Prometheus监控Linux主机(node-exporter)
Prometheus监控Linux主机
Prometheus node-exporter 监控Linux服务器
node-export 主要用来做Linux服务器监控,比如服务器的进程数、消耗了多少 CPU、内存,磁盘空间,iops,tcp连接数等资源。
Node Exporter 是用于暴露 *NIX 主机指标的 Exporter,比如采集 CPU、内存、磁盘等信息。采用 Go 编写,不存在任何第三方依赖,所以只需要下载解压即可运行。
Exporter是Prometheus的一类数据采集组件的总称。它负责从目标处搜集数据,并将其转化为Prometheus支持的格式。与传统的数据采集组件不同的是,它并不向中央服务器发送数据,而是等待中央服务器主动前来抓取。
node-exporter用于采集服务器层面的运行指标,包括机器的loadavg、filesystem、meminfo等基础监控,类似于传统主机监控维度的zabbix-agent
node_exporter:用于监控Linux系统的指标采集器。
常用指标:
•CPU
• 内存
• 硬盘
• 网络流量
• 文件描述符
• 系统负载
• 系统服务
数据接口:http://IP:9100/metrics
使用文档:https://prometheus.io/docs/guides/node-exporter/
GitHub:GitHub - prometheus/node_exporter: Exporter for machine metrics
一、node-exporter 使用
1.1 下载 node-exporter
node-exporter 下载地址:https://prometheus.io/download/
node-exporter 可以使用命令行参数也可以指定参数命令启动
1.2 配置node-exporter
该 metrics 接口数据就是一个标准的 Prometheus 监控指标格式,我们只需要将该端点配置到 Prometheus 中即可抓取该指标数据。为了了解 node_exporter 可配置的参数,我们可以使用 ./node_exporter -h 来查看帮助信息:
☸ ➜ ./node_exporter -h
--web.listen-address=":9100" # 监听的端口,默认是9100
--web.telemetry-path="/metrics" # metrics的路径,默认为/metrics
--web.disable-exporter-metrics # 是否禁用go、prome默认的metrics
--web.max-requests=40 # 最大并行请求数,默认40,设置为0时不限制
--log.level="info" # 日志等级: [debug, info, warn, error, fatal]
--log.format=logfmt # 置日志打印target和格式: [logfmt, json]
--version # 版本号
--collector.{metric-name} # 各个metric对应的参数
以使用 --collectors.enabled参数指定node_exporter收集的功能模块,或者用--no-collector指定不需要的模块,如果不指定,将使用默认配置。
最重要的参数就是 --collector.,通过该参数可以启用我们收集的功能模块,node_exporter 会默认采集一些模块,要禁用这些默认启用的收集器可以通过 --no-collector. 标志来禁用,如果只启用某些特定的收集器,基于先使用 --collector.disable-defaults 标志禁用所有默认的,然后在通过指定具体的收集器 --collector. 来进行启用。下图列出了默认启用的收集器:

1.3 编写启动脚本
创建prometheus组和用户
sudo groupadd -r prometheus
sudo useradd -r -g prometheus -s /sbin/nologin -M -c "prometheus Daemons" prometheus
vim /usr/lib/systemd/system/node_exporter.service
[Unit]
Description=node_exporter
After=network.target
#可以创建相应的用户和组 启动
User=prometheus
Group=prometheus
[Service]
ExecStart=/usr/local/node_exporter/node_exporter\
--web.listen-address=:9100\
--collector.systemd\
--collector.systemd.unit-whitelist=(sshd|nginx).service\
--collector.processes\
--collector.tcpstat
[Install]
WantedBy=multi-user.target
1.4 启动 node_exporter
systemctl daemon-reload
systemctl start process_exporter
systemctl enable process_exporter
验证监控数据
curl http://localhost:9100/metrics
二、prometheus 配置
添加或修改配置
- job_name: 'dev_prometheus'
scrape_interval: 10s
honor_labels: true
metrics_path: '/metrics'
static_configs:
- targets: ['127.0.0.1:9090','127.0.0.1:9100']
labels: {cluster: 'dev',type: 'basic',env: 'dev',job: 'prometheus',export: 'node-exporter'}
- targets: ['127.0.0.1:9256']
labels: {cluster: 'dev',type: 'process',env: 'dev',job: 'prometheus',export: 'process_exporter'}
重启 prometheus 服务
curl -X POST http://127.0.0.1:9090/-/reload
三、grafana 出图
process-exporter 对应的 dashboard 为:https://grafana.com/grafana/dashboards/16098-1-node-exporter-for-prometheus-dashboard-cn-0417-job/
效果如下
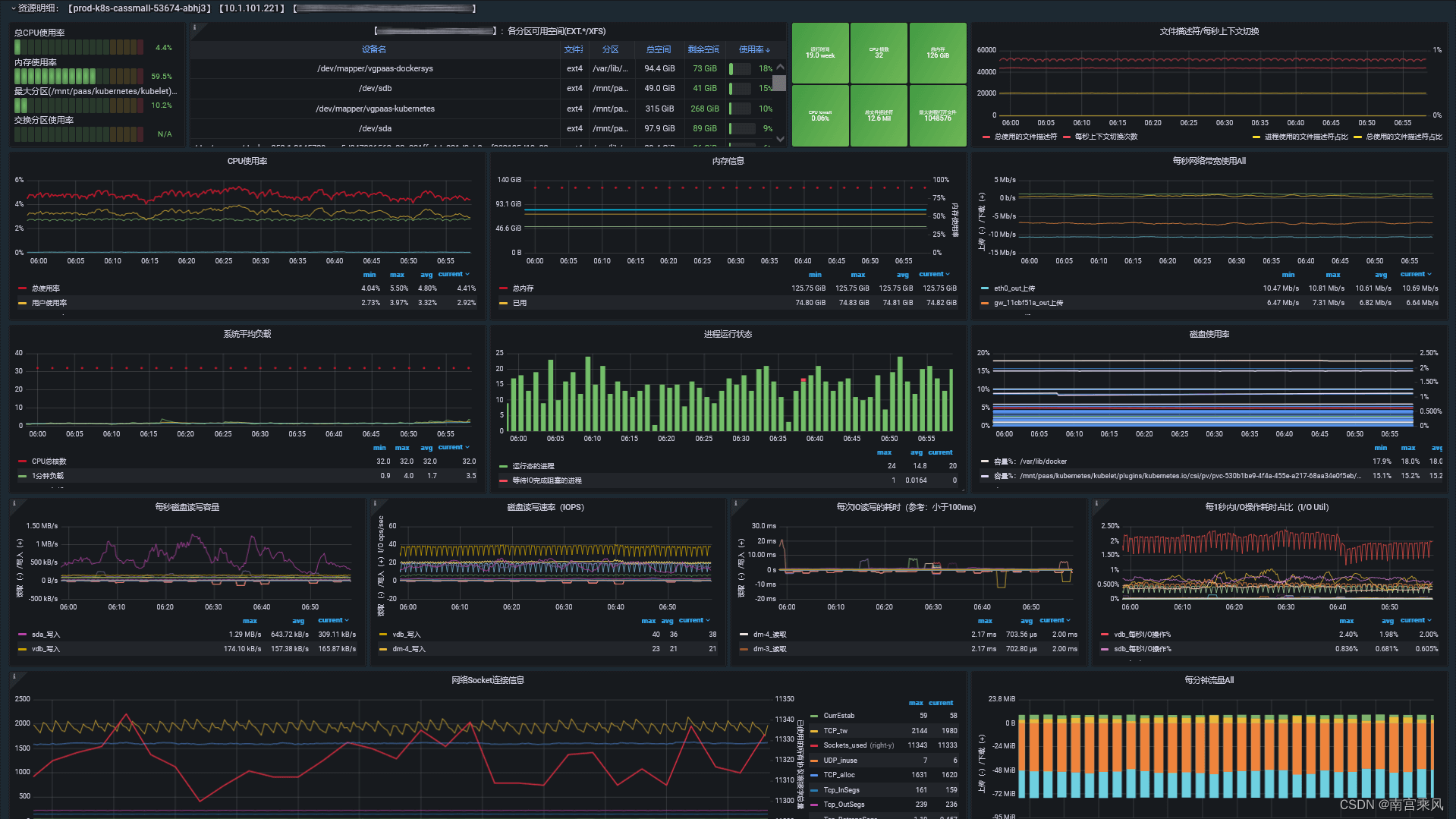
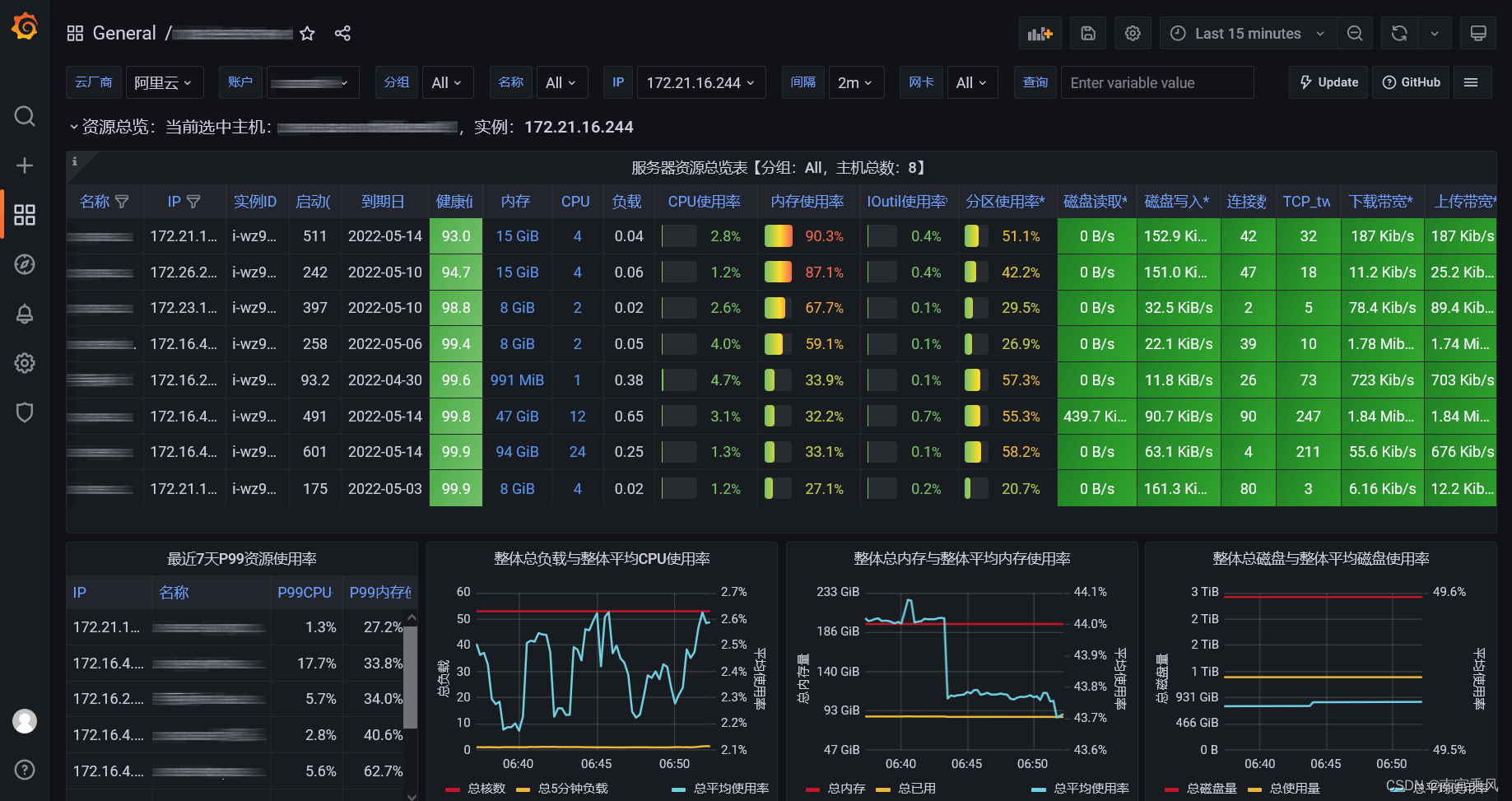
四、常用监控规则
参考网站:https://awesome-prometheus-alerts.grep.to/rules
这个网站上有好多常用软件的告警规则,但是有些并不一定实用,有些使用起来会有错误,这里就把这些都给排除掉,只保留能使用的
结合文章:https://www.cnblogs.com/sanduzxcvbnm/p/13589792.html 来使用
groups:
- name: 主机状态-监控告警
rules:
- alert: 主机状态
expr: up == 0
for: 1m
labels:
status: 非常严重
annotations:
summary: "{{$labels.instance}}:服务器宕机"
description: "{{$labels.instance}}:服务器延时超过5分钟"
- alert: CPU使用情况
expr: 100-(avg(irate(node_cpu_seconds_total{mode="idle"}[5m])) by(instance)* 100) > 60
for: 1m
labels:
status: 一般告警
annotations:
summary: "{{$labels.mountpoint}} CPU使用率过高!"
description: "{{$labels.mountpoint }} CPU使用大于60%(目前使用:{{$value}}%)"
- alert: 内存使用
expr: 100 -(node_memory_MemTotal_bytes -node_memory_MemFree_bytes+node_memory_Buffers_bytes+node_memory_Cached_bytes ) / node_memory_MemTotal_bytes * 100> 80
for: 1m
labels:
status: 严重告警
annotations:
summary: "{{$labels.mountpoint}} 内存使用率过高!"
description: "{{$labels.mountpoint }} 内存使用大于80%(目前使用:{{$value}}%)"
- alert: IO性能
expr: 100-(avg(irate(node_disk_io_time_seconds_total[1m])) by(instance)* 100) < 60
for: 1m
labels:
status: 严重告警
annotations:
summary: "{{$labels.mountpoint}} 流入磁盘IO使用率过高!"
description: "{{$labels.mountpoint }} 流入磁盘IO大于60%(目前使用:{{$value}})"
- alert: 网络
expr: ((sum(rate (node_network_receive_bytes_total{device!~'tap.*|veth.*|br.*|docker.*|virbr*|lo*'}[5m])) by (instance)) / 100) > 102400
for: 1m
labels:
status: 严重告警
annotations:
summary: "{{$labels.mountpoint}} 流入网络带宽过高!"
description: "{{$labels.mountpoint }}流入网络带宽持续2分钟高于100M. RX带宽使用率{{$value}}"
- alert: 网络
expr: ((sum(rate (node_network_transmit_bytes_total{device!~'tap.*|veth.*|br.*|docker.*|virbr*|lo*'}[5m])) by (instance)) / 100) > 102400
for: 1m
labels:
status: 严重告警
annotations:
summary: "{{$labels.mountpoint}} 流出网络带宽过高!"
description: "{{$labels.mountpoint }}流出网络带宽持续2分钟高于100M. RX带宽使用率{{$value}}"
- alert: TCP会话
expr: node_netstat_Tcp_CurrEstab > 1000
for: 1m
labels:
status: 严重告警
annotations:
summary: "{{$labels.mountpoint}} TCP_ESTABLISHED过高!"
description: "{{$labels.mountpoint }} TCP_ESTABLISHED大于1000%(目前使用:{{$value}}%)"
- alert: 磁盘容量
expr: 100-(node_filesystem_free_bytes{fstype=~"ext4|xfs"}/node_filesystem_size_bytes {fstype=~"ext4|xfs"}*100) > 80
for: 1m
labels:
status: 严重告警
annotations:
summary: "{{$labels.mountpoint}} 磁盘分区使用率过高!"
description: "{{$labels.mountpoint }} 磁盘分区使用大于80%(目前使用:{{$value}}%)"
五、Ansible 批量添加部署

这里采用 Consul 注册发现方式,相关类容可以查询网上
5.1Consul 注册脚本
#!/bin/bash
service_name=$1
instance_id=$2
ip=$3
port=$4
curl -X PUT -d '{"id": "'"$instance_id"'","name": "'"$service_name"'","address": "'"$ip"'","port": '"$port"',"tags": ["'"$service_name"'"],"checks": [{"http": "http://'"$ip"':'"$port"'","interval": "5s"}]}' http://10.1.8.202:8500/v1/agent/service/register
5.2 Ansible 剧本脚本
[root@openvpn node]# cat playbook.yml
- hosts: Sm
remote_user: root
gather_facts: no
tasks:
- name: 推送采集器安装包
unarchive: src=node_exporter-1.2.2.linux-amd64.tar.gz dest=/usr/local/
- name: 重命名
shell: |
cd /usr/local/
if [ ! -d node_exporter ];then
mv node_exporter-1.2.2.linux-amd64 node_exporter
fi
- name: 查询主机名称
shell: echo "`hostname`"
register: name_host
- name: 推送system文件
copy: src=node_exporter.service dest=/usr/lib/systemd/system
- name: 启动服务
systemd: name=node_exporter state=started enabled=yes
- name: 推送注册脚本
copy: src=consul-register.sh dest=/usr/local/node_exporter
- name: 注册当前节点
shell: /bin/sh /usr/local/node_exporter/consul-register.sh {{ group_names[0] }} {{ name_host.stdout }} {{ inventory_hostname }} 9100
六、指标自定义监控
6.1 自定义监控
node_exporter的–collector.textfile是一个收集器,这个收集器可以允许我们暴露自定义指标,比如某些pushgateway功能中自定义的指标,就可以使用–collector.textfile功能来实现,而且,node_exporter实现起来更加优雅。用node_expoerter ,直接在现在基础上做textfile collector即可。如果有pushgateway的话,可是使用pushgateway的,也可以使用textfilecollector。
node_exporter的collector.textfile 功能自定义监控,collector.text收集器通过扫描指定目录中的文件,提取所有格式为Prometheus指标的字符串,然后暴露它们以便抓取
参数:–collector.textfile.directory
6.2 Textfile Collector使用
因为node_exporter之前已经安装过,如果node_exporter启动时没有指定–collector.textfile.directory参数,需要在启动文件里面,添加上参数,并确认文件指的目录存在。
[root@openvpn disk]# cat node_exporter.service
[Unit]
Description=node_exporter
After=network.target
[Service]
ExecStart=/usr/local/node_exporter/node_exporter\
--web.listen-address=:9100\
--collector.systemd\
--collector.systemd.unit-whitelist=(sshd|nginx).service\
--collector.processes\
--collector.tcpstat\
--collector.supervisord\
--collector.textfile.directory="/usr/local/node_exporter"
#指定以的监控目录
[Install]
WantedBy=multi-user.target
6.3 启动
#启动
# systemd 方式启动
systemctl daemon-reload
systemctl enable node_exporter
systemctl start node_exporter
systemctl status node_exporter
# supervisor方式启动
supervisorctl update
supervisorctl status
supervisorctl start node_exporter
supervisorctl restart node_exporter
#检查是否启动成功
ss -untlp |grep 9100
ps -ef |grep node_exporter
6.4 写入自定义指标
写入自定义指标,这个需要自己开发脚本,将数据写入对应的文件即可。也可以在github(点我点我…)中看实例文件,熟悉python或者shell都可以写。
GitHub 中有提供模板的,比如 directory-size.sh
# cat directory-size.sh
#!/bin/sh
#
# Expose directory usage metrics, passed as an argument.
#
# Usage: add this to crontab:
#
# */5 * * * * prometheus directory-size.sh /var/lib/prometheus | sponge /var/lib/node_exporter/directory_size.prom
#
# sed pattern taken from https://www.robustperception.io/monitoring-directory-sizes-with-the-textfile-collector/
#
# Author: Antoine Beaupré <anarcat@debian.org>
echo "# HELP node_directory_size_bytes Disk space used by some directories"
echo "# TYPE node_directory_size_bytes gauge"
du --block-size=1 --summarize "$@" \
| sed -ne 's/\\/\\\\/;s/"/\\"/g;s/^\([0-9]\+\)\t\(.*\)$/node_directory_size_bytes{directory="\2"} \1/p'
此处是我给的简单shell脚本获取数据
[root@openvpn disk]# cat disk_cheak.sh
#!/bin/sh
system=$(lsblk -fs |grep -w / |awk '{print $1}')
disk=$(lsblk -rfs|grep -E 'xfs|f2fs|ntfs'| grep -v $system|awk '{print $5}' |awk -F '%' '{print $1}' |wc -l)
theNum=$( df -h |grep /data/plot |wc -l)
name="check_disk_nums"
pool_nums=$(tail -n 1 /root/hpool/log/miner.log.log | awk '{print $6}'|cut -d '=' -f 2|awk -F '[ "]' '{print $4,$NF}'|awk '{sub(/^[\t ]*/,"");print}')
CPU_sensors=$(sensors | grep "^Package id 0:" | sed 's/Package id 0://' | sed 's/^\s*.+//' | awk '{print $1}' | sed 's/°C//')
echo "check_cpu_sensors $CPU_sensors" > /usr/local/node_exporter/check_cpu_sensors.prom
echo "check_pool_nums $pool_nums" > /usr/local/node_exporter/check_pool_nums.prom
if [ $disk != $theNum ]; then
echo "$name 0" > /usr/local/node_exporter/check_disk_nums.prom
else
echo "$name $disk" > /usr/local/node_exporter/check_disk_nums.prom
fi
6.5 配置定时任务启动
chmod a+x disk_cheak.sh
crontab -l
#Ansible: check_disk
*/5 * * * * /bin/bash /usr/local/node_exporter/disk_cheak.sh

6.6 ansible批量添加执行

[root@openvpn disk]# cat playbook.yml
- hosts: all
remote_user: root
gather_facts: no
tasks:
- name: 推送system文件
copy: src=node_exporter.service dest=/usr/lib/systemd/system
- name: 开机启动服务
systemd: name=node_exporter state=restarted enabled=yes
- name: 推送磁盘脚本
copy: src=disk_cheak.sh dest=/usr/local/node_exporter mode=u+x
- name: 设置定时任务
cron: name="check_disk" minute="*/5" job="/bin/bash /usr/local/node_exporter/disk_cheak.sh" state="present"
- name: 执行脚本
shell: /bin/bash /usr/local/node_exporter/disk_cheak.sh
执行命令
ansible-playbook playbook.yml -i ./hosts1 -f 10
6.7 验证数据


