PySpark 安装教程 使用 Jupyter 作编辑器
Spark 的安装并不依赖于安装 Hadoop。 当在本地运行Spark的时候,Hadoop并不是必要条件,但依然在运行spark的时候会有一些错误,但你忽略即可,无伤大雅。 只有在集群上运行Spark的时候,才需要 Hadoop
环境:Windows 10
安装分为以下步骤:
- Java的安装(JDK)
- Python的安装(Anaconda)
- pyspark的安装
- Jupyter的设置
JDK 的安装
在JDK官网(OpenJDK, oraclejdk都行)下载安装包,依次点击下一步即可。此处是用的OpenJDK, 安装后将 C:\Program Files\AdoptOpenJDK\jdk-14.0.1.7-hotspot\bin 添加进系统的path。
path 的添加步骤是: 计算机->右击->属性->系统属性->高级->环境变量->系统变量->找到path
成功的标准是在 powershell 中是否可以识别 java 命令:

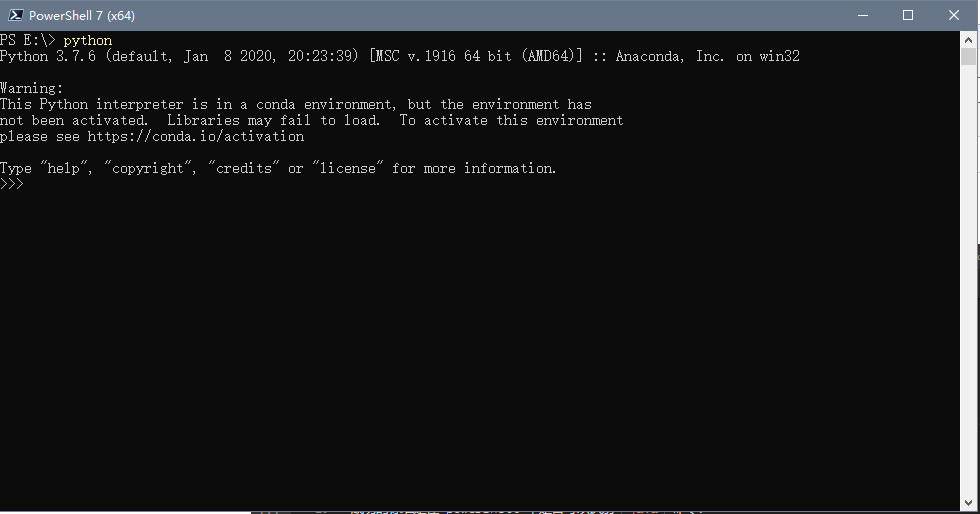
python 的安装
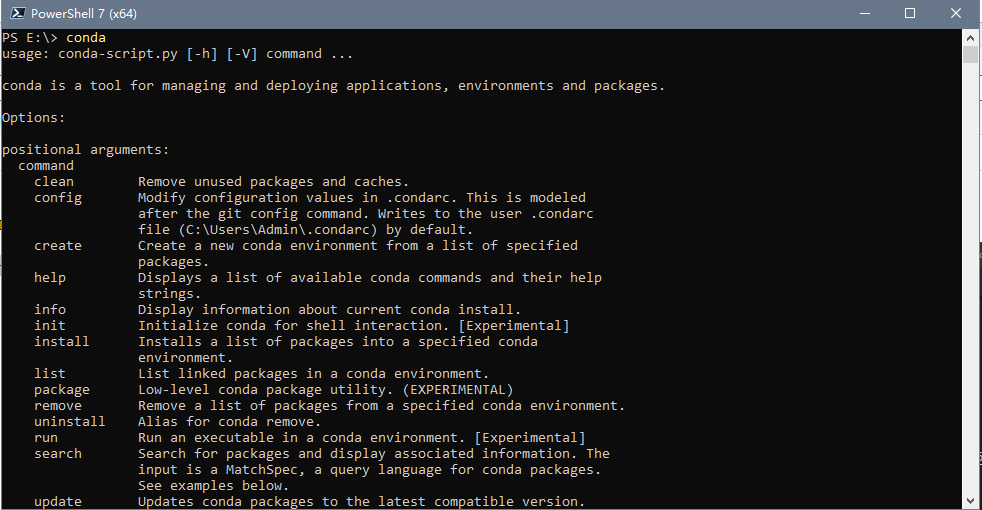
此处使用 anaconda , 在官网下载最近安装包,注意过程中将 conda 的命令添加进入 path 方便使用。
anaconda 安装成功的标志是可以识别 python 命令, conda 命令。
Spark 的安装
在 spark 官网下载安装包,名字大概是叫这个: spark-3.0.0-bin-hadoop3.2.tgz,用 7zip 解压,成为tar,再解压一次成为文件夹。我解压到了E:\spark-3.0.0-bin-hadoop3.2\,进入E:\spark-3.0.0-bin-hadoop3.2\bin 将这个路径添加上path,和上方一样的步骤。
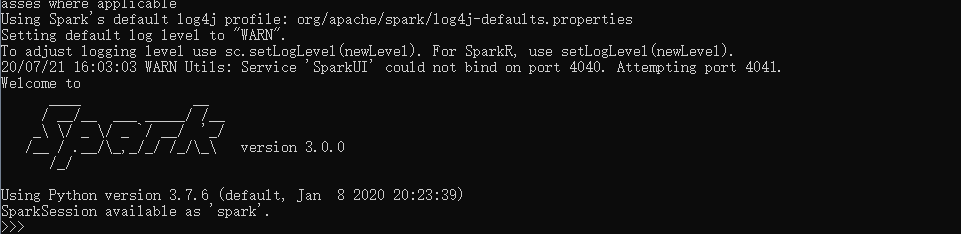
安装成功的标志是在powershell中输入 pyspark 可以识别命令。出现类型下面的图就行了,不用管上方的错误提示。
pyspark 的安装
先更改conda的源到清华的镜像,否则慢到抓狂。 见这个链接: https://www.cnblogs.com/heenhui2016/p/12375305.html
打开一个powershell, 输入 conda install pyspark, 确认输入y,等待下载与安装。
评价是否安装成功的标准是输出以下命令没有报错:
import pyspark
jupyter 的设置
- 添加
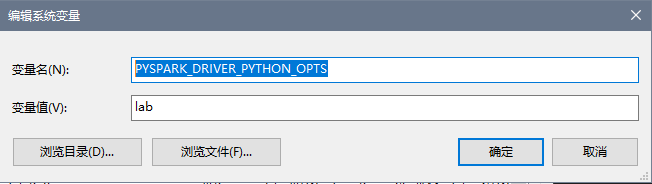
PYSPARK_DRIVER_PYTHON=jupyter到系统变量 - 添加
PYSPARK_DRIVER_PYTHON_OPTS=lab到系统变量
注意,我是用
jupyter lab做编辑器,而不是jupyter notebook,若是以notebook作编辑器,将PYSPARK_DRIVER_PYTHON_OPTS=notebook添加到系统变量即可。
成功的标志是运行以下代码没有出毛病:
from pyspark import SparkContext
sc = SparkContext("local", "Hello World App")
查看版本和相关信息
如图中有个 sparkUI 的链接,点进去可查看Spark的运行情况等。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号