
Linux内核--网络栈实现分析(七)--数据包的传递过程(下)
本文分析基于Linux Kernel 1.2.13
原创作品,转载请标明http://blog.csdn.net/yming0221/article/details/7545855
更多请查看专栏,地址http://blog.csdn.net/column/details/linux-kernel-net.html
作者:闫明
注:标题中的”(上)“,”(下)“表示分析过程基于数据包的传递方向:”(上)“表示分析是从底层向上分析、”(下)“表示分析是从上向下分析。
在博文Linux内核--网络栈实现分析(二)--数据包的传递过程(上)中分析了数据包从网卡设备经过驱动链路层,网络层,传输层到应用层的过程。
本文就分析一下本机产生数据是如何通过传输层,网络层到达物理层的。
综述来说,数据流程图如下:
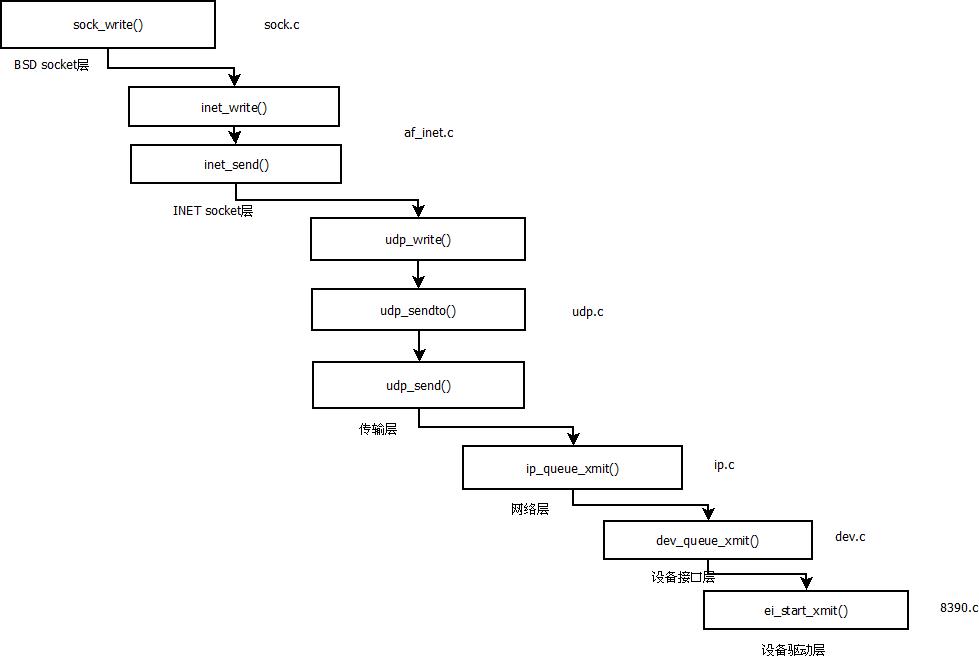
一、应用层
应用层可以通过系统调用或文件操作来调用内核函数,BSD层的sock_write()函数会调用INET层的inet_wirte()函数。
- /*
- * Write data to a socket. We verify that the user area ubuf..ubuf+size-1 is
- * readable by the user process.
- */
- static int sock_write(struct inode *inode, struct file *file, char *ubuf, int size)
- {
- struct socket *sock;
- int err;
- if (!(sock = socki_lookup(inode)))
- {
- printk("NET: sock_write: can't find socket for inode!\n");
- return(-EBADF);
- }
- if (sock->flags & SO_ACCEPTCON)
- return(-EINVAL);
- if(size<0)
- return -EINVAL;
- if(size==0)
- return 0;
- if ((err=verify_area(VERIFY_READ,ubuf,size))<0)
- return err;
- return(sock->ops->write(sock, ubuf, size,(file->f_flags & O_NONBLOCK)));
- }
INET层会调用具体传输层协议的write函数,该函数是通过调用本层的inet_send()函数实现功能的,inet_send()函数的UDP协议对应的函数为udp_write()
- static int inet_send(struct socket *sock, void *ubuf, int size, int noblock,
- unsigned flags)
- {
- struct sock *sk = (struct sock *) sock->data;
- if (sk->shutdown & SEND_SHUTDOWN)
- {
- send_sig(SIGPIPE, current, 1);
- return(-EPIPE);
- }
- if(sk->err)
- return inet_error(sk);
- /* We may need to bind the socket. */
- if(inet_autobind(sk)!=0)
- return(-EAGAIN);
- return(sk->prot->write(sk, (unsigned char *) ubuf, size, noblock, flags));
- }
- static int inet_write(struct socket *sock, char *ubuf, int size, int noblock)
- {
- return inet_send(sock,ubuf,size,noblock,0);
- }
二、传输层
在传输层udp_write()函数调用本层的udp_sendto()函数完成功能。
- /*
- * In BSD SOCK_DGRAM a write is just like a send.
- */
- static int udp_write(struct sock *sk, unsigned char *buff, int len, int noblock,
- unsigned flags)
- {
- return(udp_sendto(sk, buff, len, noblock, flags, NULL, 0));
- }
udp_send()函数完成sk_buff结构相应的设置和报头的填写后会调用udp_send()来发送数据。具体的实现过程后面会详细分析。
而在udp_send()函数中,最后会调用ip_queue_xmit()函数,将数据包下放的网络层。
下面是udp_prot定义:
- struct proto udp_prot = {
- sock_wmalloc,
- sock_rmalloc,
- sock_wfree,
- sock_rfree,
- sock_rspace,
- sock_wspace,
- udp_close,
- udp_read,
- udp_write,
- udp_sendto,
- udp_recvfrom,
- ip_build_header,
- udp_connect,
- NULL,
- ip_queue_xmit,
- NULL,
- NULL,
- NULL,
- udp_rcv,
- datagram_select,
- udp_ioctl,
- NULL,
- NULL,
- ip_setsockopt,
- ip_getsockopt,
- 128,
- 0,
- {NULL,},
- "UDP",
- 0, 0
- };
- static int udp_send(struct sock *sk, struct sockaddr_in *sin,
- unsigned char *from, int len, int rt)
- {
- struct sk_buff *skb;
- struct device *dev;
- struct udphdr *uh;
- unsigned char *buff;
- unsigned long saddr;
- int size, tmp;
- int ttl;
- /*
- * Allocate an sk_buff copy of the packet.
- */
- ........................
- /*
- * Now build the IP and MAC header.
- */
- ..........................
- /*
- * Fill in the UDP header.
- */
- ..............................
- /*
- * Copy the user data.
- */
- memcpy_fromfs(buff, from, len);
- /*
- * Set up the UDP checksum.
- */
- udp_send_check(uh, saddr, sin->sin_addr.s_addr, skb->len - tmp, sk);
- /*
- * Send the datagram to the interface.
- */
- udp_statistics.UdpOutDatagrams++;
- sk->prot->queue_xmit(sk, dev, skb, 1);
- return(len);
- }
三、网络层
在网络层,函数ip_queue_xmit()的功能是将数据包进行一系列复杂的操作,比如是检查数据包是否需要分片,是否是多播等一系列检查,最后调用dev_queue_xmit()函数发送数据。
- /*
- * Queues a packet to be sent, and starts the transmitter
- * if necessary. if free = 1 then we free the block after
- * transmit, otherwise we don't. If free==2 we not only
- * free the block but also don't assign a new ip seq number.
- * This routine also needs to put in the total length,
- * and compute the checksum
- */
- void ip_queue_xmit(struct sock *sk, struct device *dev,
- struct sk_buff *skb, int free)
- {
- struct iphdr *iph;
- unsigned char *ptr;
- /* Sanity check */
- ............
- /*
- * Do some book-keeping in the packet for later
- */
- ...........
- /*
- * Find the IP header and set the length. This is bad
- * but once we get the skb data handling code in the
- * hardware will push its header sensibly and we will
- * set skb->ip_hdr to avoid this mess and the fixed
- * header length problem
- */
- ..............
- /*
- * No reassigning numbers to fragments...
- */
- if(free!=2)
- iph->id = htons(ip_id_count++);
- else
- free=1;
- /* All buffers without an owner socket get freed */
- if (sk == NULL)
- free = 1;
- skb->free = free;
- /*
- * Do we need to fragment. Again this is inefficient.
- * We need to somehow lock the original buffer and use
- * bits of it.
- */
- ................
- /*
- * Add an IP checksum
- */
- ip_send_check(iph);
- /*
- * Print the frame when debugging
- */
- /*
- * More debugging. You cannot queue a packet already on a list
- * Spot this and moan loudly.
- */
- .......................
- /*
- * If a sender wishes the packet to remain unfreed
- * we add it to his send queue. This arguably belongs
- * in the TCP level since nobody else uses it. BUT
- * remember IPng might change all the rules.
- */
- ......................
- /*
- * If the indicated interface is up and running, send the packet.
- */
- ip_statistics.IpOutRequests++;
- .............................
- .............................
- if((dev->flags&IFF_BROADCAST) && iph->daddr==dev->pa_brdaddr && !(dev->flags&IFF_LOOPBACK))
- ip_loopback(dev,skb);
- if (dev->flags & IFF_UP)
- {
- /*
- * If we have an owner use its priority setting,
- * otherwise use NORMAL
- */
- if (sk != NULL)
- {
- dev_queue_xmit(skb, dev, sk->priority);
- }
- else
- {
- dev_queue_xmit(skb, dev, SOPRI_NORMAL);
- }
- }
- else
- {
- ip_statistics.IpOutDiscards++;
- if (free)
- kfree_skb(skb, FREE_WRITE);
- }
- }
四、驱动层(链路层)
在函数中,函数调用会调用具体设备的发送函数来发送数据包
dev->hard_start_xmit(skb, dev);
具体设备的发送函数在网络初始化的时候已经设置了。
这里以8390网卡为例来说明驱动层的工作原理,在net/drivers/8390.c中函数ethdev_init()函数中设置如下:
- /* Initialize the rest of the 8390 device structure. */
- int ethdev_init(struct device *dev)
- {
- if (ei_debug > 1)
- printk(version);
- if (dev->priv == NULL) {//申请私有空间
- struct ei_device *ei_local;//8390网卡设备的结构体
- dev->priv = kmalloc(sizeof(struct ei_device), GFP_KERNEL);//申请内核内存空间
- memset(dev->priv, 0, sizeof(struct ei_device));
- ei_local = (struct ei_device *)dev->priv;
- #ifndef NO_PINGPONG
- ei_local->pingpong = 1;
- #endif
- }
- /* The open call may be overridden by the card-specific code. */
- if (dev->open == NULL)
- dev->open = &ei_open;//设备的打开函数
- /* We should have a dev->stop entry also. */
- dev->hard_start_xmit = &ei_start_xmit;//设备的发送函数,定义在8390.c中
- dev->get_stats = get_stats;
- #ifdef HAVE_MULTICAST
- dev->set_multicast_list = &set_multicast_list;
- #endif
- ether_setup(dev);
- return 0;
- }
驱动中的发送函数比较复杂,和硬件关系紧密,这里不再详细分析。
这样就大体分析了下网络数据从应用层到物理层的数据通路,后面会详细分析。


