每日全量数据的分区表如何优化和存储
问题
当前业务数据是实时数据,用户表如下,其中用户的状态码会实时变动 1-正常用户 2-优先用户 3-锁定用户。 当然比如订单表状态 1 已下单 2已支付 3已发货 等也是类似,此处逻辑是一致的。
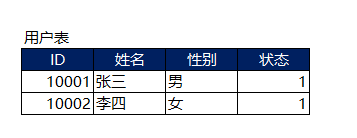
当前由于数据分析需要,将每日全量的数据存储到数据库中,采用分区的方式,分区标识是ymd。当 ymd='2020-01-01'时,则会显示当前所有的数据。
变动的情况。
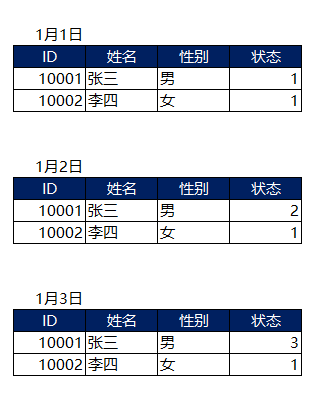
实际存储的方式。
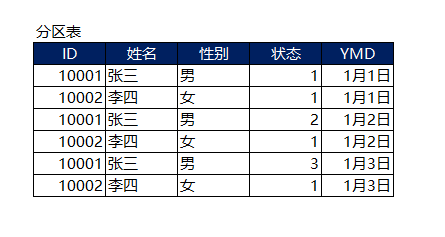
注意到有以下几个问题:
- 按列来说。变动的只有状态,姓名、性别等内容也几乎不会变动,但是每天都需要耗费大量的存储空间存储这些冗余的不变动信息。
- 按行来讲。变动的只有张三的,李四的状态几乎不会变动,但是也需要每天同步一份。而当数据库中80%的历史数据都是不变动的时候,这种存储方式将会导致存储量急剧翻倍。
解决方案
该方案是大数据之路(阿里)中的数据实践。从上述例子来讲,存储的方式变为这样。每天变化的情况如下。其中标黄的是当天新增的。
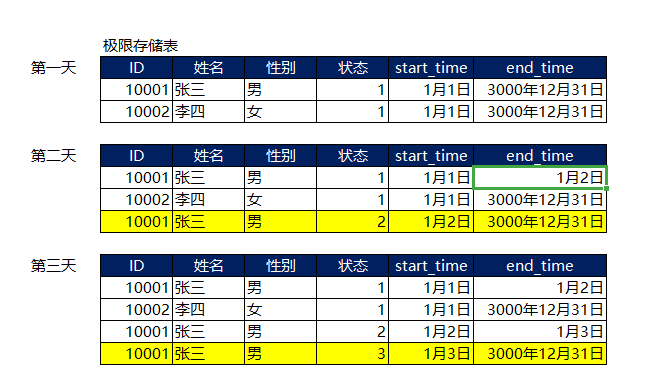
选取数据的时候的范式是:where start_time<=需求时间 and end_time>需求时间
比如想要选择1月2日数据(当天张三是2,李四是1的数据)
select *
from 极限存储表 a
where a.start_time<='1月2日' and a.end_time>'1月2日'
则会选中以下两条(未被选择的行是灰色)
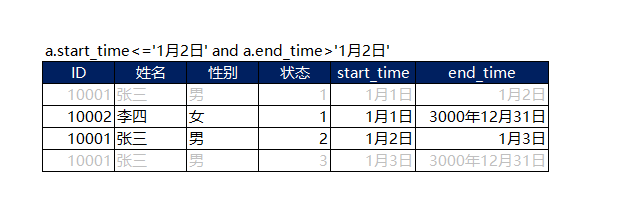
这正是我们需求的那一天的数据。
缺陷
这种极限存储的方式针对于数据基本不变动但偶尔变动的数据效果较好,对于大量历史数据不变动,最近的少量数据变动效果较好(比如历史的订单几乎不变,最近1周的订单则比较活跃)。对于需要大量变动的数据,比如游戏的金币数据,用户的积分数据等效果很差。
解决方案是:将剧烈变动的字段单独摘出来使用全局更新,而符合这种存储方式的表使用这种方式存储。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号