如何正确理解SQL关联子查询
一、基本逻辑
对于外部查询返回的每一行数据,内部查询都要执行一次。在关联子查询中是信息流是双向的。外部查询的每行数据传递一个值给子查询,然后子查询为每一行数据执行一次并返回它的记录。然后,外部查询根据返回的记录做出决策。
反正我是没看懂,下面详细解释SQL中关联子查询的逻辑。
二、举例
员工表的主要信息:
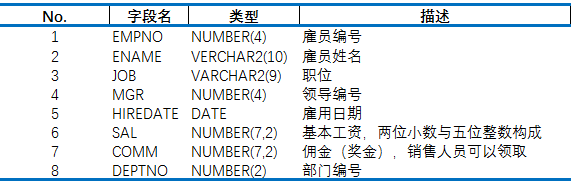
要解决的问题:检索工资大于同职位的平均工资的员工信息。
2.1 直觉的做法
员工多,而相应的职位(如销售员、经理、部门经理等)少,因此首先想到的思路是对职位分组,这样就能分别得到各个职位的平均工资,再比较每个人的工资和他对应职位的平均工资,大于则被筛选出来。
首先得到各个职位的平均工资
代码如下:
1 select job,avg(sal) from emp 2 group by job;
结果如下:
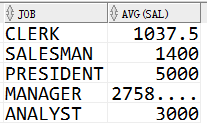
然后利用子查询,对他们进行对比(幻想)
代码如下:
1 select * from emp where sal > 2 (select avg(sal) from emp 3 group by job);
但是子表查询结果是5行,因此这段代码根本无法执行。
2.2 正确的做法
正确的做法是使用关联子查询。代码如下。
1 select * from emp e where sal > 2 (select avg(sal) from emp where job = e.job);
执行逻辑是这样
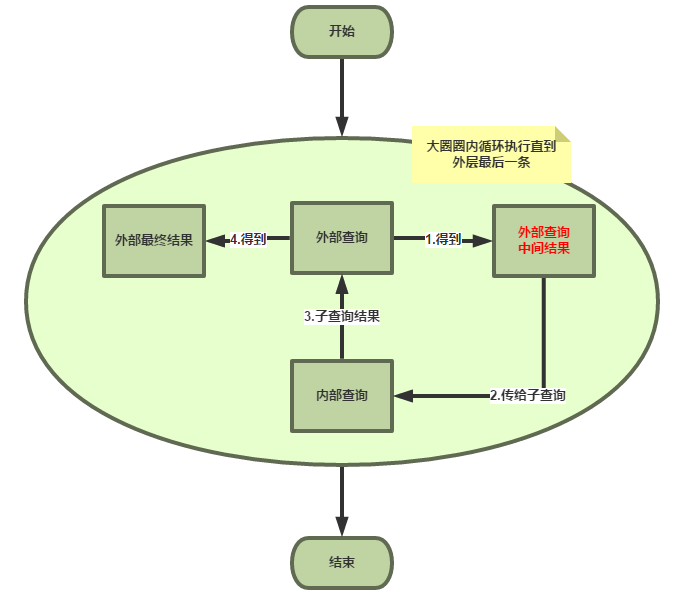
第一步
先执行外层查询,即先执行:
1 select * from emp e;
结果是:
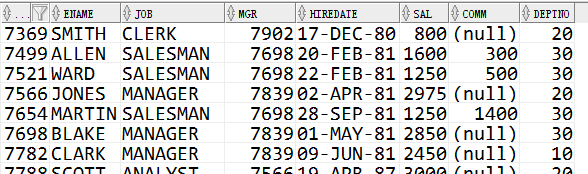
也就是该表的所有内容。又因为子查询中连接了这个表本身(where job = e.job ),所以将第一条记录转到子查询。

第二步
这条进入子查询后,子查询job是CLERK,所以先筛选出所有Job=‘CLERK’的,再对他们取平均。
相当于执行了:
1 select avg(sal) from emp where job='CLERK';
结果是
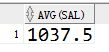
第三步
这个结果进入外层查询where和SMITH这个人的sal进行对比,相当于执行了
select * from emp where sal>1037.5 and job='CLERK';
结果是为:

循环
然后就抽出第一次外层查询的第二条(ALLEN):
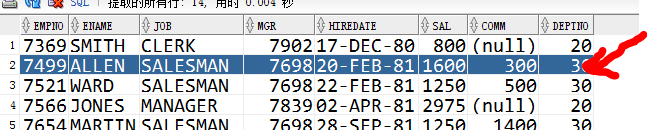
继续如上第一、二、三部。
重复计算吗?
每条记录都执行,第二行的ALLEN和第三行的WARD都是SALESMAN(销售人员),那么他们在子查询中会重复计算一次平均工资进行比较。这样会不会设计重复计算?答案是不会,效率并没有降低,SQL已经对此进行过优化。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号