
用request获取猫眼电影排行榜前一百页电影的信息
这次任务是获取猫眼电影排行前一百页电影的信息,其中涉及滑块验证和动态加密。
滑块验证
猫眼的滑块验证其实很瞎,只要手工滑动通过验证,然后带上header访问就可以通过了,但过段时间还会需要重新验证,想要一劳永逸可能还要用autogui写一段。
可以通过request之后检查请求的url与想要访问的url是否一致来判断是否需要验证:
url = 'https://maoyan.com/films?showType=3&sortId=3&offset=' h = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36'} #手动滑动验证一次后就可以绕过验证了 req = requests.get(url, headers=h) print(req.url)
如果打印出来的url与需要访问的一致,则说明访问成功,否则手动滑块一下即可。
字体加密
本实验中需要获取一部电影的票房、评分、评分人数等,发现这些字段是经过动态加密的,加密方法是字体加密,即每次刷新都返回一种新的字体,这些新的字体实际上是对基本模板的细微改动,改动后导致字符的编码发生改变,从而实现动态加密。
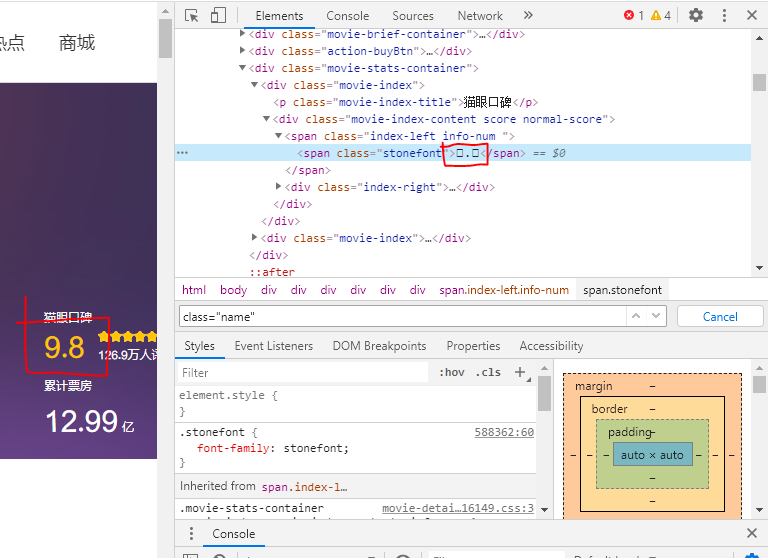
这里采用的处理方法是借鉴https://zhuanlan.zhihu.com/p/84358858
因为还要完成其他任务现在懒得详细写了,简单复述下对引文所使用方法的理解:首先从网页中获取一份字体,解析字体文件后可以看到字体中各个数字字符的坐标,这些坐标可以唯一地确定该数字,这就相当于一份钥匙,有了它就可以对网页返回的其他字体进行解密;解密的方法就是将其他字体中字符的坐标与模板字体中字符的坐标进行比对,待解密字符与模板中各字符的相似度,相似度最为接近的就是我们所需的答案。
后续有空再好好写吧,这里就先贴一下代码:
from fontTools.ttLib import TTFont
from math import sqrt
#抓取加密部分 #字体库获取 def get_font_file(req, file_name): # 获取字体地址 font_url = re.findall(r'url\(\'(.*?)\'\)', req.text, re.S)[2] font_url = 'https:' + font_url #下载字体文件 req_font = requests.get(font_url, headers=h) with open(file_name, 'wb') as f: f.write(req_font.content) #创建模板 template_data = { 'uniE387':3, 'uniEDA2':9, 'uniE667':5, 'uniF350':0, 'uniF8BF':6, 'uniF4DA':8, 'uniE40E':2, 'uniF079':7, 'uniE295':4, 'uniF82F':1 } template_font = TTFont('stonefont.woff') #通过与模板比较判断字符是哪个数字 #计算两个字符间的平均距离 def cal_distance(list): d = 0 for p in list: x1, x2 = p d = d + sqrt(pow(x1[0]-x2[0],2)) + pow(x1[1]-x2[1],2) d = d/len(list) return d def deciphering(req, check_file): #提取网页中被加密的字符 encryption_num = re.findall(r'&#x(.*?);', req.text) encryption_num = set(encryption_num) #读取模板字体库信息 # template_font = TTFont(template_file) template_index = template_font.getGlyphOrder()[2:] #读取新的字体库信息 target_font = TTFont(check_file) #字体解密 correct_num = {} num = {} #遍历每个待计算的字符 for item in encryption_num: target = target_font['glyf']['uni'+item.upper()].coordinates dist_min = 1000000 #遍历每个模板字符 for index in template_index: template = template_font['glyf'][index].coordinates #不同字体库中的相同字符坐标数量不一样,人为确定一个可接受的差异范围10 if abs(len(target)-len(template))<10: dist = cal_distance(list(zip(target, template))) if dist < dist_min: dist_min = dist num[item] = index for item in encryption_num: correct_num['&#x'+item+';'] = template_data[num[item]] return correct_num get_font_file(req, 'check.woff') correct = deciphering(req, 'check.woff') #解码后替换原网页中的字符代码 html = req.text for key in correct: html = html.replace(key, str(correct[key]))
完整代码
import requests import re import pandas from fontTools.ttLib import TTFont from math import sqrt url = 'https://maoyan.com/films?showType=3&sortId=3&offset=' h = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36'} #手动滑动验证一次后就可以绕过验证了 req = requests.get(url, headers=h) print(req.url) #获取电影页面的url def get_movie_url(): with open('film_code.txt', 'w') as f: for i in range(100): url_ = url + str(i*30) req_ = requests.get(url_, headers=h) film_code = re.findall(r'<a href="/films/(.*?)" target', req_.text) film_code = set(film_code) for code in film_code: f.write(code + '\n') print('成功获取前一百页电影的url') #获取电影页面内的信息 def parse(url): req = requests.get(url, headers=h) print(req.url) name = re.findall('<h1 class="name">(.*?)</h1>', req.text)[0] name_eng = re.findall('<div class="ename ellipsis">(.*?)</div>', req.text)[0] genres = re.findall('<a class="text-link".*target="_blank"> (.*) </a>', req.text) release_time = re.findall('<li class="ellipsis">(.*?)</li>', req.text)[0] country_and_time = re.findall('</a>.*</li>.*<li class="ellipsis">(.*?)</li>.*<li class="ellipsis">.*</li>', req.text, re.S)[0]#正则表达式不能匹配换行符,因此必须加上re.S使得正则表达式可以匹配所有换行符或空字符 #https://blog.csdn.net/qq_38486203/article/details/85245011 country_and_time = country_and_time.replace(' ','').replace('\n','').split('/') if len(country_and_time)==2: country = country_and_time[0] produce_time = country_and_time[1] else: country = country_and_time[0] produce_time = '' script = re.findall('<span class="dra">(.*?)</span>', req.text) cast = re.findall('<a href="/films/celebrity/.*?" target="_blank" class="name">(.*?)</a>', req.text, re.S) cast_ = [] for c in cast: cast_.append(c.strip()) #字体加密解码 get_font_file(req, 'check.woff') correct = deciphering(req, 'check.woff') html = req.text for key in correct: html = html.replace(key, str(correct[key])) #爬取解码后的字段 rating = re.findall(r'<div class="movie-index-content score normal-score".*?<span class="index-left info-num ">.*?<span class="stonefont">(.*?)</span>.*?</span>', html, re.S) rate_num = re.findall(r'<span class=\'score-num\'><span class="stonefont">(.*?)</span>人评分</span>', html) box_office = re.findall(r'<div class="movie-index-content box">.*<span class="stonefont">(.*?)</span><span class="unit">(.*?)</span>.*</div>', html, re.S) d = {'name':name,'name_eng':name_eng,'genres':genres,'release_time':release_time,'country':country,'produce_time':produce_time,'rating':rating,'rate_num':rate_num,'box_office':box_office, 'script':script, 'cast':cast_} return d #抓取加密部分 #字体库获取 def get_font_file(req, file_name): # 获取字体地址 font_url = re.findall(r'url\(\'(.*?)\'\)', req.text, re.S)[2] font_url = 'https:' + font_url #下载字体文件 req_font = requests.get(font_url, headers=h) with open(file_name, 'wb') as f: f.write(req_font.content) #创建模板 template_data = { 'uniE387':3, 'uniEDA2':9, 'uniE667':5, 'uniF350':0, 'uniF8BF':6, 'uniF4DA':8, 'uniE40E':2, 'uniF079':7, 'uniE295':4, 'uniF82F':1 } template_font = TTFont('stonefont.woff') #通过与模板比较判断字符是哪个数字 #计算两个字符间的平均距离 def cal_distance(list): d = 0 for p in list: x1, x2 = p d = d + sqrt(pow(x1[0]-x2[0],2)) + pow(x1[1]-x2[1],2) d = d/len(list) return d def deciphering(req, check_file): #提取网页中被加密的字符 encryption_num = re.findall(r'&#x(.*?);', req.text) encryption_num = set(encryption_num) #读取模板字体库信息 # template_font = TTFont(template_file) template_index = template_font.getGlyphOrder()[2:] #读取新的字体库信息 target_font = TTFont(check_file) #字体解密 correct_num = {} num = {} #遍历每个待计算的字符 for item in encryption_num: target = target_font['glyf']['uni'+item.upper()].coordinates dist_min = 1000000 #遍历每个模板字符 for index in template_index: template = template_font['glyf'][index].coordinates #不同字体库中的相同字符坐标数量不一样,人为确定一个可接受的差异范围10 if abs(len(target)-len(template))<10: dist = cal_distance(list(zip(target, template))) if dist < dist_min: dist_min = dist num[item] = index for item in encryption_num: correct_num['&#x'+item+';'] = template_data[num[item]] return correct_num #获取电影内页的url get_movie_url() #爬取字段 dt = pandas.DataFrame(columns=['name','name_eng','genres','release_time','country','produce_time','rating','rate_num','box_office', 'script', 'cast']) with open('film_code.txt','r') as f: lines = f.readlines() print(len(lines)) for line in lines: try: movie_url = 'https://maoyan.com/films/'+str(line.strip()) d = parse(movie_url) print(d) dt = dt.append(d, ignore_index=True) dt.to_excel('data.xlsx', encoding='utf8') except Exception as e: dt.to_excel('data.xlsx', encoding='utf8') print(e)
