12、爬虫实践1:静态网页数据爬取
爬虫实践 : 静态网页爬取
目标网址:https://movie.douban.com/top250
爬取数据目标 :电影排名,电影名称,评分,评价数量

页面分析

每页显示25条数据,共计10页,一共250条数据。
检查网页源码:所需要的数据在网页源码均有
检查网页链接:
第一页:https://movie.douban.com/top250?start=0&filter=
第二页:https://movie.douban.com/top250?start=25&filter=
第三页:https://movie.douban.com/top250?start=50&filter=
...
其中不同相同的地方为: start = 数字不相同
推测由页码*25 递增规律,为了验证,点击最后一页查看
第十页:https://movie.douban.com/top250?start=225&filter=
规律 : (页码数-1)*25
推测:&filter= 省略掉也没有关系,所以省略
最终的url链接为:https://movie.douban.com/top250?start=50
似乎可以利用 params 来传递关键,形式为字典。
url再次被拆解为:https://movie.douban.com/top250 和 params= {"start":数字}
为了验证猜想是否正确,组织代码如下:
# coding:utf-8
import requests
from fake_useragent import UserAgent
from bs4 import BeautifulSoup
import pandas as pd
class Douban():
def __int__(self):
pass
def __headers(self):
ua = UserAgent()
useragent = ua.ie
headers = {
"User-Agent": useragent,
}
return headers
def send_url(self,num,url):
params = {"start": num * 25}
response = requests.get( url,params=params , headers=self.__headers() )
return response.content.decode()
# 写爬取的主要逻辑
def run(self,url):
rel = []
for i in range(10):
# 1 发送请求
response = self.send_url(i,url ) # 发送请求
# 2 处理数据
soup = BeautifulSoup(response,"html.parser")
# 2.1 先找到item
data_list = soup.find_all(class_ = "item")
for data in data_list:
dic = {}
dic["序号"] = data.em.string
dic["电影名称"] = data.img["alt"]
dic["评分"] = data.find_all(class_ = "rating_num")[0].string
dic["评价人数"] = data.find_all("span")[-2].string
dic["格言"] = data.find_all("span")[-1].string
rel.append(dic)
# 3 保存数据
# with open("豆瓣电影250.txt","w",encoding="utf-8") as f:
# f.write(str(rel))
data = pd.DataFrame(rel)
data.to_excel("豆瓣电影排名.xlsx")
if __name__ == '__main__':
url ="https://movie.douban.com/top250"
douban = Douban()
douban.run(url)
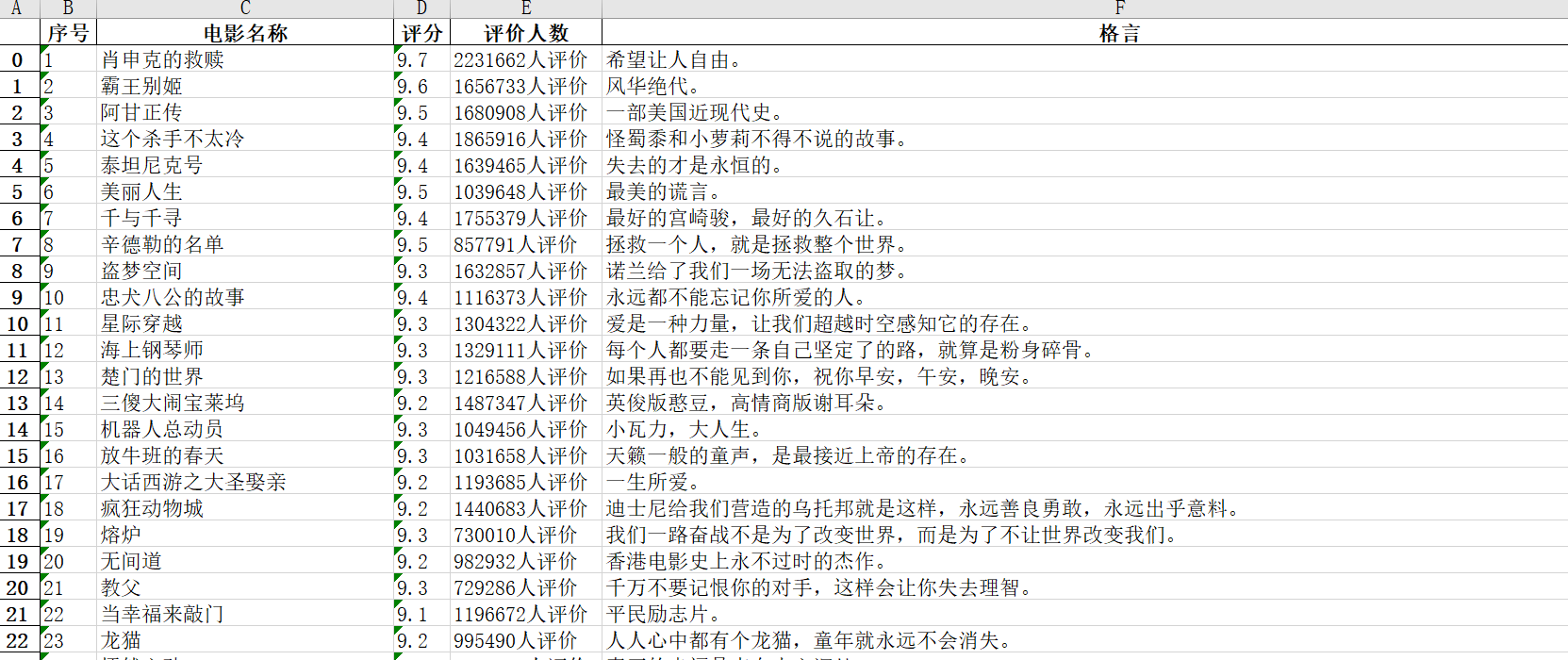
最后结果

 浙公网安备 33010602011771号
浙公网安备 33010602011771号