那些年我们排过的序之希尔排序
基本思想
先取一个小于n的整数d1作为第一个增量,把文件的全部记录分成d1个组。所有距离为d1的倍数的记录放在同一个组中。先在各组内进行直接插入排序;然后,取第二个增量d2<d1重复上述的分组和排序,直至所取的增量dt=1(dt<dt-l<…<d2<d1),即所有记录放在同一组中进行直接插入排序为止。
该方法实质上是一种分组插入方法引
比较相隔较远距离(称为增量)的数,使得数移动时能跨过多个元素,则进行一次比[1]较就可能消除多个元素交换。D.L.shell于1959年在以他名字命名的排序算法中实现了这一思想。算法先将要排序的一组数按某个增量d分成若干组,每组中记录的下标相差d.对每组中全部元素进行排序,然后再用一个较小的增量对它进行,在每组中再进行排序。当增量减到1时,整个要排序的数被分成一组,排序完成。
一般的初次取序列的一半为增量,以后每次减半,直到增量为1。
排序过程
假设待排序文件有10个记录,其关键字分别是:
四九,三八,六五,九七,七六,一三,二七,四九,五五,零四。
增量序列的取值依次为:
缩小增量
希尔排序属于插入类排序,是将整个无序列分割成若干小的子序列分别进行插入排序。
排序过程:先取一个正整数d1<n,把所有序号相隔d1的数组元素放一组,组内进行直接插入排序;然后取d2<d1,重复上述分组和排序操作;直至di=1,即所有记录放进一个组中排序为止。
零四 一三 二七 三八 四九 四九 五五 六五 七六 九七
Shell排序
Shell排序的算法实现:
1. 不设监视哨的算法描述
void ShellPass(SeqList R,int d)
{//希尔排序中的一趟排序,d为当前增量
for(i=d+1;i<=n;i++) //将R[d+1..n]分别插入各组当前的有序区
if(R[ i ].key<R[i-d].key){
R[0]=R[i];j=i-d; //R[0]只是暂存单元,不是哨兵
do {//查找R的插入位置
R[j+d]=R[j]; //后移记录
j=j-d; //查找前一记录
}while(j>0&&R[0].key<R[j].key);
R[j+d]=R[0]; //插入R到正确的位置上
} //endif
优劣
不需要大量的辅助空间,和归并排序一样容易实现。希尔排序是基于插入排序的一种算法, 在此算法基础之上增加了一个新的特性,提高了效率。希尔排序的时间复杂度与增量序列的选取有关,例如希尔增量时间复杂度为O(n²),而Hibbard增量的希尔排序的时间复杂度为O(N(3/2)),但是现今仍然没有人能找出希尔排序的精确下界。希尔排序没有快速排序算法快 O(N*(logN)),因此中等大小规模表现良好,对规模非常大的数据排序不是最优选择。但是比O(N^2)复杂度的算法快得多。并且希尔排序非常容易实现,算法代码短而简单。 此外,希尔算法在最坏的情况下和平均情况下执行效率相差不是很多,与此同时快速排序在最坏的情况下执行的效率会非常差。专家们提倡,几乎任何排序工作在开始时都可以用希尔排序,若在实际使用中证明它不够快,再改成快速排序这样更高级的排序算法. 本质上讲,希尔排序算法的一种改进,减少了其复制的次数,速度要快很多。 原因是,当N值很大时数据项每一趟排序需要的个数很少,但数据项的距离很长。当N值减小时每一趟需要和动的数据增多,此时已经接近于它们排序后的最终位置。 正是这两种情况的结合才使希尔排序效率比插入排序高很多。
时间性能
1.增量序列的选择
好的增量序列的共同特征:
① 最后一个增量必须为1;
② 应该尽量避免序列中的值(尤其是相邻的值)互为倍数的情况。
有人通过大量的实验,给出了较好的结果:当n较大时,比较和移动的次数约在nl.25到1.6n1.25之间。
2.Shell排序的时间性能优于直接插入排序
希尔排序的时间性能优于直接插入排序的原因:
①当文件初态基本有序时直接插入排序所需的比较和移动次数均较少。
②当n值较小时,n和n2的差别也较小,即直接插入排序的最好时间复杂度O(n)和最坏时间复杂度0(n2)差别不大。
③在希尔排序开始时增量较大,分组较多,每组的记录数目少,故各组内直接插入较快,后来增量di逐渐缩小,分组数逐渐减少,而各组的记录数目逐渐增多,但由于已经按di-1作为距离排过序,使文件较接近于有序状态,所以新的一趟排序过程也较快。
因此,希尔排序在效率上较直接插入排序有较大的改进。
希尔排序是按照不同步长对元素进行插入排序,当刚开始元素很无序的时候,步长最大,所以插入排序的元素个数很少,速度很快;当元素基本有序了,步长很小,插入排序对于有序的序列效率很高。所以,希尔排序的时间复杂度会比o(n^2)好一些。由于多次插入排序,我们知道一次插入排序是稳定的,不会改变相同元素的相对顺序,但在不同的插入排序过程中,相同的元素可能在各自的插入排序中移动,最后其稳定性就会被打乱,所以shell排序是不稳定的。
举例阐述:
例如,假设有这样一组数[ 13 14 94 33 82 25 59 94 65 23 45 27 73 25 39 10 ],如果我们以步长为5开始进行排序,我们可以通过将这列表放在有5列的表中来更好地描述算法,这样他们就应该看起来是这样:
13 14 94 33 82 25 59 94 65 23 45 27 73 25 39 10
然后我们对每列进行排序:
10 14 73 25 23 13 27 94 33 39 25 59 94 65 82 45
将上述四行数字,依序接在一起时我们得到:[ 10 14 73 25 23 13 27 94 33 39 25 59 94 65 82 45 ].这时10已经移至正确位置了,然后再以3为步长进行排序:
10 14 73 25 23 13 27 94 33 39 25 59 94 65 82 45
排序之后变为:
10 14 13 25 23 33 27 25 59 39 65 73 45 94 82 94
最后以1步长进行排序(此时就是简单的插入排序了)。
图示:
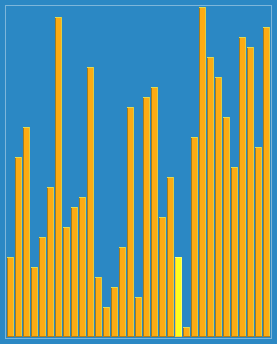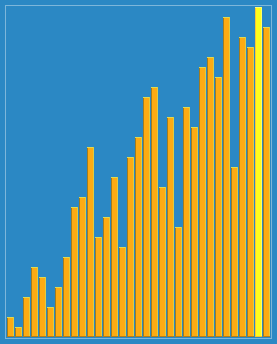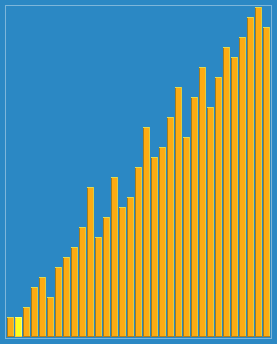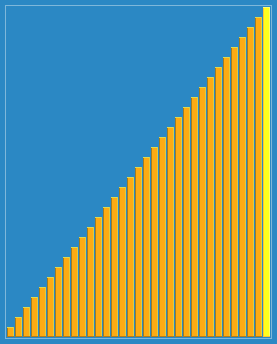
C++代码实现:

#include <stdio.h>
void shellsort(int *data, size_t size);
int i, j, temp;
int gap = 0;
int main()
{
const int n = 5;
int a[] = {5, 4, 3, 2, 1};
shellsort(a,5);
/* while (gap<=n)
{
gap = gap * 3 + 1;
}
while (gap > 0)
{
for ( i = gap; i < n; i++ )
{
j = i - gap;
temp = a[i];
while (( j >= 0 ) && ( a[j] > temp ))
{
a[j + gap] = a[j];
j = j - gap;
}
a[j + gap] = temp;
}
gap = ( gap - 1 ) / 3;
} */
for(i=0;i<5;i++)
printf("%d\n",a[i]);
}
void shellsort(int *data, size_t size)
{
int key;
int j = 0;
for (gap = size / 2; gap > 0; gap /= 2)
for ( i = gap; i < size; ++i)
{
key = data[i];
for( j = i -gap; j >= 0 && data[j] > key; j -=gap)
{
data[j+gap] = data[j];
}
data[j+gap] = key;
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号