过程我们称之为编码,后面的这个过程我们称之为解码。这和电信领域更著名的一套编解码规则莫尔斯码是一个原理。
ASCII
我们知道,计算机是由美国人发明的,所以最初摆在他们面前的编解码问题其实简单的多,因为英文只有26个字母,即使加上美国人日常使用的所有符号,也不会超过100个。而一个字节8位中前7位的理论上可以表示=128个字符,所以对于英文来说,只需要用一个字节
=256(甚至还富余128个!)来表示,就足够了。于是美国人开心的制定了一套规则:American Standard Code for Information Interchange,美国信息交换标准代码。这个规格有个大名鼎鼎缩写名称:ASCII。
ASCII一共规定了128个字符的编码,比如空格"SPACE"是32(二进制00100000),大写的字母A是65(二进制01000001)。这128个符号(包括32个不能打印出来的控制符号),只占用了一个字节的后面7位,最前面的1位统一规定为0。下图为全部的ASCII编码。
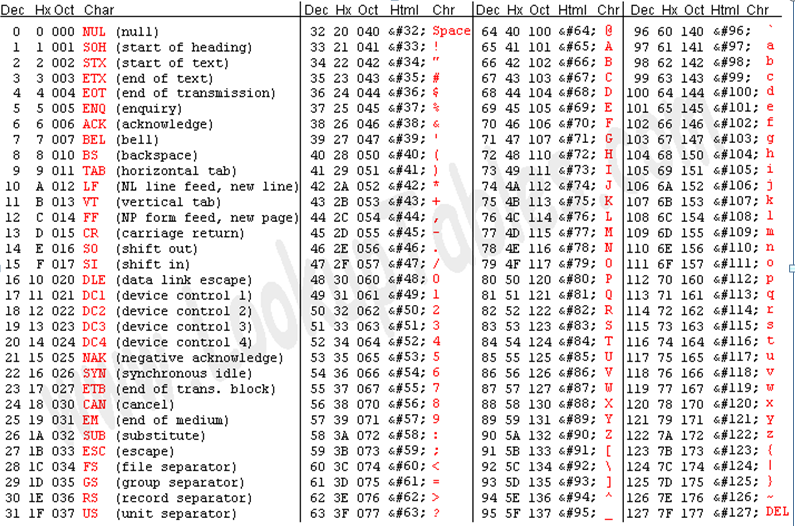
在早期计算机领域,英语作为唯一统治性的语言,ASCII很好的完成了人们所需要的编解码工作。ASCII也就成为计算机世界的标准之一。
字符集&编码方式在继续向下之前,我们需要区分下字符集和编码方式两个概念。
字符集(Charset)是一个系统支持的所有抽象字符的集合。字符是各种文字和符号的总称,包括各国家文字、标点符号、图形符号、数字等。
而字符编码(Character Encoding)是一套法则,使用该法则能够对自然语言的字符的一个集合(如字母表或音节表),与其他东西的一个集合(如号码或电脉冲)进行配对。
具体来说,对于ASCII字符集,是指包括控制字符(回车键、退格、换行键等);可显示字符(英文大小写字符、阿拉伯数字和西文符号)。
而ASCII编码则是将ASCII字符集转换为计算机可以接受的数字系统的数的规则。使用7位(bits)表示一个字符,共128字符。
因此,实际上,同一个字符集其实可以有多种编码方式,例如我们熟悉的Unicode,实际上应该称之为一个字符集,而它的具体编码实现方式则有UTF-8,UTF-16等多种。(当然这个表述方式同样存在问题,这是源于字符编码(character encoding), 字符映射(character map), 字符集(character set)或者代码页,在历史上往往是同义概念,关于Unicode更详细的一些说明请参加Unicode)
在后面的表述中,如无特殊需要,我们对字符集,编码方式,编码实现方式等几个概念也不加以特殊区分使用。
欧洲语言
随着计算机的发展,计算机所要处理的语言已经不只是英语,像法语德语西班牙语这些语言也产生了编解码的需求。这个时候标准ASCII显然已经不够用了,所以各种语言产生了扩充ASCII的需求。
幸运的是,西方整体基于拉丁语的拼写规则,使得他们每种语言也并没有太多的字母,而ASCII富余出来的128个字符空位显然已经足够,因此各国纷纷开始扩充ASCII编码。这样,大家依然可以只使用一个字节来完整的表示自己国家的语言,同时还可以兼容ASCII编码。(这也就是为什么英语在几乎所有的编码规则中都没有乱码问题的原因,当然UTF-16有些特殊,有兴趣可以了解下UTF-16)
但是,这里又出现了新的问题。不同的国家有不同的字母,因此,哪怕它们都使用256个符号的编码方式,代表的字母却不一样。比如,130在法语编码中代表了é,在希伯来语编码中却代表了字母 ג。
但是这就产生的一些问题,意大利人机器上输入了一段意大利语存储起来发给德国人,德国人在德国编码的机器上看到了将是一段意义完全不同的德语。(包含多个欧洲国家不同语系的特殊字符的数据,无法用ISO/IEC 8859的某一个单独的字符集来表示出来,即无法在同一个文章中支持显示不同语系的不同的字符。当然这是西方人的问题,我们不再展开讨论,如有兴趣请参看:ISO/IEC 8859)
东方语言的问题
就在欧洲人民开心的扩展着ASCII的时候,计算机的影响扩展到了遥远的东方。想要在计算机上显示自己国家语言的中日韩人民傻眼了。拉丁语系在怎么折腾怎么变形,终究是表音文字,怎么都超不出256个字符,因此一个字节一定是可以表示全部字符的。但是中日韩文都是1万字起的规模,无论如果不可能用一个字节表示,真是灾难啊。
中文编码
怎么办?一个字节不够,我们就用两个字节。0-127属于标准ASCII这事已经是既定事实,但是128-255既然欧洲各国都在制定自己的标准,那我们也来插一腿。于是我们规定:一个小于127的字符的意义与原来相同,但两个大于127的字符连在一起时,就表示一个汉字,前面的一个字节(称之为高字节)从0xA1(10100001)用到 0xF7(11110111),后面一个字节(低字节)从0xA1到0xFE(11111110),这样我们组合出了6763个简体汉字。在这个编码中,我们还同时还把ASCII里有的字符重新用两字节编码了一次,我们称之为全角,而原来在127号以下的那些就叫半角。例如ABCD这些是半角,ABCD这些则是全角。
这就是我们汉字编码的第一个标准--GB2312,同样是对ASCII的扩展。
顺便说一句,在20年前的MS-DOS时代,中国人民要想正常看到中文,都要安装一个叫做UCDOS的汉字系统。否则你看到的中文将是一堆?配着奇怪的字符。那个时候的乱码问题可比现在严重的多得多。
随着计算机的使用日益生活化,6763个汉字显然不能满足我们的需求了。Windows 95的制造者微软为了可以在操作系统中显示更多的汉字,设计了新的编码规则GBK(GBK居然是GB Kuozhan的缩写,真是让人哭笑不得)。相比GB2312,GBK继续扩展了范围,总体上说第一字节的范围是0x81–0xFE,第二字节的一部分领域在0x40–0x7E,其他领域在0x80–0xFE。GBK向下完全兼容GB2312编码。 支持GB2312编码不支持的部分中文姓,中文繁体,日文假名,还包括希腊字母以及俄语字母等字母,不过这种编码不支持韩国字。GBK大约收录了两万个左右的字。下图是GBK编码的图示范围。
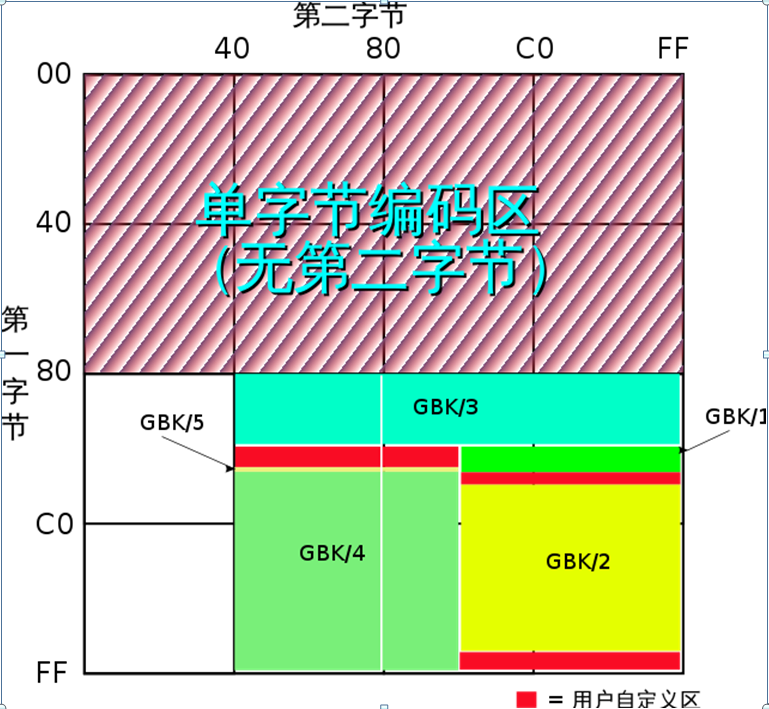
GBK一直不是国家标准,只不过windows使用的缘故,影响巨大。几年后,中国国家标准化管理委员推出了GB 18030国家标准。
GB 18030主要有以下特点:
- 与 UTF-8 相同,采用多字节编码,每个字可以由1个、2个或4个字节组成。
- 编码空间庞大,最多可定义161万个字符。
- 支持中国国内少数民族的文字,不需要动用造字区。
- 汉字收录范围包含繁体汉字以及日韩汉字。
可以说GB 18030本身是很出色的,几乎完美解决了东亚文字的编码问题,如果这份标准诞生于50年前,它将毫无疑问成为事实上的标准,而让我们饱受困扰的乱码问题将很少出现。只可惜,这份标准诞生于2000年。而此时,日本的ShiftJIS和台湾的Big5已经成为它们各自区域的编码标准。因为繁体中文和我们关系密切,所以我们下面将单独讲下繁体中文的编码。
繁体中文Big5(大五码的英译)是目前繁体中文主流的编码方式。和GB体系的编码规则类似,Big5码以两个字节来安放一个字。第一字节使用了0x81-0xFE,第二字节使用了0x40-0x7E,及0xA1-0xFE。总共收录了13,060字。
乱码问题讲完前面这些铺垫内容后,我们来讲下乱码问题是如何产生的。以我们最常见的简体繁体来说。
我们发现GBK编码的范围是:第一字节的范围是0x81–0xFE,第二字节的一部分领域在0x40–0x7E,其他领域在0x80–0xFE。
而Big5编码的范围则是:第一字节使用了0x81-0xFE,第二字节使用了0x40-0x7E,及0xA1-0xFE。
一般来说,我们指的乱码其实有两种:
一种是像0xC180(羳)这样在GBK中可以被解码的字,由于0xC180不在Big5的解码范围内,所以一般会有一些固定的符号代替,如.或?。
另一种,是由于简繁体中文的同一个字在各自编码体系中编码不同,而在解码时产生的混乱。比如林这个字,在Big5中的编码是AA4C,但是在GBK中AA4C对应的汉字是狶。也就是说如果台湾同胞使用一个Big5编码的邮件客户端给我发一封邮件写着“Hi 林”,我用GBK编码的邮件客户端打开看起来会是“Hi 狶”,真是让人绝望。
Unicode的诞生鉴于各国各自发展自己的编码方式,本来统一的计算机世界马上要变得和世界上语言一样一片混乱,Unicode组织在90年代发布了The Unicode Standard。Unicode的开发结合了国际标准化组织所制定的ISO/IEC 10646,即通用字符集。Unicode编码系统为表达任意语言的任意字符而设计。它使用4字节的数字来表达每个字母、符号,或者表意文字(ideograph,比如中日韩文)。每个数字代表唯一的至少在某种语言中使用的符号。每个字符对应一个数字,每个数字对应一个字符。即不存在二义性。Unicode 就已经包含了超过十万个字符,在表示一个Unicode的字符时,通常会用“U+”然后紧接着一组十六进制的数字来表示这一个字符。
需要特别指出的是,被几种语言共用的字符通常使用相同的数字来编码,除非存在一个在理的语源学(etymological)理由使不这样做。(这就是只对字而不是对字形编码,涉及汉字的一个小插曲:中日韓越統一表意文字,有兴趣的话请参见中日韓越統一表意文字)
UCS 和 UNICODE的关系鉴于UCS也是一个经常出现在编码领域的名词,因此需要顺便说一下它和UNICODE的关系。
通用字符集(Universal Character Set,UCS)是由ISO制定的ISO 10646(或称ISO/IEC 10646)标准所定义的标准字符集。基于一些怪异的历史原因,目前有两个组织在维护UNICODE字符集。ISO维护的叫做ISO 10646,统一码联盟维护的叫做UNICODE。这两者目前完全一致,但是是两个标准(多么奇怪的逻辑)。
而我们有时候能看到的UCS-4、UCS-2分别指的是用四个字节和两个字节来表示一个字符,基本和UTF-32和UTF-16两个概念是对应的。
UTF-8
UNICODE标准在91年就发布,互联网的兴起才是真正推动UNICODE标准被国际化大规模的使用。因为互联网淡化了国界的概念,如果各个国家还是采用自己的标准,那么想想我前面说过的大陆GBK和台湾BIG5交流的悲剧。因此,人们迫切的需要一种通用的统一的编码方式,UNICODE终于开始真正发挥作用。UTF-8也几乎成了互联网通信事实上的标准。
UTF-8(8-bit Unicode Transformation Format)是一种针对Unicode的可变长度字符编码(定长码),也是一种前缀码。它可以用来表示Unicode标准中的任何字符,且其编码中的第一个字节仍与ASCII兼容,这使得原来处理ASCII字符的软件无须或只须做少部份修改,即可继续使用。因此,它逐渐成为电子邮件、网页及其他存储或传送文字的应用中,优先采用的编码。互联网工程工作小组(IETF)要求所有互联网协议都必须支持UTF-8编码。
规则UTF-8的编码规则很简单(规则来源字符编码笔记:ASCII,Unicode和UTF-8):
1)对于单字节的符号,字节的第一位设为0,后面7位为这个符号的Unicode码。因此对于英语字母,UTF-8编码和ASCII码是相同的(顺便提一句,UTF-16就不是)。
2)对于n字节的符号(n>1),第一个字节的前n位都设为1,第n+1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的Unicode码。
下表总结了编码规则,字母x表示可用编码的位。
以汉字"严"为例,演示如何实现UTF-8编码。

已知"严"的Unicode是4E25(100 1110 0010 0101),根据上表,可以发现4E25处在第三段的范围内(0000 0800-0000 FFFF),因此"严"的UTF-8编码需要三个字节,即格式是"1110xxxx 10xxxxxx 10xxxxxx"。然后,从"严"的最后一个二进制位开始,依次从后向前填入格式中的x,多出的位补0。这样就得到了,"严"的UTF-8编码是"11100100 10111000 10100101",转换成十六进制就是E4B8A5(加粗的部分,为从Unicode码中获取的部分)。
Windows的处理方式顺便提一句,从 Windows NT 开始,MS把它们的操作系统改了一遍,把所有的核心代码都改成了用 UNICODE 方式工作的版本,这就是为什么我们的电脑可以正常的显示所有的语言(前提是这种语言采用了UNICODE编码)。
看下你windows的区域设置:
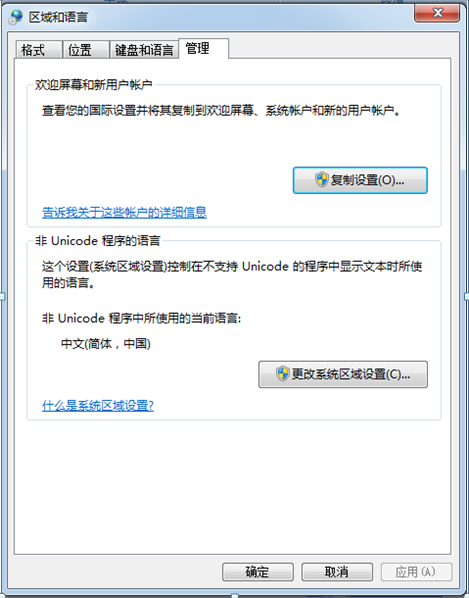
也就是说,windows默认的处理方式是这样的,默认采用Unicode,但对于不支持Unicode的程序或者不是Unicode的字符,就采用设置的中文编码(GBK)来处理。
这就涉及到UTF-8的另一个优良特性:UTF-8字符串可以由一个简单的算法可靠地识别出来。就是,一个字符串在任何其它编码中表现为合法的UTF-8的可能性很低。也就是说,在面对Big5,GBK等类似编码时,我们完全不能将他们区分开来,但是我们几乎可以准确的区分UTF-8字符串和非UTF-8字符串。
顺便插一句,为什么上面说几乎而不是绝对,可以做这个小实验:当你在 windows 的记事本里新建一个文件,输入“联通”两个字之后,保存,关闭,然后再次打开,你会发现这两个字已经消失了,代之的是几个乱码!这个的原因是因为联通两个字的GB2312编码被识别成了UTF-8编码。
当你在Windows里看到乱码,不在于这段数据的语言,而是因为这段数据采用了非Unicode且非GBK的编码格式。
作者:李林
链接:https://www.zhihu.com/question/22680300/answer/23328390
来源:知乎

 浙公网安备 33010602011771号
浙公网安备 33010602011771号