import requests
from bs4 import BeautifulSoup
from datetime import datetime
newsurl='http://news.gzcc.cn/html/xiaoyuanxinwen/'
res = requests.get(newsurl)
res.encoding='utf-8'
soup = BeautifulSoup(res.text,'html.parser')
li=soup.select_one(".news-list").select("li")
for i in li:
#标题
title=i.select_one(".news-list-title").text
#链接
url=i.a.attrs.get('href')
res1 = requests.get(url)
res1.encoding = 'utf-8'
soup1 = BeautifulSoup(res1.text, 'html.parser')
#正文
content=soup1.select_one("#content").text
info=soup1.select_one(".show-info").text
#发布时间
time=datetime.strptime(info.lstrip("发布时间:")[:19],"%Y-%m-%d %H:%M:%S")
#作者
author=info[info.find("作者:"):].split()[0].lstrip("作者:")
#来源
x=info.find("来源:")
if x>=0:
source=info[x:].split()[0].lstrip("来源:")
else:
source=""
#摄影
x = info.find("摄影:")
if x >= 0:
shot = info[x:].split()[0].lstrip("摄影:")
else:
shot = ""
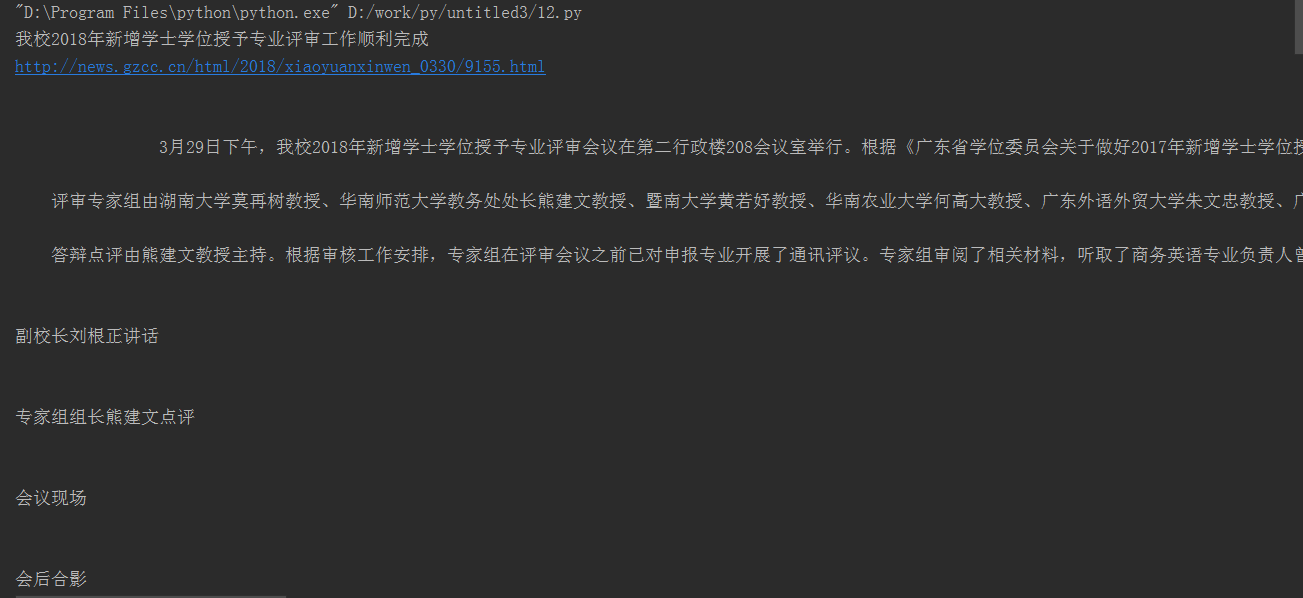
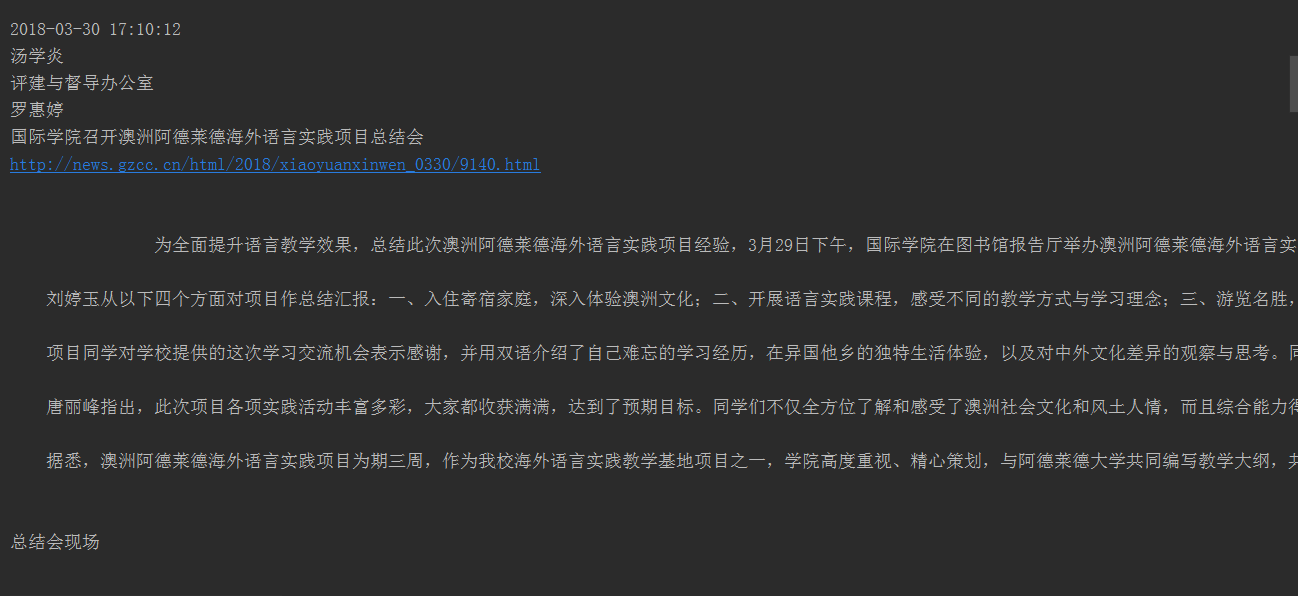
print(title)
print(url)
print(content)
print(time)
print(author)
print(source)
print(shot)