
初学Hadoop之中文词频统计
1、安装eclipse
准备
eclipse-dsl-luna-SR2-linux-gtk-x86_64.tar.gz
安装
1、解压文件。
2、创建图标。
ln -s /opt/eclipse/eclipse /usr/bin/eclipse #使符号链接目录
vim /usr/share/applications/eclipse.desktop #创建一个 Gnome 启动

添加如下代码:
[Desktop Entry]
Encoding=UTF-8
Name=Eclipse 4.4.2
Comment=Eclipse Luna
Exec=/usr/bin/eclipse
Icon=/opt/eclipse/icon.xpm
Categories=Application;Development;Java;IDE
Version=1.0
Type=Application
Terminal=0

完成以后则会出现下图中的图标。

至此,eclipse安装完成。
2、安装hadoop插件
1、下载插件http://pan.baidu.com/s/1ydUEy 。
2、将插件放到/opt/eclipse/plugins文件夹下。
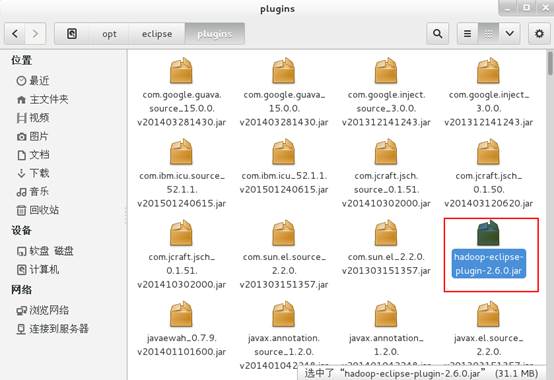
3、在eclipse->Windows->preferences设置Hadoop路径。
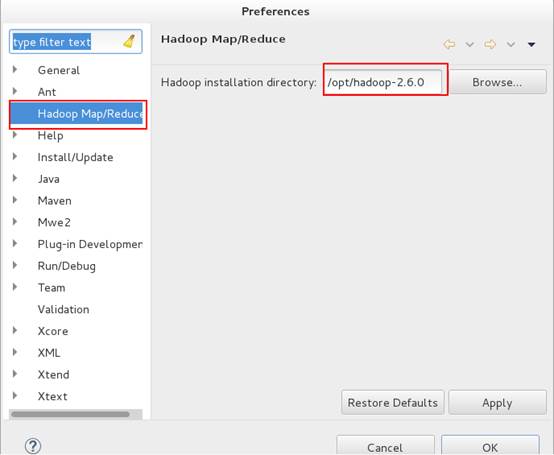
至此,插件安装完成。
3、ChineseWordCount源码
package com.example.test; import java.io.IOException; import java.io.InputStream; import java.io.InputStreamReader; import java.io.Reader; import java.io.ByteArrayInputStream; import org.wltea.analyzer.core.IKSegmenter; import org.wltea.analyzer.core.Lexeme; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.util.GenericOptionsParser; public class ChineseWordCount { public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> { private final static IntWritable one = new IntWritable(1); private Text word = new Text(); public void map(Object key, Text value, Context context) throws IOException, InterruptedException { byte[] bt = value.getBytes(); InputStream ip = new ByteArrayInputStream(bt); Reader read = new InputStreamReader(ip); IKSegmenter iks = new IKSegmenter(read, true); Lexeme t; while ((t = iks.next()) != null) { word.set(t.getLexemeText()); context.write(word, one); } } } public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> { private IntWritable result = new IntWritable(); public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int sum = 0; for (IntWritable val : values) { sum += val.get(); } result.set(sum); context.write(key, result); } } public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); String[] otherArgs = new GenericOptionsParser(conf, args) .getRemainingArgs(); if (otherArgs.length != 2) { System.err.println("Usage: wordcount <in> <out>"); System.exit(2); } Job job = new Job(conf, "word count"); job.setJarByClass(ChineseWordCount.class); job.setMapperClass(TokenizerMapper.class); job.setCombinerClass(IntSumReducer.class); job.setReducerClass(IntSumReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); FileInputFormat.addInputPath(job, new Path(otherArgs[0])); FileOutputFormat.setOutputPath(job, new Path(otherArgs[1])); System.exit(job.waitForCompletion(true) ? 0 : 1); } }
4、创建Hadoop工程
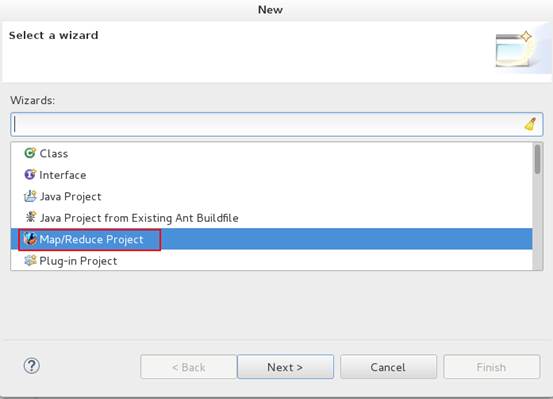
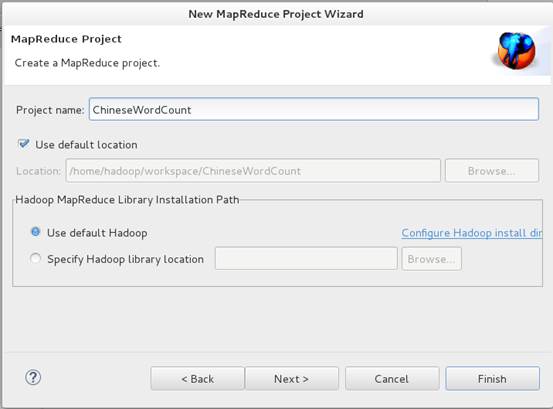
1、创建一个Map/Reduce Project,名称为ChineseWordCount。
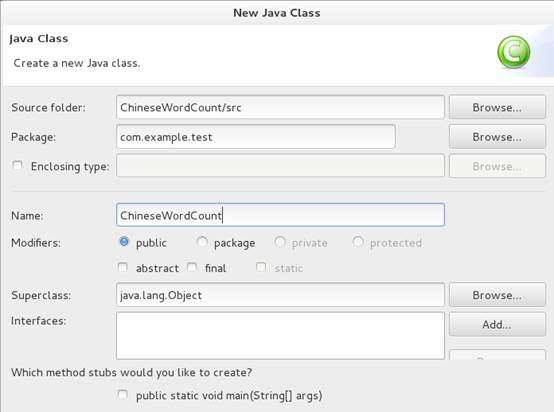
2、创建包com.example.test,创建ChineseWordCount类文件。
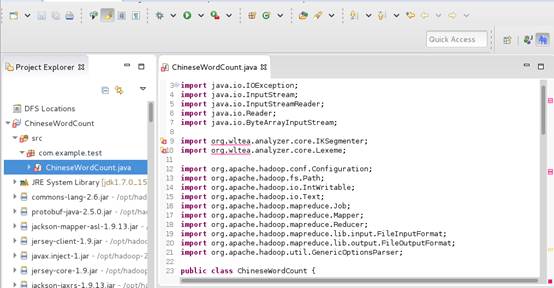
3、导入IkAnalyzer包。
下载地址:http://code.google.com/p/ik-analyzer/
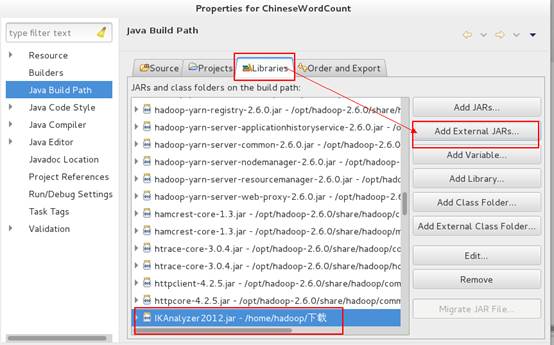
至此,Hadoop工程新建完成。
5、运行工程
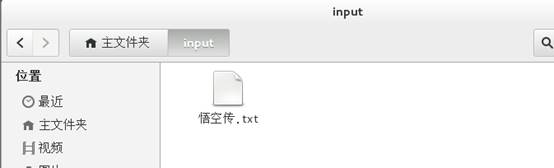
1、在/home/hadoop/目录下新建一个input文件夹,将中文文本"悟空传.txt"复制到里面。

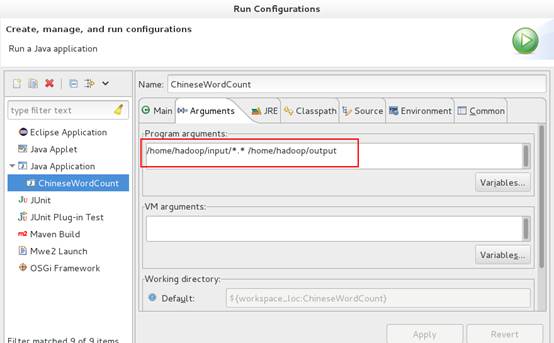
2、在eclipse中设置运行参数。
操作时遇到一个问题,当运行参数设置成/opt/hadoop-2.6.0/input/*.* /opt/hadoop-2.6.0/output时,无法运行成功,我想会不会是访问权限的问题,这个下次再解决。
3、点击运行。
6、查看结果

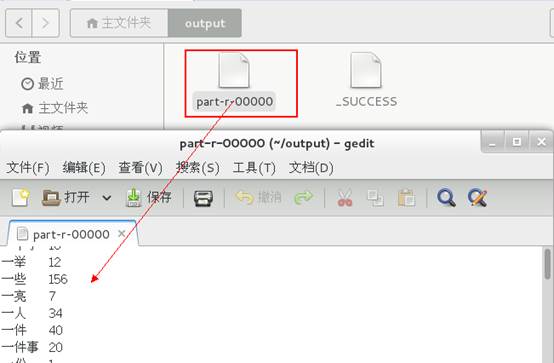
至此,中文词频统计运行成功。
7、总结
这次的中文词频统计只是一个简单的实验,还需要继续完善统计功能,比如词频数量的排序,去除单字统计等等。这方面我接触的还不深,希望有经验的朋友能给我一些学习建议和意见,谢谢。
作者:何海洋
本博客内容主要以学习、研究和分享为主,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接,否则保留追究法律责任的权利。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号