
Linux内核--网络协议栈深入分析(二)--sk_buff的操作函数
本文分析基于Linux Kernel 3.2.1
原创作品,转载请标明http://blog.csdn.net/yming0221/article/details/7972647
更多请查看网络栈分析专栏http://blog.csdn.net/column/details/linux-kernel-net.html
作者:闫明
1、alloc_skb()函数
该函数的作用是在上层协议要发送数据包的时候或网络设备准备接收数据包的时候会调用alloc_skb()函数分配sk_buff结构体,需要释放时调用kfree_skb()函数。
- static inline struct sk_buff *alloc_skb(unsigned int size,
- gfp_t priority)
- {
- return __alloc_skb(size, priority, 0, NUMA_NO_NODE);
- }
这里使用内联函数,非内联函数调用会进堆栈的切换,造成额外的开销,而内联函数可以解决这一点,可以提高执行效率,只是增加了程序的空间开销。
函数调用需要时间和空间开销,调用函数实际上将程序执行流程转移到被调函数中,被调函数的代码执行完后,再返回到调用的地方。这种调用操作要求调用前保护好现场并记忆执行的地址,返回后恢复现场,并按原来保存的地址继续执行。对于较长的函数这种开销可以忽略不计,但对于一些函数体代码很短,又被频繁调用的函数,就不能忽视这种开销。引入内联函数正是为了解决这个问题,提高程序的运行效率。
- /* Allocate a new skbuff. We do this ourselves so we can fill in a few
- * 'private' fields and also do memory statistics to find all the
- * [BEEP] leaks.
- *
- */
- /**
- * __alloc_skb - allocate a network buffer
- * @size: size to allocate
- * @gfp_mask: allocation mask
- * @fclone: allocate from fclone cache instead of head cache
- * and allocate a cloned (child) skb
- * @node: numa node to allocate memory on
- *
- * Allocate a new &sk_buff. The returned buffer has no headroom and a
- * tail room of size bytes. The object has a reference count of one.
- * The return is the buffer. On a failure the return is %NULL.
- *
- * Buffers may only be allocated from interrupts using a @gfp_mask of
- * %GFP_ATOMIC.
- */
- struct sk_buff *__alloc_skb(unsigned int size, gfp_t gfp_mask,
- int fclone, int node)
- {
- struct kmem_cache *cache;
- struct skb_shared_info *shinfo;
- struct sk_buff *skb;
- u8 *data;
- cache = fclone ? skbuff_fclone_cache : skbuff_head_cache;
- /* Get the HEAD */
- skb = kmem_cache_alloc_node(cache, gfp_mask & ~__GFP_DMA, node);//分配存储空间
- if (!skb)
- goto out;//分配失败,返回NULL
- prefetchw(skb);
- /* We do our best to align skb_shared_info on a separate cache
- * line. It usually works because kmalloc(X > SMP_CACHE_BYTES) gives
- * aligned memory blocks, unless SLUB/SLAB debug is enabled.
- * Both skb->head and skb_shared_info are cache line aligned.
- */
- size = SKB_DATA_ALIGN(size);//调整skb大小
- size += SKB_DATA_ALIGN(sizeof(struct skb_shared_info));
- data = kmalloc_node_track_caller(size, gfp_mask, node);//分配数据区
- if (!data)
- goto nodata;
- /* kmalloc(size) might give us more room than requested.
- * Put skb_shared_info exactly at the end of allocated zone,
- * to allow max possible filling before reallocation.
- */
- size = SKB_WITH_OVERHEAD(ksize(data));
- prefetchw(data + size);
- /*
- * Only clear those fields we need to clear, not those that we will
- * actually initialise below. Hence, don't put any more fields after
- * the tail pointer in struct sk_buff!
- */
- //sk_buff结构体中最后6个属性不能改变位置,只能在最后
- memset(skb, 0, offsetof(struct sk_buff, tail));//将sk_buff结构体中tail属性之前的属性清零
- /* Account for allocated memory : skb + skb->head */
- skb->truesize = SKB_TRUESIZE(size);//计算缓冲区的尺寸
- atomic_set(&skb->users, 1);
- //初始化数据区的指针
- skb->head = data;
- skb->data = data;
- skb_reset_tail_pointer(skb);
- skb->end = skb->tail + size;
- #ifdef NET_SKBUFF_DATA_USES_OFFSET
- skb->mac_header = ~0U;
- #endif
- /* make sure we initialize shinfo sequentially */
- //初始化skb_shared_info
- shinfo = skb_shinfo(skb);
- memset(shinfo, 0, offsetof(struct skb_shared_info, dataref));
- atomic_set(&shinfo->dataref, 1);
- kmemcheck_annotate_variable(shinfo->destructor_arg);
- if (fclone) {
- struct sk_buff *child = skb + 1;
- atomic_t *fclone_ref = (atomic_t *) (child + 1);
- kmemcheck_annotate_bitfield(child, flags1);
- kmemcheck_annotate_bitfield(child, flags2);
- skb->fclone = SKB_FCLONE_ORIG;
- atomic_set(fclone_ref, 1);
- child->fclone = SKB_FCLONE_UNAVAILABLE;
- }
- out:
- return skb;
- nodata:
- kmem_cache_free(cache, skb);
- skb = NULL;
- goto out;
- }
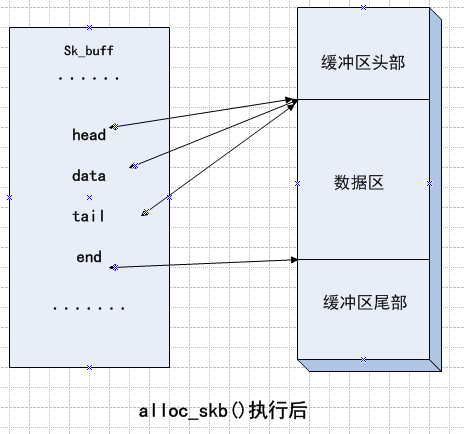
2、kfree_skb()函数
该函数就是释放不被使用的sk_buff结构
- /**
- * kfree_skb - free an sk_buff
- * @skb: buffer to free
- *
- * Drop a reference to the buffer and free it if the usage count has
- * hit zero.
- */
- void kfree_skb(struct sk_buff *skb)
- {
- if (unlikely(!skb))
- return;
- if (likely(atomic_read(&skb->users) == 1))
- smp_rmb();
- else if (likely(!atomic_dec_and_test(&skb->users)))
- return;
- trace_kfree_skb(skb, __builtin_return_address(0));
- __kfree_skb(skb);
- }
- void __kfree_skb(struct sk_buff *skb)
- {
- skb_release_all(skb);//释放除了skb本身占用的内存
- kfree_skbmem(skb);
- }
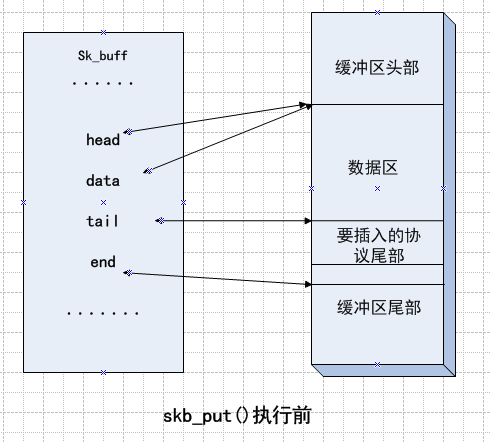
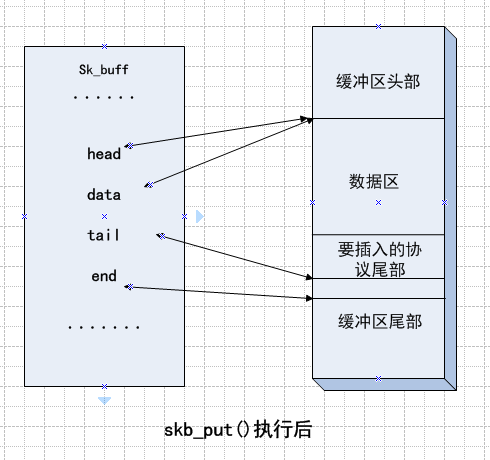
3、skb_put()函数
该函数是在数据区的末端添加某协议的尾部
- /**
- * skb_put - add data to a buffer
- * @skb: buffer to use
- * @len: amount of data to add
- *
- * This function extends the used data area of the buffer. If this would
- * exceed the total buffer size the kernel will panic. A pointer to the
- * first byte of the extra data is returned.
- */
- unsigned char *skb_put(struct sk_buff *skb, unsigned int len)
- {
- unsigned char *tmp = skb_tail_pointer(skb);
- SKB_LINEAR_ASSERT(skb);
- skb->tail += len;//尾部后移len
- skb->len += len;//长度增加len
- if (unlikely(skb->tail > skb->end))//panic
- skb_over_panic(skb, len, __builtin_return_address(0));
- return tmp;
- }
执行前后的示意图如下:
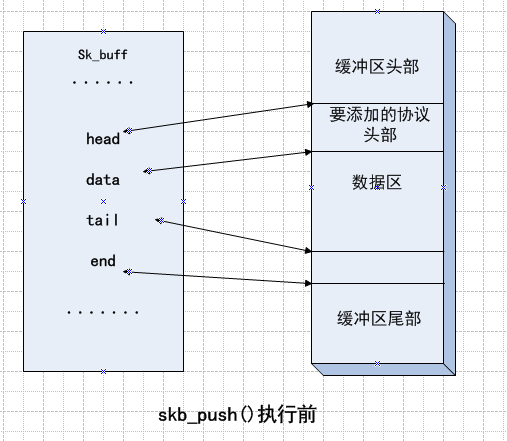
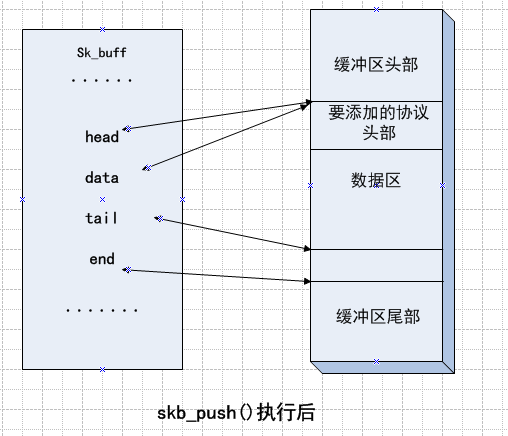
4、skb_push()函数
该函数的作用是在数据区的前端添加某协议的头部,和skb_put类似。
只不过这里移动的数据指针的是data前移len个单位。
- unsigned char *skb_push(struct sk_buff *skb, unsigned int len)
- {
- skb->data -= len;
- skb->len += len;
- if (unlikely(skb->data<skb->head))
- skb_under_panic(skb, len, __builtin_return_address(0));
- return skb->data;
- }
5、skb_pull和skb_trim函数正好和上面两个函数的功能相反,是去掉相应的部分,不再赘述。
6、skb_reverse()函数
该函数的作用是在数据区创建存储协议头部的空间,函数实现很简单。
- static inline void skb_reserve(struct sk_buff *skb, int len)
- {
- skb->data += len;
- skb->tail += len;
- }
7、sk_buff缓冲区链表的操作函数
skb_orphan()函数是将一个缓冲结构体变成孤立的skb
- static inline void skb_orphan(struct sk_buff *skb)
- {
- if (skb->destructor)
- skb->destructor(skb);
- skb->destructor = NULL;
- skb->sk = NULL;
- }
skb_queue_head_init()函数将初始化sk_buff_head结构体
- static inline void skb_queue_head_init(struct sk_buff_head *list)
- {
- spin_lock_init(&list->lock);
- __skb_queue_head_init(list);
- }
skb_queue_head()在链表头添加一个sk_buff结构
- void skb_queue_head(struct sk_buff_head *list, struct sk_buff *newsk)
- {
- unsigned long flags;
- spin_lock_irqsave(&list->lock, flags);
- __skb_queue_head(list, newsk);
- spin_unlock_irqrestore(&list->lock, flags);
- }
调用__skb_queue_head()函数实现功能
- static inline void __skb_queue_head(struct sk_buff_head *list,
- struct sk_buff *newsk)
- {
- __skb_queue_after(list, (struct sk_buff *)list, newsk);
- }
- static inline void __skb_queue_after(struct sk_buff_head *list,
- struct sk_buff *prev,
- struct sk_buff *newsk)
- {
- __skb_insert(newsk, prev, prev->next, list);
- }
最后用函数__skb_insert操作双链表
- static inline void __skb_insert(struct sk_buff *newsk,
- struct sk_buff *prev, struct sk_buff *next,
- struct sk_buff_head *list)
- {
- newsk->next = next;
- newsk->prev = prev;
- next->prev = prev->next = newsk;
- list->qlen++;
- }
函数skb_queue_tail() 在缓冲区链表尾部添加新的skb
函数skb_dequeue() 在链表头部移走一个skb
函数skb_dequeue_tail() 在链表尾部移走一个skb
函数skb_queue_purge() 清空一个由sk_buff_head管理的缓冲区链表,具体操作如下:
- void skb_queue_purge(struct sk_buff_head *list)
- {
- struct sk_buff *skb;
- while ((skb = skb_dequeue(list)) != NULL)
- kfree_skb(skb);
- }


