


App爬虫神器mitmproxy和mitmdump的使用
mitmproxy是一个支持HTTP和HTTPS的抓包程序,有类似Fiddler、Charles的功能,只不过它是一个控制台的形式操作。
mitmproxy还有两个关联组件。一个是mitmdump,它是mitmproxy的命令行接口,利用它我们可以对接Python脚本,用Python实现监听后的处理。另一个是mitmweb,它是一个Web程序,通过它我们可以清楚观察mitmproxy捕获的请求。
下面我们来了解它们的用法。
一、准备工作
请确保已经正确安装好了mitmproxy,并且手机和PC处于同一个局域网下,同时配置好了mitmproxy的CA证书。
二、mitmproxy的功能
mitmproxy有如下几项功能。
![]() 拦截HTTP和HTTPS请求和响应。
拦截HTTP和HTTPS请求和响应。![]() 保存HTTP会话并进行分析。
保存HTTP会话并进行分析。![]() 模拟客户端发起请求,模拟服务端返回响应。
模拟客户端发起请求,模拟服务端返回响应。![]() 利用反向代理将流量转发给指定的服务器。
利用反向代理将流量转发给指定的服务器。![]() 支持Mac和Linux上的透明代理。
支持Mac和Linux上的透明代理。
![]() 利用Python对HTTP请求和响应进行实时处理。
利用Python对HTTP请求和响应进行实时处理。
三、抓包原理
和Charles一样,mitmproxy运行于自己的PC上,mitmproxy会在PC的8080端口运行,然后开启一个代理服务,这个服务实际上是一个HTTP/HTTPS的代理。
手机和PC在同一个局域网内,设置代理为mitmproxy的代理地址,这样手机在访问互联网的时候流量数据包就会流经mitmproxy,mitmproxy再去转发这些数据包到真实的服务器,服务器返回数据包时再由mitmproxy转发回手机,这样mitmproxy就相当于起了中间人的作用,抓取到所有Request和Response,另外这个过程还可以对接mitmdump,抓取到的Request和Response的具体内容都可以直接用Python来处理,比如得到Response之后我们可以直接进行解析,然后存入数据库,这样就完成了数据的解析和存储过程。
四、设置代理
首先,我们需要运行mitmproxy,命令如下所示:
启动mitmproxy的命令如下:
mitmproxy
之后会在8080端口上运行一个代理服务,如下图所示。
右下角会出现当前正在监听的端口。
或者启动mitmdump,它也会监听8080端口,命令如下所示:
mitmdump
运行结果如下图所示。

将手机和PC连接在同一局域网下,设置代理为当前代理。首先看看PC的当前局域网IP。
Windows上的命令如下所示:
ipconfig
Linux和Mac上的命令如下所示:
ifconfig
输出结果如下图所示。
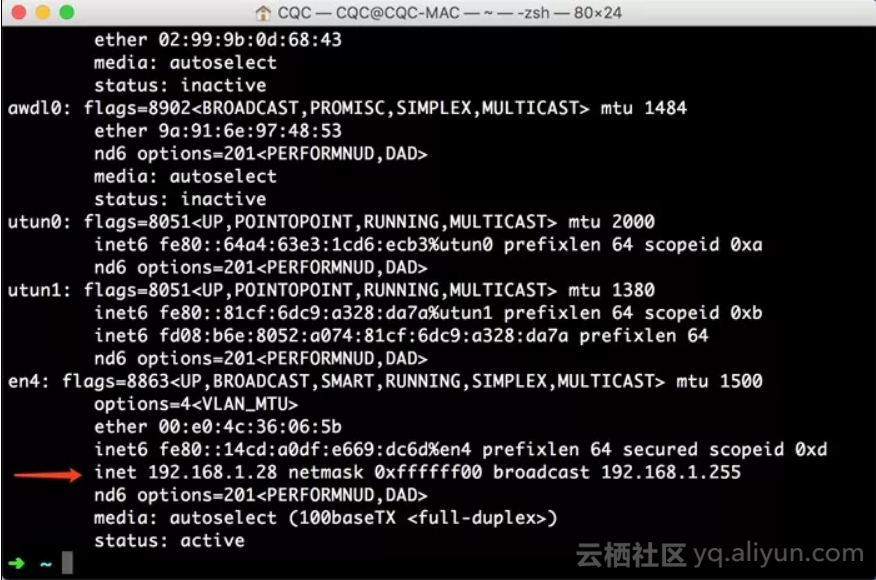
一般类似10.*.*.*或172.16.*.*或192.168.1.*这样的IP就是当前PC的局域网IP,例如此图中PC的IP为192.168.1.28,手机代理设置类似如下图所示。
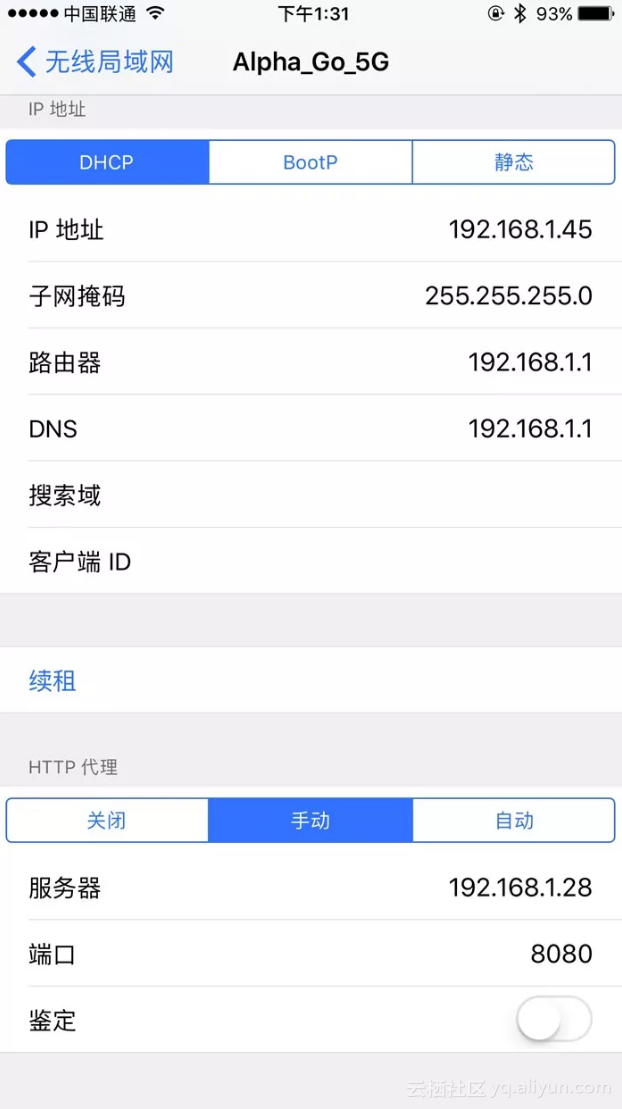
这样我们就配置好了mitmproxy的的代理。
五、mitmproxy的使用
确保mitmproxy正常运行,并且手机和PC处于同一个局域网内,设置了mitmproxy的代理,具体的配置方法可以参考官方文档。
运行mitmproxy,命令如下所示:
mitmproxy
设置成功之后,我们只需要在手机浏览器上访问任意的网页或浏览任意的App即可。例如在手机上打开百度,mitmproxy页面便会呈现出手机上的所有请求,如下图所示。
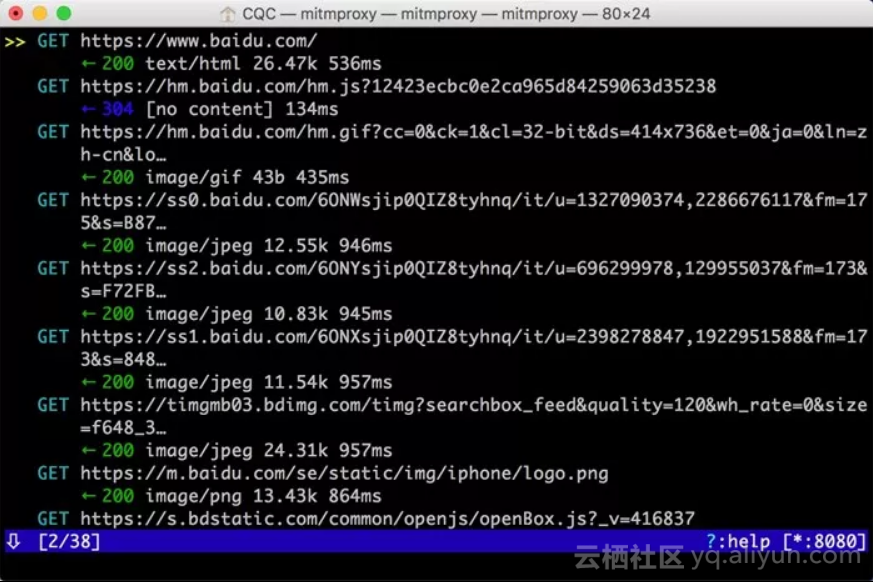
这就相当于之前我们在浏览器开发者工具监听到的浏览器请求,在这里我们借助于mitmproxy完成。Charles完全也可以做到。
这里是刚才手机打开百度页面时的所有请求列表,左下角显示的2/38代表一共发生了38个请求,当前箭头所指的是第二个请求。
每个请求开头都有一个GET或POST,这是各个请求的请求方式。紧接的是请求的URL。第二行开头的数字就是请求对应的响应状态码,后面是响应内容的类型,如text/html代表网页文档、image/gif代表图片。再往后是响应体的大小和响应的时间。
当前呈现了所有请求和响应的概览,我们可以通过这个页面观察到所有的请求。
如果想查看某个请求的详情,我们可以敲击回车,进入请求的详情页面,如下图所示。
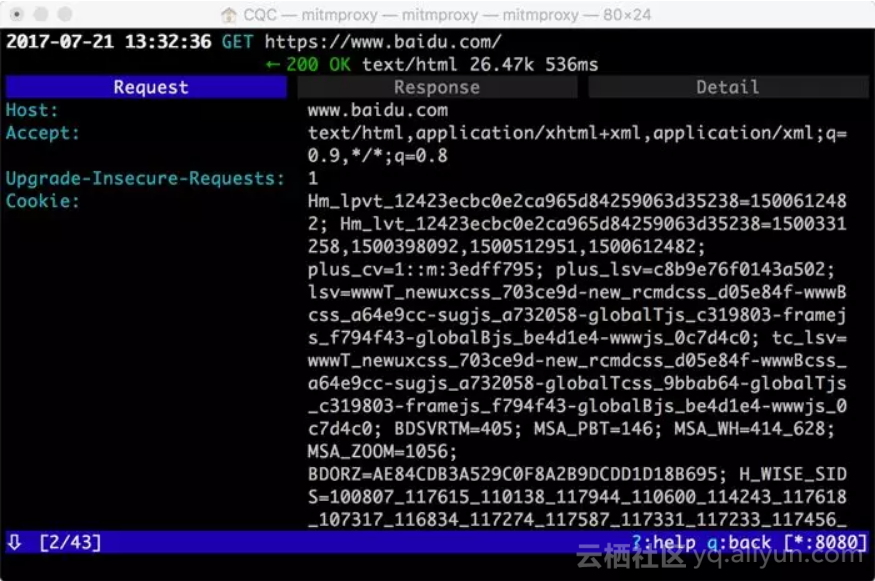
可以看到Headers的详细信息,如Host、Cookies、User-Agent等。
最上方是一个Request、Response、Detail的列表,当前处在Request这个选项上。这时我们再点击TAB键,即可查看这个请求对应的响应详情,如下图所示。
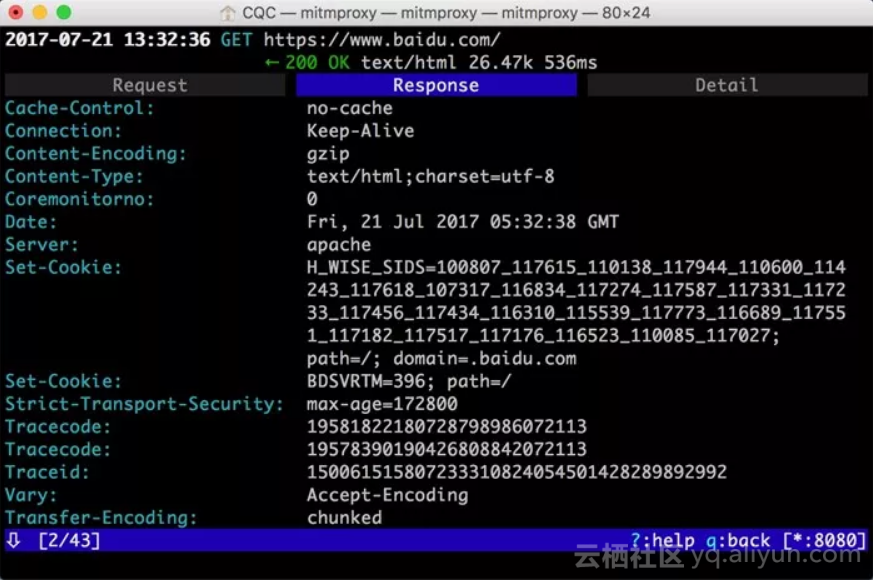
最上面是响应头的信息,下拉之后我们可以看到响应体的信息。针对当前请求,响应体就是网页的源代码。
这时再敲击TAB键,切换到最后一个选项卡Detail,即可看到当前请求的详细信息,如服务器的IP和端口、HTTP协议版本、客户端的IP和端口等,如下图所示。
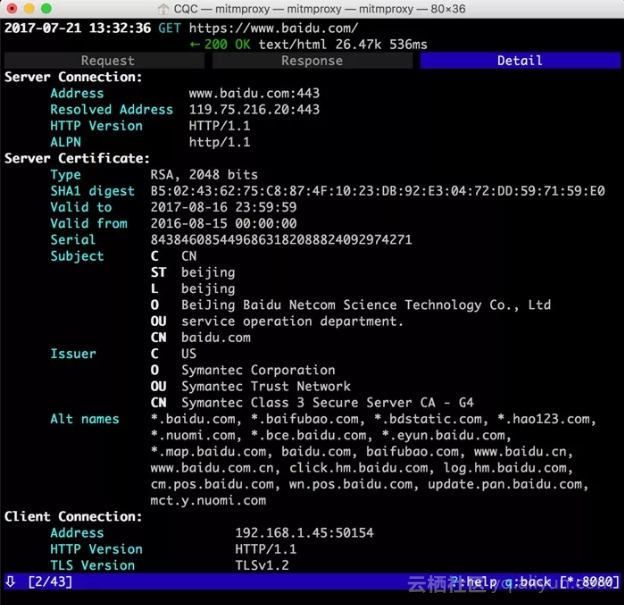
mitmproxy还提供了命令行式的编辑功能,我们可以在此页面中重新编辑请求。敲击e键即可进入编辑功能,这时它会询问你要编辑哪部分内容,如Cookies、Query、URL等,每个选项的第一个字母会高亮显示。敲击要编辑内容名称的首字母即可进入该内容的编辑页面,如敲击m即可编辑请求的方式,敲击q即可修改GET请求参数Query。
这时我们敲击q,进入到编辑Query的页面。由于没有任何参数,我们可以敲击a来增加一行,然后就可以输入参数对应的Key和Value,如下图所示。
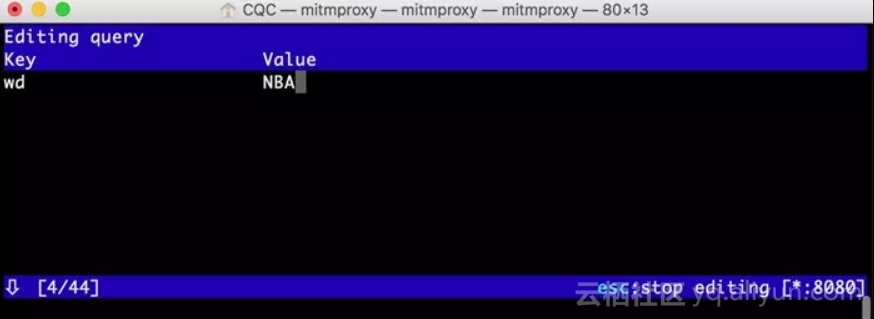
这里我们输入Key为wd,Value为NBA。
然后再敲击esc键和q键,返回之前的页面,再敲击e和p键修改Path。和上面一样,敲击a增加Path的内容,这时我们将Path修改为s,如下图所示。
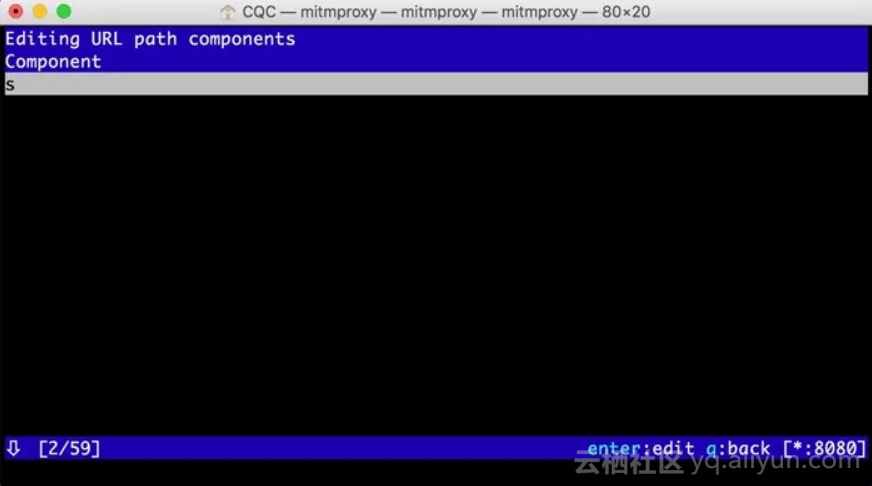
再敲击esc和q键返回,这时我们可以看到最上面的请求链接变成了:https://www.baidu.com/s?wd=NBA。访问这个页面,可以看到百度搜索NBA关键词的搜索结果,如下图所示。
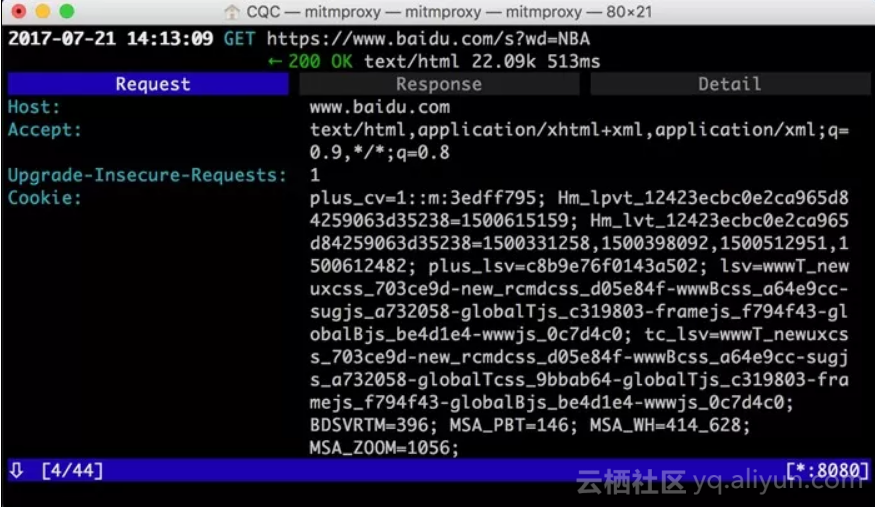
敲击a保存修改,敲击r重新发起修改后的请求,即可看到上方请求方式前面多了一个回旋箭头,这说明重新执行了修改后的请求。这时我们再观察响应体内容,即可看到搜索NBA的页面结果的源代码,如下图所示。
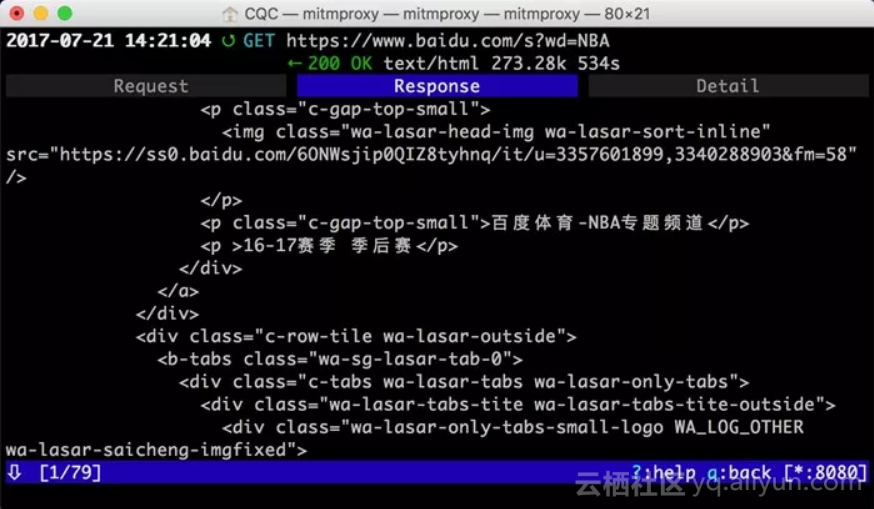
以上内容便是mitmproxy的简单用法。利用mitmproxy,我们可以观察到手机上的所有请求,还可以对请求进行修改并重新发起。
Fiddler、Charles也有这个功能,而且它们的图形界面操作更加方便。那么mitmproxy的优势何在?
mitmproxy的强大之处体现在它的另一个工具mitmdump,有了它我们可以直接对接Python对请求进行处理。下面我们来看看mitmdump的用法。
六、mitmdump的使用
mitmdump是mitmproxy的命令行接口,同时还可以对接Python对请求进行处理,这是相比Fiddler、Charles等工具更加方便的地方。有了它我们可以不用手动截获和分析HTTP请求和响应,只需写好请求和响应的处理逻辑即可。它还可以实现数据的解析、存储等工作,这些过程都可以通过Python实现。
1. 实例引入
我们可以使用命令启动mitmproxy,并把截获的数据保存到文件中,命令如下所示:
mitmdump -w outfile
其中outfile的名称任意,截获的数据都会被保存到此文件中。
还可以指定一个脚本来处理截获的数据,使用-s参数即可:
mitmdump -s script.py
这里指定了当前处理脚本为script.py,它需要放置在当前命令执行的目录下。
我们可以在脚本里写入如下的代码:
def request(flow):
flow.request.headers['User-Agent'] = 'MitmProxy'
print(flow.request.headers)
我们定义了一个request()方法,参数为flow,它其实是一个HTTPFlow对象,通过request属性即可获取到当前请求对象。然后打印输出了请求的请求头,将请求头的User-Agent修改成了MitmProxy。
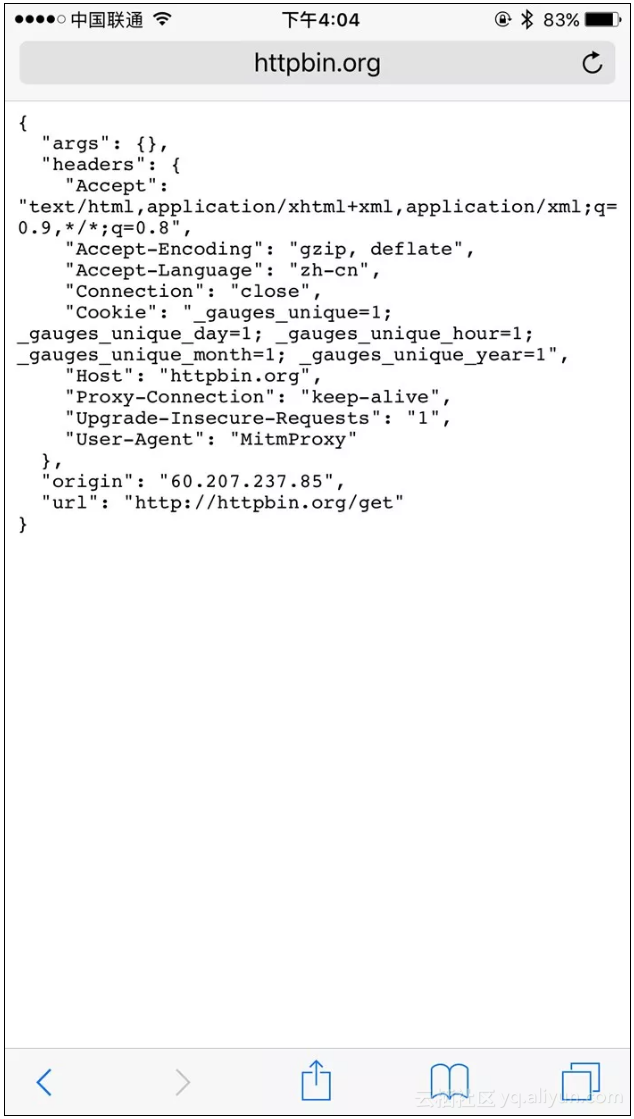
运行之后我们在手机端访问http://httpbin.org/get,可以看到如下情况发生。
手机端的页面显示如下图所示。
PC端控制台输出如下图所示。
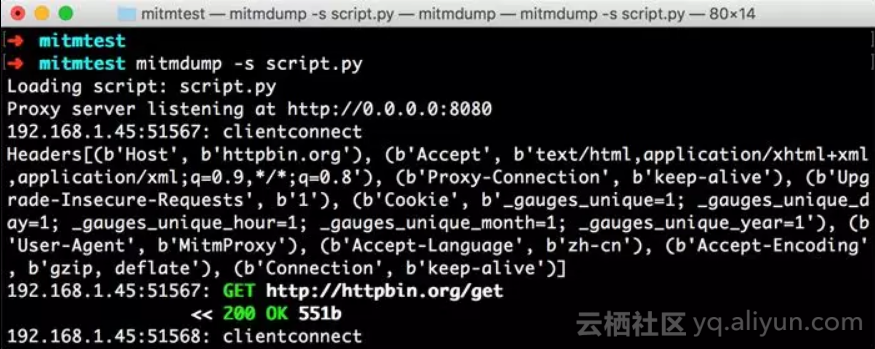
手机端返回结果的Headers实际上就是请求的Headers,User-Agent被修改成了mitmproxy。PC端控制台输出了修改后的Headers内容,其User-Agent的内容正是mitmproxy。
所以,通过这三行代码我们就可以完成对请求的改写。print()方法输出结果可以呈现在PC端控制台上,可以方便地进行调试。
2. 日志输出
mitmdump提供了专门的日志输出功能,可以设定不同级别以不同颜色输出结果。我们把脚本修改成如下内容:
from mitmproxy import ctx
def request(flow):
flow.request.headers['User-Agent'] = 'MitmProxy'
ctx.log.info(str(flow.request.headers))
ctx.log.warn(str(flow.request.headers))
ctx.log.error(str(flow.request.headers))
这里调用了ctx模块,它有一个log功能,调用不同的输出方法就可以输出不同颜色的结果,以方便我们做调试。例如,info()方法输出的内容是白色的,warn()方法输出的内容是黄色的,error()方法输出的内容是红色的。运行结果如下图所示。
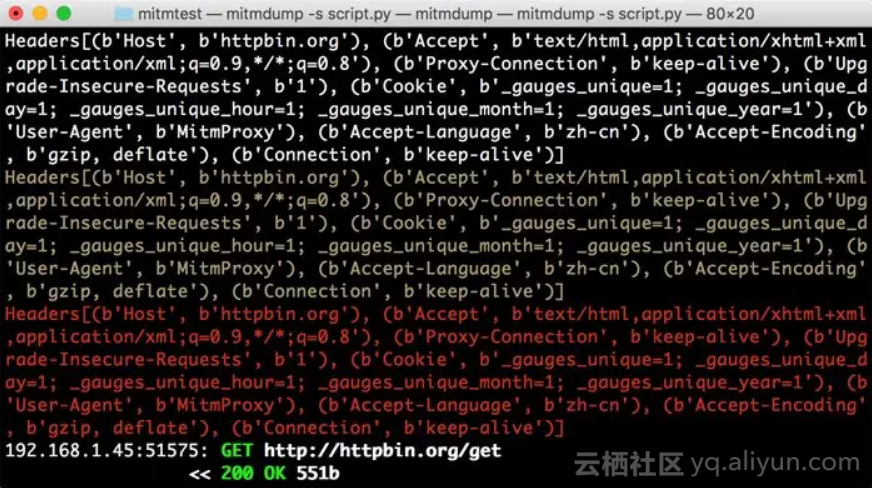
不同的颜色对应不同级别的输出,我们可以将不同的结果合理划分级别输出,以更直观方便地查看调试信息。
3. Request
最开始我们实现了request()方法并且对Headers进行了修改。下面我们来看看Request还有哪些常用的功能。我们先用一个实例来感受一下。
我们修改脚本,然后在手机上打开百度,即可看到PC端控制台输出了一系列的请求,在这里我们找到第一个请求。控制台打印输出了Request的一些常见属性,如URL、Headers、Cookies、Host、Method、Scheme等。输出结果如下图所示。
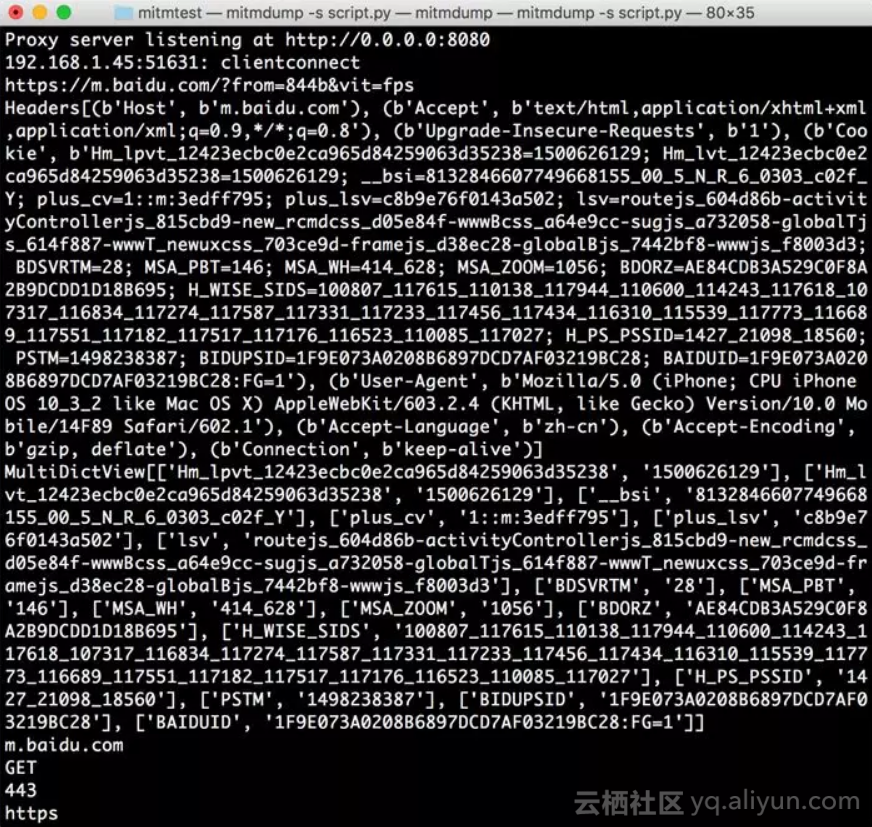
结果中分别输出了请求链接、请求头、请求Cookies、请求Host、请求方法、请求端口、请求协议这些内容。
同时我们还可以对任意属性进行修改,就像最初修改Headers一样,直接赋值即可。例如,这里将请求的URL修改一下,脚本修改如下所示:
def request(flow):
url = 'https://httpbin.org/get'
flow.request.url = url
手机端得到如下结果,如下图所示。

比较有意思的是,浏览器最上方还是呈现百度的URL,但是页面已经变成了httpbin.org的页面了。另外,Cookies明显还是百度的Cookies。我们只是用简单的脚本就成功把请求修改为其他的站点。通过这种方式修改和伪造请求就变得轻而易举。
通过这个实例我们知道,有时候URL虽然是正确的,但是内容并非是正确的。我们需要进一步提高自己的安全防范意识。
Request还有很多属性,在此不再一一列举。更多属性可以参考:http://docs.mitmproxy.org/en/latest/scripting/api.html。
只要我们了解了基本用法,会很容易地获取和修改Reqeust的任意内容,比如可以用修改Cookies、添加代理等方式来规避反爬。
4. Response
对于爬虫来说,我们更加关心的其实是Response的内容,因为Response Body才是爬取的结果。对于Response来说,mitmdump也提供了对应的处理接口,就是response()方法。下面我们用一个实例感受一下。
from mitmproxy import ctx
def response(flow):
response = flow.response
info = ctx.log.info
info(str(response.status_code))
info(str(response.headers))
info(str(response.cookies))
info(str(response.text))
将脚本修改为如上内容,然后手机访问:http://httpbin.org/get。
这里打印输出了Response的status_code、headers、cookies、text这几个属性,其中最主要的text属性就是网页的源代码。
PC端控制台输出如下图所示。
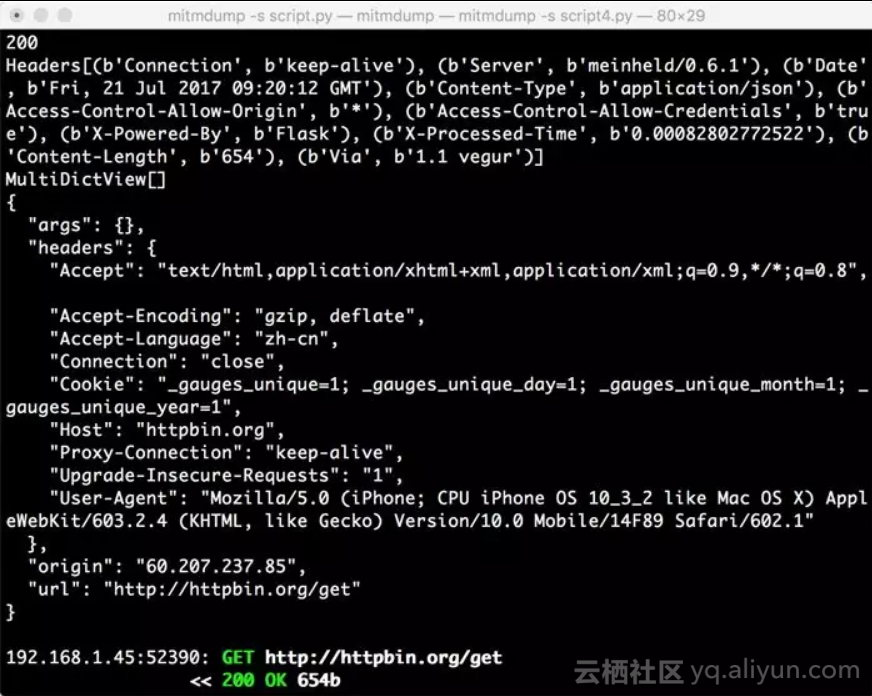
控制台输出了Response的状态码、响应头、Cookies、响应体这几部分内容。
我们可以通过response()方法获取每个请求的响应内容。接下来再进行响应的信息提取和存储,我们就可以成功完成爬取了。

