自然语言处理
gensim word2vec
流程
https://www.cnblogs.com/iloveai/p/gensim_tutorial2.html
训练参数配置
skip-gram VS cbow
1. sg: 生僻词;
2.C: 效率;
Questions:
1. from keras.preprocessing.text import Tokenizer
文本转换为序列的对象
2.from keras.preprocessing.sequence import pad_sequence
import keras.preprocessing.sequence as S
S.pad_sequences([[1,2,3]],10,padding='post')
# [[1, 2, 3, 0, 0, 0, 0, 0, 0, 0]]
3. from keras.utils.np_utils import to_categorical
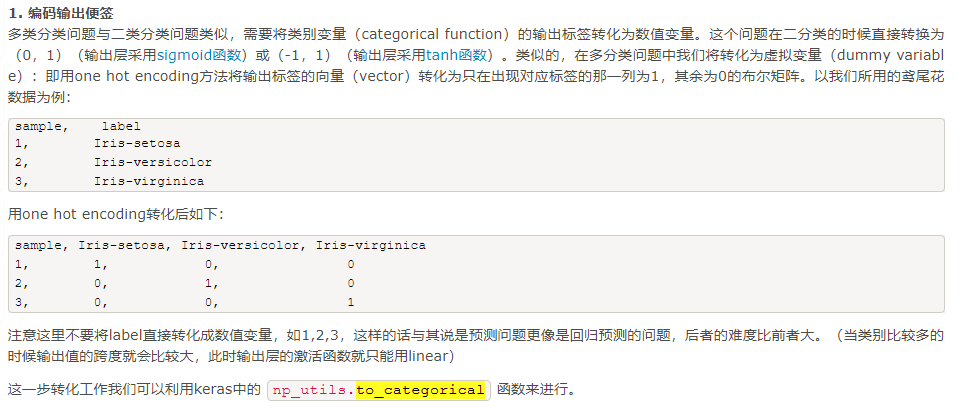
4. from keras.preprocessing.text import Tokenizer
import keras.preprocessing.text as T
from keras.preprocessing.text import Tokenizer
text1='some thing to eat'
text2='some thing to drink'
texts=[text1,text2]
print T.text_to_word_sequence(text1) #以空格区分,中文也不例外 ['some', 'thing', 'to', 'eat']
print T.one_hot(text1,10) #[7, 9, 3, 4] -- (10表示数字化向量为10以内的数字)
print T.one_hot(text2,10) #[7, 9, 3, 1]
tokenizer = Tokenizer(num_words=None) #num_words:None或整数,处理的最大单词数量。少于此数的单词丢掉
tokenizer.fit_on_texts(texts)
print( tokenizer.word_counts) #[('some', 2), ('thing', 2), ('to', 2), ('eat', 1), ('drink', 1)]
print( tokenizer.word_index) #{'some': 1, 'thing': 2,'to': 3 ','eat': 4, drink': 5}
print( tokenizer.word_docs) #{'some': 2, 'thing': 2, 'to': 2, 'drink': 1, 'eat': 1}
print( tokenizer.index_docs) #{1: 2, 2: 2, 3: 2, 4: 1, 5: 1}
# num_words=多少会影响下面的结果,行数=num_words
print( tokenizer.texts_to_sequences(texts)) #得到词索引[[1, 2, 3, 4], [1, 2, 3, 5]]
print( tokenizer.texts_to_matrix(texts)) # 矩阵化=one_hot
[[ 0., 1., 1., 1., 1., 0., 0., 0., 0., 0.],
[ 0., 1., 1., 1., 0., 1., 0., 0., 0., 0.]]
'''将新闻文档处理成单词索引序列,单词与序号之间的对应关系靠单词的索引表word_index来记录'''
#例-------------------------------------------------------------------------
tokenizer = Tokenizer(num_words=None) # 分词MAX_NB_WORDS
tokenizer.fit_on_texts(all_texts)
sequences = tokenizer.texts_to_sequences(all_texts) #受num_words影响
word_index = tokenizer.word_index # 词_索引
print('Found %s unique tokens.' % len(word_index))
data = pad_sequences(sequences, maxlen=MAX_SEQUENCE_LENGTH) #将长度不足 100 的新闻用 0 填充(在前端填充)
labels = to_categorical(np.asarray(all_labels)) #最后将标签处理成 one-hot 向量,比如 6 变成了 [0,0,0,0,0,0,1,0,0,0,0,0,0],
print('Shape of data tensor:', data.shape)
print('Shape of label tensor:', labels.shape)
# Shape of data tensor: (81, 1000) -- 81条数据
# Shape of label tensor: (81, 14)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号