


JVM(一) -- 内存管理
最近在学习深入理解Java虚拟机这本书,所以使用博客来记录一下学习笔记。
Java的内存管理学习分为两个部分:Java内存区域和Java垃圾回收。
Java内存区域和对象访问
1.运行时数据区域
Java虚拟机所管理的内存包括如下图所示的几个运行时数据区域:

1.1 程序计数器
程序计数器是线程私有的,通过改变计数器的值来选取下一条需要执行的字节码指令。
1.2 Java 虚拟机栈
java虚拟机栈也是线程私有的,它的生命周期和线程相同。虚拟机栈描述的是Java方法
执行的内存模型:每个方法被执行的时候都会创建一个栈帧(Stack Frame)用于存储局部变量表、 操作栈、动态链接、方法出口等信息。每一个方法被调用直至执行完成的过程,就对应一个栈帧在虚拟机栈中入栈和出栈的过程。
虚拟机栈中的局部变量表存放了编译期可知的各种基本数据类型,对象引用(指针)和returnAddress类型(指向一天字节码指令的地址),局部变量表所需的内存空间在编译期间完成分配。
1.3 本地方法栈
本地方法栈与虚拟机栈发挥的作用是很相似的,区别在于虚拟机栈为虚拟机执行Java方法(也就是字节码)服务,而本地方法栈则是为虚拟机使用到的Native方法服务。
1.4 Java 堆
堆是Java虚拟机所管理的内存中最大的一块,Java堆是被所有线程共享的内存区域,在虚拟机启动时创建。此内存区域的唯一目的就是存放对象实例,几乎所有的对象实例都在这里分配内存。在Java虚拟规范中的描述是:所有的对象实例以及数组都要在堆上分配内存。
Java堆是垃圾回收器管理的主要区域,而现在收集器基本上都是采用分代收集算法【新生代和老年代,以及相应的Minor GC和Full GC】。
根据Java虚拟机规范的规定,Java堆可以处于物理上不连续的内存空间中,只要逻辑上是连续的即可,在实现时,当前主流的虚拟机都是按照可扩展来实现的(通过-Xmx和-Xms控制)。当堆无法扩展是,会跑出OutOfMemoryError异常。
1.5 方法区
方法区与Java堆一样,是各个线程共享的内存区域,它用于存储已被虚拟机加载的类信息、常量、静态变量、即时编译器(JIT)编译后的代码等数据。虽然Java虚拟机规范把方法区描述为堆的一个逻辑部分,但是它却有一个别名叫做Non-Heap,目的是与Java堆区分开。
对于HotSpot虚拟机上开发和部署程序的开发者来说,方法区会被称为“永久代(Permanent Generation)”,本质上两者并不等价,仅仅是因为HoSpot虚拟机的设计团队选择把GC分代收集扩展至方法区,或者说使用永久代来实现方法区而已。对于其他虚拟机而言,是不存在永久代的概念的。
Java虚拟机规范对这个区域的限制非常宽松,除了和Java堆一样不需要连续的内存和可以选择固定大小或者可扩展外,还可以选择不实现垃圾收集。相对而言垃圾收集行为在这个区域是比较少见的,这个区域的内存回收主要目标是针对常量池的回收和对类型的卸载,但是这个区域的垃圾回收效果很难令人满意。
1.6 运行时常量池
运行时常量池(Runtime Constant Pool)是方法区的一部分.Class文件中除了有类的版本、字段、方法、接口等描述信息外,还有一项信息是常量池(Constant Pool Table),用于存放编译期生成的各种字面量和符号引用,这部分内容将在类加载后存放到方法区的运行时常量池中【关于字节码文件,详情见随后的 类文件结构】。
运行时常量池和Class文件常量池有最显著的一个区别:Class文件常量池是在编译期产生的【字节码文件中】,是预置入Class文件的,因此不具备动态性。而运行时常量池在运行期间可以把新的常量放入池中,用的较多的是String的intern()方法。
1.7 直接内存
直接内存(Direct Memory)并不是虚拟机运行时数据区的一部分,也不是Java虚拟机规范中定义的内存区域,但是在JDK1.4中加入了NIO(New Input/Output)类,引入了一种基于通道(Channel)与缓冲区的I/O方式,它可以使用Native函数库直接分配堆外内存,然后通过一个存储在Java堆里面的DirectByteBuffer对象作为这块内存的引用进行操作,这样能在一些场景中显著提高性能,因为避免了在Java堆和Native堆中来回复制数据。
2 对象访问
最简单的对象访问也会涉及到Java栈、Java堆、方法区这三个最重要的内存区域之间的关联关系。如下:
Object obj = new Object();
假设这句代码出现在方法体(就是被{}包括的部分)中,“Object obj”这部分的语义将会反映到Java栈的本地变量表中【obj属于局部变量在栈中】,作为一个reference类型出现,存储在栈中为一个引用。而“new Object()”这部分的语义将会反映到Java堆中,形成了一块存储Object类型所有实例数据值(对象中各个实例字段【区分静态字段or类字段】的数据)的结构化内存。
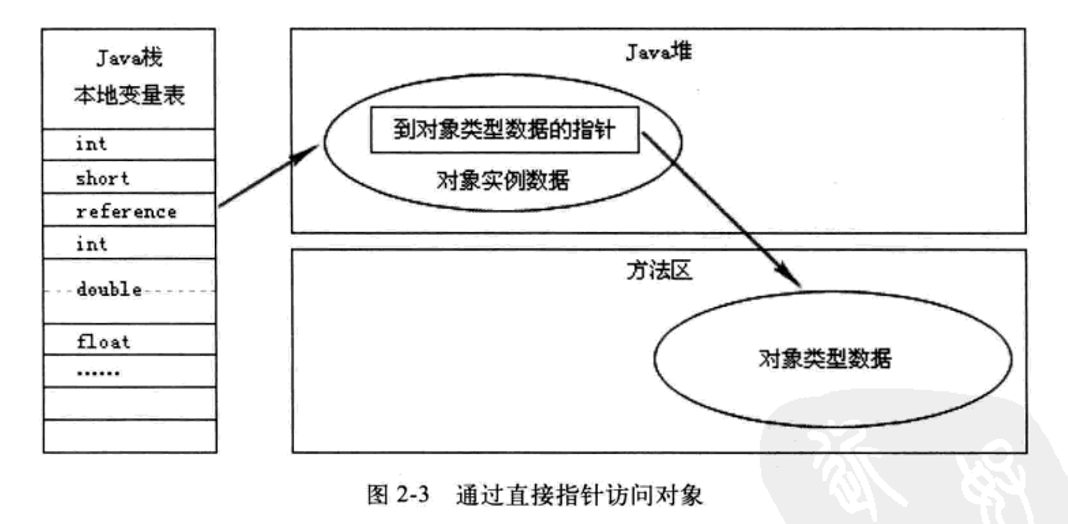
如下图,代码执行过程中,其实是先在Java堆中开辟了内存,将Object的实例数据存放在Java堆区中,并且在该结构化内存的第一个32bit的地方存放对象类型数据(可以理解为Class编译后的字节码中的固定的数据)的指针,而对象类型数据存储在Java方法区中。在堆中对象创建完成后,会将指向堆内存的首地址的指针给到Java栈中,并进栈,待该变量使用完成后出栈。
不同虚拟机实现对象访问会有所不同,主流的访问方式有两种:使用句柄和直接指针
如果使用直接指针访问方式,Java堆对象的布局中就必须考虑如何放置访问类型数据的相关信息(其实就是一个指向类型数据的指针),reference中直接存储的就是对象地址,如图2-3
如果使用句柄访问方式,Java堆中将会划分出一块内存来作为句柄池,reference中存储的就是对象的句柄地址,而句柄中包含了对象实例数据和对象类型数据各自的具体地址信息。如图2-2

对于这两种访问各自的优势,
使用句柄访问方式的最大好处是reference中存储的是稳定的句柄地址,在对象被移动(垃圾回收时会移动堆中的对象,避免频繁的内存页面切换【页面切换是硬盘和内存的之间的操作,十分消耗性能】)时,只会修改句柄中的实例数据指针,而reference本身不需要被修改。
使用直接指针访问方式的最大好处就是速度更快,它节省了一次指针定位的时间开销,由于Java中对象访问很频繁,所以直接指针访问方式会减少一定的性能消耗。而Sun HotSpot虚拟机使用的是直接指针访问。

