
软工实践第二次作业之个人项目
1. Github地址
PSP表格:
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 60 | 10 |
| Estimate | 估计这个任务需要多长时间 | 20 | 20 |
| Development | 开发 | 600 | 720 |
| Analysis | 需求分析(包括学习新技术) | 300 | 360 |
| Design Spec | 设计生成文档 | 30 | 20 |
| Design Review | 设计复审 | 30 | 20 |
| Coding Standard | 代码规范(为目前开发指定合适的规范) | 20 | 20 |
| Design | 具体设计 | 50 | 40 |
| Coding | 具体编码 | 500 | 600 |
| Code review | 代码复审 | 100 | 180 |
| Test | 测试(自我测试,修改代码,提交修改) | 100 | 180 |
| Reporting | 报告 | 30 | 60 |
| Test Report | 测试报告 | 20 | 50 |
| Size Measurement | 计算工作量 | 120 | 30 |
| Postmortem & Process Improvement Plan | 事后总结,并提出过程改进计划 | 200 | 20 |
| 合计 | 2180 | 1550 |
解题思路描述:
在刚开始拿到题目的时候,其实对于这种未知的项目还是很恐慌的,看到后面的各种什么性能分析报告,代码覆盖率等等陌生的名词很害怕。但是仔细思考之后,发现实现基本功能也不过如此,分几个模块实现还不算很难;要解决以下几个问题:
- 通过命令行传参数,这个因为之前面向对象有写过一次,因此再回去熟悉一下操作就好了。
- 文件内容读出写入操作,核心便是读出文件字符并对其进行一定的处理,可以通过字符流方式不断读出单个字符。
- 对不同几个功能模块封装接口,这个之前也学过复习一下不难。
- 新学习性能分析、单元测试和代码覆盖率的实现。
学习及实现方式:
通过百度谷歌搜索引擎查找不熟悉资料复习,另外对于后面的单元测试和代码覆盖率是参考赵畅同学的博客,以及其博客中推荐的博客及插件。(在此谢过 !)
设计实现过程:
在设计过程中,一开始还比较乱,仅仅大概思考了分成三个不同的.h及.cpp文件封装函数,后面再实现过程不断完善改进;
独到之处:
“弱肉强食”算法,单词越按照使用习惯经常出现,时间复杂度越小;
流程图:
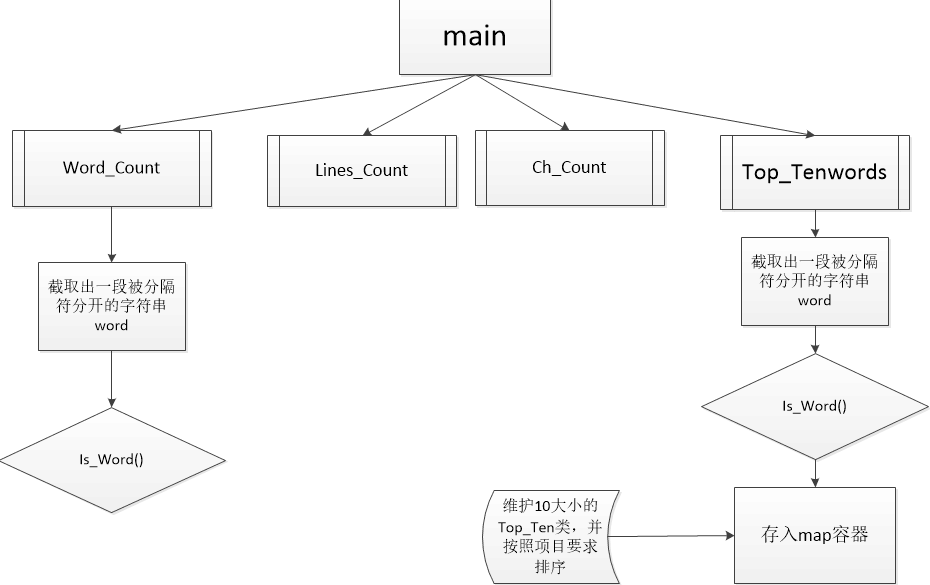
单元测试设计:手动设计测试文件进行测试,考虑多种特殊情况以及普遍情况进行测试;另外针对张栋老师评论文件再大一些情况,进一步做了更全面,量级更大的测试;
程序性能分析及改进:
最开始选择的是将所有单词存入map容器中然后再整体选取频数前十的十个单词,花费时间:sort(n)量级,n为不同单词总数量;
时间复杂度:nlog(n);
改进思路:只维护一个10大小的数组,在存入map容易过程中实时判断频数及字典序是否进入前十决定是否和Top_Ten类型words[9]更换;个人认为若是计算频数最高的十位,根据使用单词习惯及出现规律,已经出现次数在前十的单词更有可能是文件中的前十的单词(所以,若是经常使用的单词经常出现,可以大幅降低更换及排序次数降低复杂度);
最差时间复杂度:10(n-10)*log(10);
拓展思考(各大输入法):
对于这次作业的词频功能,思考实现过程想到了现在我们各大流行的输入法软件,显然平时不管我们是使用九键输入,或者26键,那么在输入首字母或前几个拼音时自动为我们显示的那些常用字应该就是通过这种词频算法,让我们用户体验更好,效率更高吧?我的思路便是按照经常使用的单词(汉字):之前用的越多,以后越可能用,这样会比较好的将复杂度降下来;
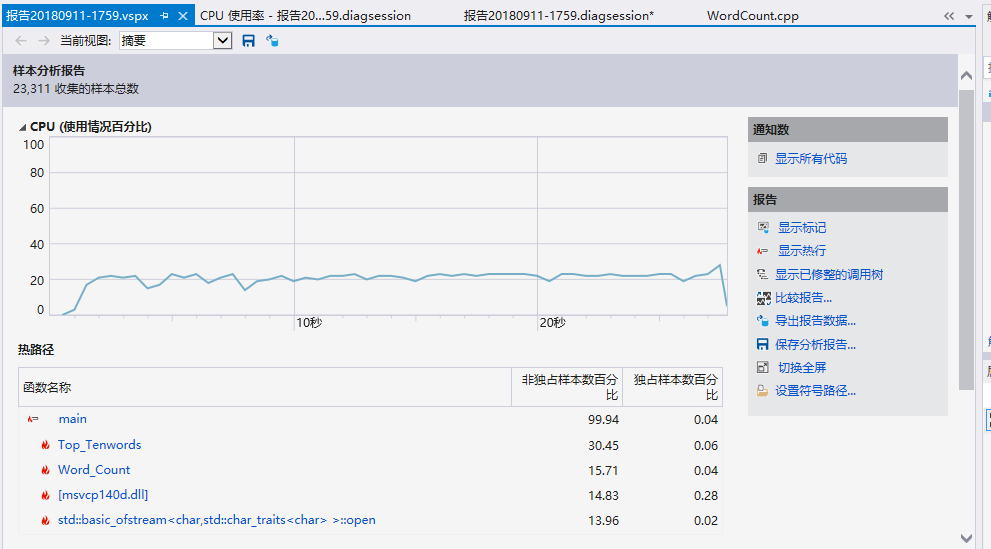
性能分析报告:
下面是测试5000循环main函数总共花费时间34.855秒,根据以下性能分析图可知大部分时间花在文件的读取上面,封装三个接口之后文件读取从一次变成了三次也在时间上增加了不少。可以看出消耗最大的函数是Top_Tenwords函数占比25.73%;
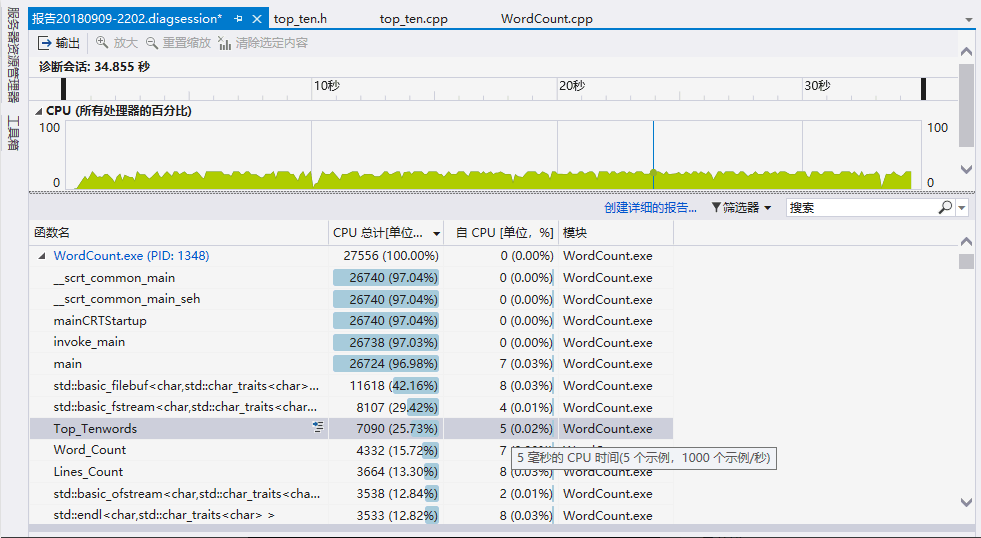
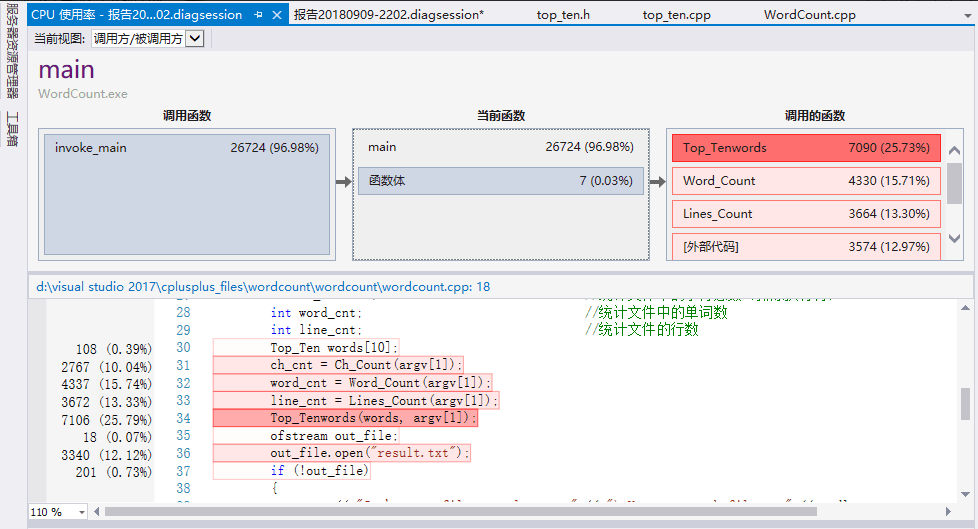
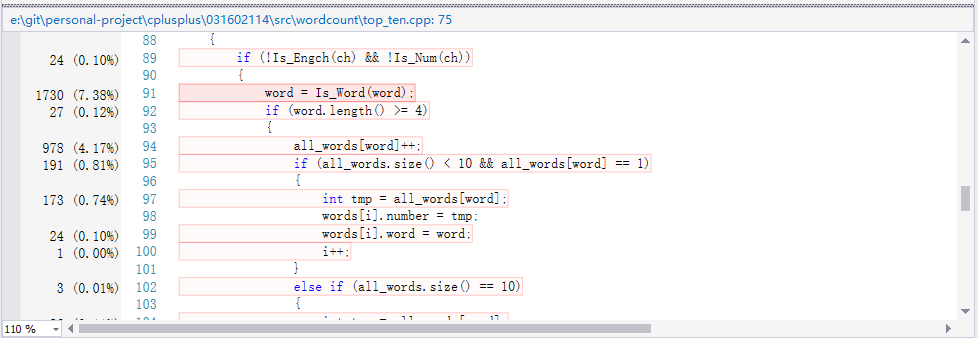
从中可以看出是Is_Word()函数消耗较多,但是Is_Word函数中分布比较平均,因此通过分析工具分析之后只是更改了部分之前使用的C++中输入输出cout为C形式printf优化,其他部分没有进一步优化;时间减少到27秒。

Top_Tenwords函数展示:
void Top_Tenwords(Top_Ten words[],char *filename)
{
fstream f_tmp;
string word = "";
char ch;
map<string, int > all_words;
int i = 0;
f_tmp.open(filename);
if (!f_tmp)
{
printf("Can't open file :s% \n Usage:countch filename", filename);
exit(0);
}
while (f_tmp.get(ch))
{
if (!Is_Engch(ch) && !Is_Num(ch))
{
word = Is_Word(word);
if (word.length() >= 4)
{
all_words[word]++;
if (all_words.size() < 10 && all_words[word] == 1) //map中不同单词 数还没有十个
{
int tmp = all_words[word];
words[i].number = tmp;
words[i].word = word;
i++;
}
else if (all_words.size() == 10) //不同单词数为10开始对数组sort一次
{
int tmp = all_words[word];
words[i].number = tmp;
words[i].word = word;
sort(words, words + 10, Cmp);
}
else if(all_words.size() > 10) //不断判断words[9]和当前扫描到的单词是否需要更新替换
{
if (all_words[word] > words[9].number)
{
words[9].word = word;
words[9].number = all_words[word];
sort(words, words + 10, Cmp);
}
else if (all_words[word] == words[9].number)
{
if (word < words[9].word)
{
words[9].word = word;
words[9].number = all_words[word];
sort(words, words + 10, Cmp);
}
}
}
}
word = "";
continue;
}
else
{
if ((Is_Num(ch) && word.length() > 0) || Is_Engch(ch))
{
word += ch;
continue;
}
else if (Is_Num(ch) && word.length() == 0)
{
continue;
}
}
}
f_tmp.close();
}
代码说明:
关键代码:
int Word_Count(char *filename) //
{
string word="";
char ch;
int word_cnt = 0;
fstream f_tmp;
f_tmp.open(filename);
if (!f_tmp)
{
printf("Can't open file :s% \n Usage:countch filename",filename);
exit(0);
}
while (f_tmp.get(ch))
{
if (!Is_Engch(ch) && !Is_Num(ch))
{
word = Is_Word(word);
if (word.length() >= 4)
{
word_cnt++;
word = "";
continue;
}
continue;
}
else
{
if ((Is_Num(ch) && word.length() > 0)|| Is_Engch(ch))
{
word += ch;
continue;
}
else if (Is_Num(ch) && word.length() == 0)
{
continue;
}
}
}
f_tmp.close();
printf("words:%d\n", word_cnt);
return word_cnt;
}
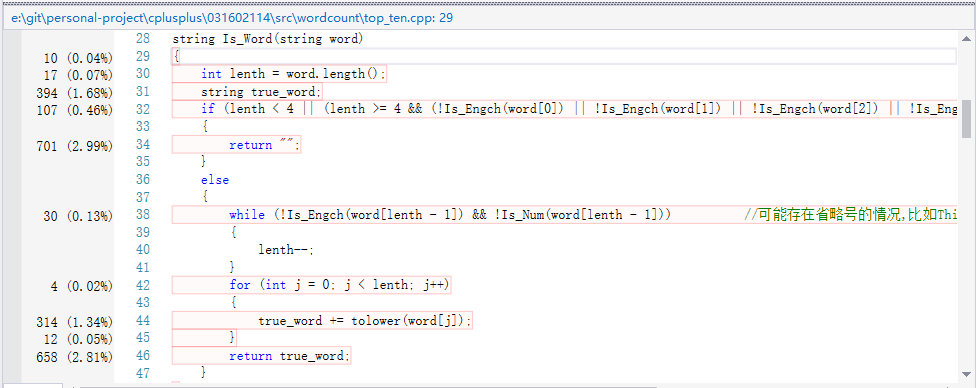
string Is_Word(string word)//判断字符串是否是合法单词,若是返回小写单词;
{
int lenth = word.length();
string true_word;
if (lenth < 4 || (lenth >= 4 && (!Is_Engch(word[0]) || !Is_Engch(word[1]) || !Is_Engch(word[2]) || !Is_Engch(word[3]))))
{
return "";
}
else
{
while (!Is_Engch(word[lenth - 1]) && !Is_Num(word[lenth - 1])) //可能存在省略号的情况,比如This is aaaa test file...
{
lenth--;
}
for (int j = 0; j < lenth; j++)
{
true_word += tolower(word[j]);
}
return true_word;
}
}
计算单词数函数完成了基本功能就基本实现了;注释确实还有些不够熟练,所以有些没有很合理。(另外在几个.h头文件中的注释有参考赵畅同学的代码注释风格,再次重谢!)
单元测试及代码覆盖率:
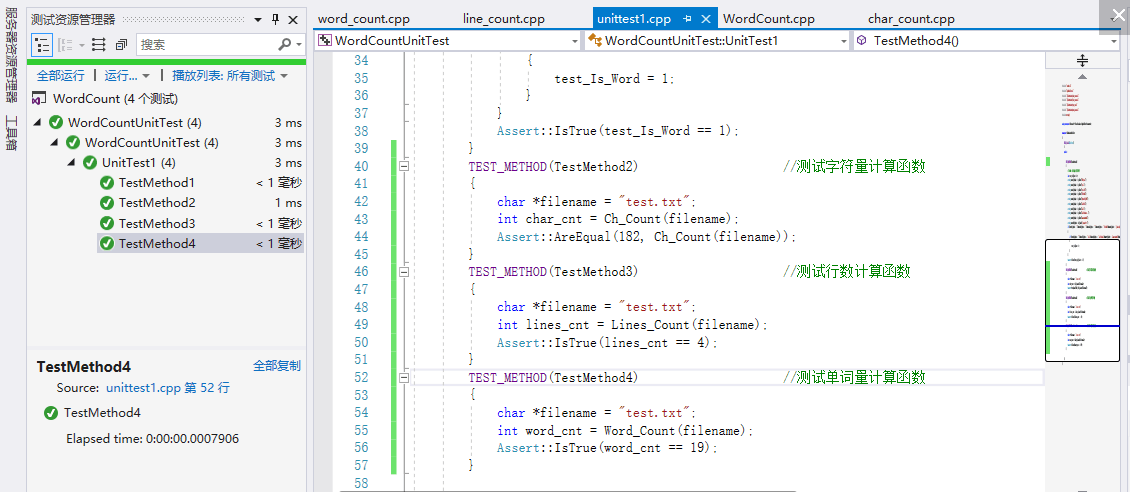
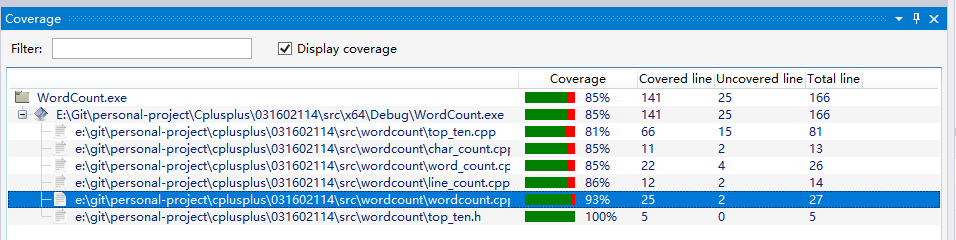

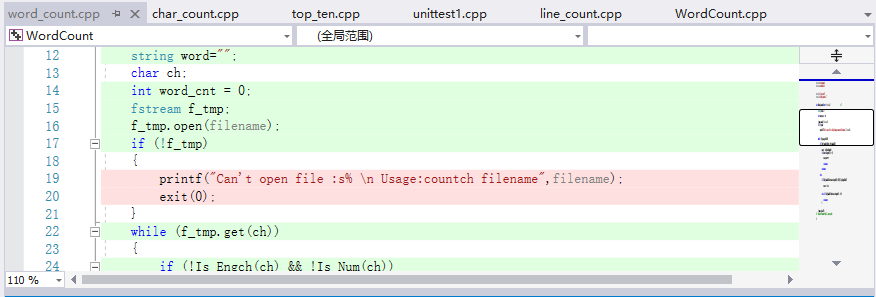
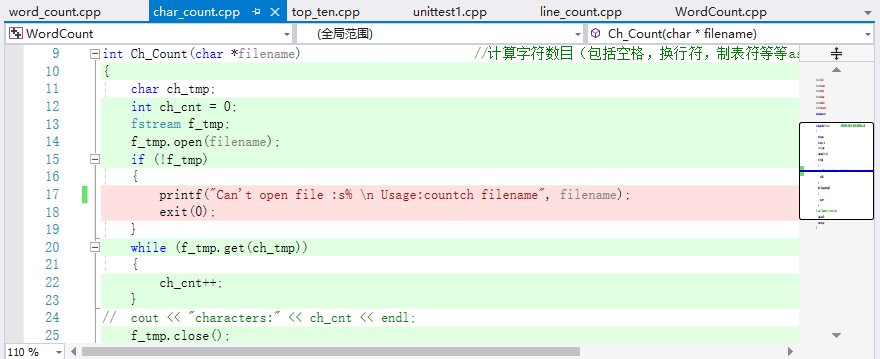
单元测试了四个函数Is_Word()、Lines_Count()、Word_Count()、Ch_Count();几个函数模块代码覆盖率只有85%,可以看到是异常处理的语句占用。(这该如何优化?)
单源测试及代码覆盖率思考:
单元测试:通过此次个人项目作业,之前看构建之法的对于单元测试的疑问我想在实践中已经大概明白了是什么用途和功能,可以针对某一个函数功能模块进行测试判断其是否正确,确保代码可靠性;
代码覆盖率:做了代码覆盖率的操作,对于其中的行代码覆盖率表层意思理解了,但是不太明白代码覆盖率到底具有什么意义?覆盖率达到100%又意味着什么?也有查阅资料,但是还是理解的不够透彻,可能需要后续听柯老板解释一下吧...
异常处理说明
在每个功能模块函数中都需要读取文件,在文件不存在或者因错误无法打开时会报错:
Can't open file :yourfilename \n Usage:countch filename
异常处理还不是很清楚需要哪些更多的异常处理,还有待学习;
个人项目感想:
对之前速读一遍地构建之法一些不太懂得问题有了更清楚的了解,其次就是逐渐认识软工时间的确可以学到很多。重要的是:你看看现在几点!
关于代码规范将在另一篇博客记录,和结对作业代码规范一致官方正式发表;
参考博客:
赵畅同学博客:http://www.cnblogs.com/ZCplayground/p/9607027.html
[第二届构建之法论坛] 预培训文档(C++版):https://www.cnblogs.com/SivilTaram/p/software_pretraining_cpp.html#part6.效能工具介绍

