第八周 进程的切换和系统的一般执行过程
第八周 进程的切换和系统的一般执行过程
【黎静 原创作品转载请注明出处 《Linux内核分析》MOOC课程http://mooc.study.163.com/course/USTC-1000029000】
一、进程切换关键代码switch_to
1.不同类型进程有不同调度需求——两种分类
进程分类
分类1
-
I/O-bound:等待I/O
-
CPU-bound:大量占用CPU进行计算
分类2
-
交互式进程(shell)
-
实时进程
-
批处理进程
进程调度策略
-
一组决定何时以何种方式选择进程的规则
-
Linux的调度基于分时和优先级策略:
-
进程根据优先级(系统根据特定算法计算出来)排队;
-
这个优先级的值表示如何适当分配CPU;
-
调度程序会根据进程的运行周期动态调整优先级;
-
比如nice等系统调用,可以手动调整优先级
-
-
调度策略本质上是一种算法,这些算法从实现的角度看仅仅是从运行队列中选择一个新进程,选择的过程中运用了不同的策略而已
-
内核中的调度算法相关代码使用了类似OOD中的策略模式
进程上下文包含了进程执行需要的所有信息
-
用户地址空间:包括程序代码,数据,用户堆栈等
-
控制信息:进程描述符,内核堆栈等
-
硬件上下文(与中断保存硬件上下文的方法不同)
代码

- switch_to完成寄存器的切换:先保存当前进程的寄存器,再进行堆栈切换(下图第44、45行)自此后所有的压栈都是在新进程的堆栈中了,再切换eip,这样当前进程可以从新进程中恢复,还有其他必要的切换
- next_ip一般是$1f(对于新创建的进程来说就是ret_from_fork)
- jmp __switch_to是函数调用,通过寄存器传递参数;函数执行结束return的时候从下一条指令开始(也就是认为是新进程的开始)
二、Linux系统的一般执行过程
1.从正在运行的用户态进程X到Y
X正在运行--->发生中断,可能陷入内核,CPU自动保存加载--->SAVE_ALL保存现场--->调用schedule,switch_to进程上下文切换--->标号1之后运行Y(之前有进行准备动作)--->restore_all恢复现场--->iret- pop cs:eip/ss:esp/eflags from kernel stack--->继续运行用户态进程Y
2.特殊情况
通过中断处理过程中的调度时机,用户态进程与内核线程之间互相切换和内核线程之间互相切换,与最一般的情况非常类似,只是内核线程运行过程中发生中断没有进程用户态和内核态的转换;
内核线程主动调用schedule(),只有进程上下文的切换,没有发生中断上下文的切换,与最一般的情况略简略;
创建子进程的系统调用在子进程中的执行起点及返回用户态,如fork;
加载一个新的可执行程序后返回到用户态的情况,如execve;
- 内核地址空间的4G中3G以上是内核态可以访问的——是所有进程共享的。
- 涉及中断、终端控制台设备驱动的概念。
3.内核——Taxi
三、Linux系统架构和执行过程
1.执行ls命令
过程:
shell分析-->调用系统调用fork生成一个shell本身拷贝-->调用exec系统调用将ls可执行文件装入内存-->从系统调用返回
四、实践
schedule()函数选择一个新的进程来运行,并调用context_switch进行上下文的切换,context_switch是一个宏,这个宏调用switch_to()函数来进行关键上下文切换
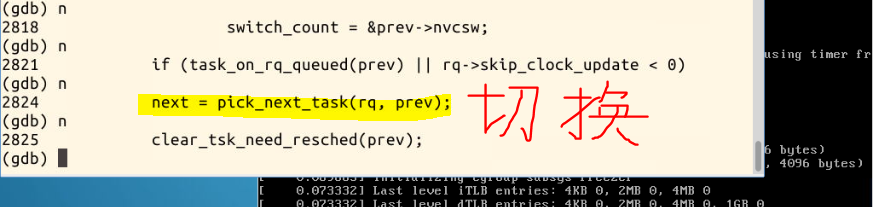
next = pick_next_task(rq, prev); //进程调度算法都封装这个函数内部
context_switch(rq, prev, next); //进程上下文切换
switch_to利用了prev和next两个参数:prev指向当前进程,next指向被调度的进程
- 在schedule处设置断点,点击c运行。【可以看到此时被冻结的内核开始运行直到schedule处】
- list查看断点所在代码段。可以与上图对照,发现第2804行即schedule()函数
- c之后按n单步执行,直到遇到__schedule函数,进入其中查看
-
- 继续执行,直到发现context_switch函数
-
- 设置断点后,设法进入其内部查看