[笔记]CTF逆向入门教程
CTF Reverse——从入门到入土
(入门教程第一部分)
本教程适用于完全刚刚入门CTF的同学,路过的有经验的大佬轻喷orz
-
Reverse 简介
逆向工程(Reverse Engineering),又称反向工程,是一种技术过程,即对一项目标产品进行逆向分析及研究,从而演绎并得出该产品的处理流程、组织结构、功能性能规格等设计要素,以制作出功能相近,但又不完全一样的产品。逆向工程源于商业及军事领域中的硬件分析。其主要目的是,在无法轻易获得必要的生产信息下,直接从成品的分析,推导产品的设计原理。
逆向工程可能会被误认为是对知识产权的严重侵害,但是在实际应用上,反而可能会保护知识产权所有者。例如在集成电路领域,如果怀疑某公司侵犯知识产权,可以用逆向工程技术来查找证据。
(引自Wikipedia:逆向工程条目) -
对CTF 逆向工程的基本介绍
-
形式
CTF竞赛中,reverse的题目囊括广泛,一切可执行代码均可以用于进行隐藏flag并要求进行逆向。常见的有:
a. Win32程序,包括32位、64位应用程序,特征为PE格式
b. Linux程序,特征为ELF文件
c. Android程序,特征为Apk安装包
d. MacOS程序
e. 工程代码源文件,例如.c文件、.py文件、.class文件。
f. 可执行代码片段,包括已编译但是无法正确运行的代码片段、未编译或中途编译文件等
值得一提的是,Linux、Android、MacOS可执行文件都基于Linux内核,因而在分析时具有较为相似的特征和语法结构。
上面列出的“程序”并不一定可以执行,某些情况下因为系统差异、运行时库缺失、架构不符等原因,这些可执行程序并不一定能够执行。 -
语言要求
对于逆向工程,由于编译后的应用程序多由字节码写成,因此从字节码回编译到可读文本时不能完全恢复工程源代码文件,因此需要掌握多门技术语言。
a. 汇编语言
汇编语言(assembly language)是任何一种用于电子计算机、微处理器、微控制器,或其他可编程器件的低级语言。
在不同的设备中,汇编语言对应着不同的机器语言指令集。
一种汇编语言专用于某种计算机系统结构。
x86/amd64汇编指令的两大风格分别是Intel汇编与AT&T汇编,分别被Microsoft Windows/Visual C++与GNU/Gas采用(Gas也可使用Intel汇编风格)
关于两种汇编风格的区别,可以访问汇编语言的Wikipedia介绍 获取相关信息
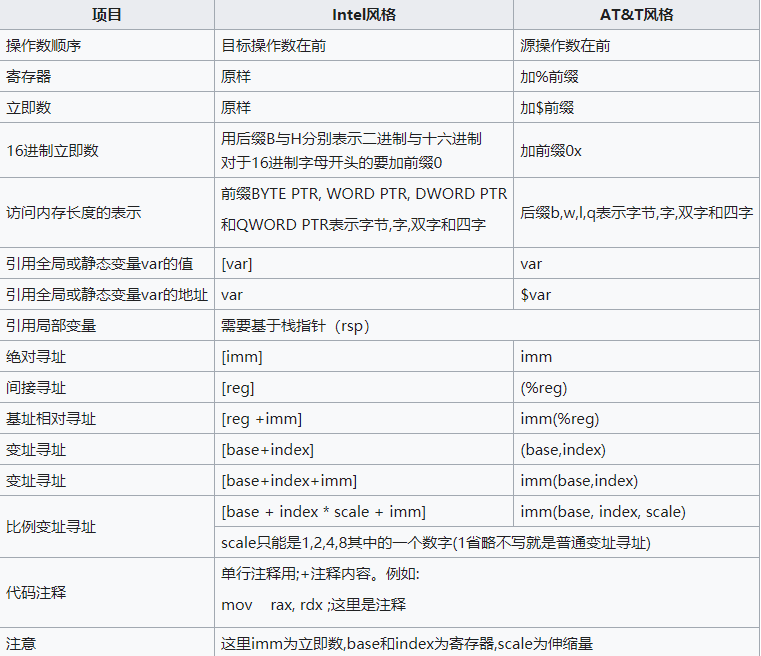
并不需要完全学习所有汇编指令和所有汇编语言,从一种汇编语言风格可以很方便的类推另一种风格,只需要注意其区别
b. C语言
作为一种高效的一种高级语言,C语言是大多数底层API实现的基本语言。另外,在IDA中反汇编生成的pseudocode也是C语言风格,熟悉C语言可以对逆向生成的一些结果有很好的快速察觉。
c. Python
Python是一种方便的、易于学习的高级语言,在解密、爆破中经常使用Python进行脚本编程。由于大部分问题的答案求解并不复杂,因此对代码执行的效率要求并不高,使用Python作为求解器是可能的
另一方面,Python丰富的包为大多数求解器的开发提供了大量的便利。
-
-
技术和流程
-
逆向基本流程
这里主要讲三种文件:PE/ELF/APK文件的逆向分析,介绍多种应用程序的使用
-
文件分析
文件根据其首字节的不同,区分不同格式。这些格式也同时被刻意的表达在拓展名之上。一般而言按照下面的顺序确认文件的格式:
a. 根据拓展名确认
b. 使用头字节识别(利用命令file或其他识别程序)
c. 对于加密、混淆的文件需要去混淆和解密之后再进行a,b
关于识别的file指令见接下来的“技术”节 -
查询程序的目标操作系统位数以及壳(对于PE/ELF文件而言)
这里使用exeinfope进行查询,也可以使用PEid进行查询。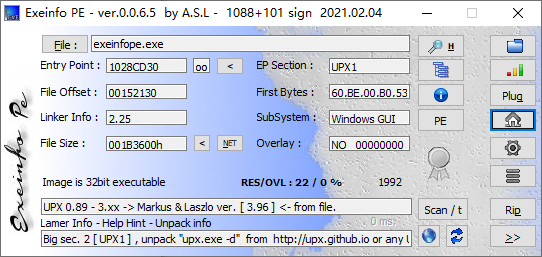
exeinfope:图中“UPX 0.89 - 3.xx”代表了程序加壳是UPX壳,需要用对应的解压软件反混淆。而“Image is 32bit executable”代表程序是32位应用程序。
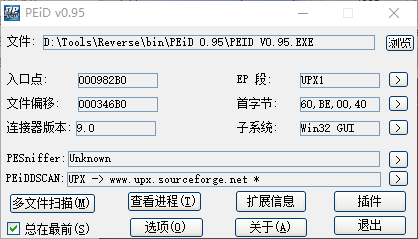
PEiD:图中"PESniffer"栏对编译器进行嗅探,"PEiDDSCAN"对壳进行嗅探。上面的子系统”Win32,GUI“告诉我们这是一个具有32位Windows图形界面的应用程序。
-
分析APK包(对于APK包而言)
APK包的分析较PE/ELF文件的分析要复杂一些。首先APK包事实上就是一个zip文件。其中含有代码、资源文件。
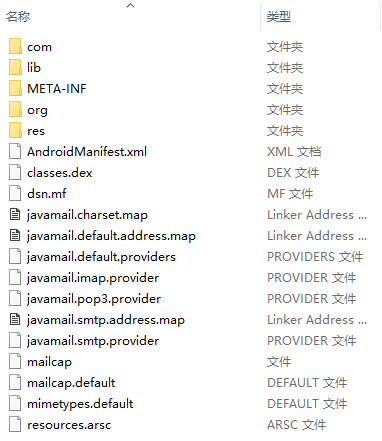
一个示例apk解压的文件体系
其中一定存在
-
AndroidManifest.xml
该文件是每个应用都必须定义和包含的,它描述了应用的名字、版本、权限、引用的库文件等等信息,如要把apk上传到Google Market上,也要对这个xml做一些配置。在apk中的AndroidManifest.xml是经过压缩的,可以通过AXMLPrinter2工具解开,具体命令为:
java -jar AXMLPrinter2.jar AndroidManifest.xml -
META-INF目录
META-INF目录下存放的是签名信息,用来保证apk包的完整性和系统的安全。在eclipse编译生成一个apk包时,会对所有要打包的文件做一个校验计算,并把计算结果放在META-INF目录下。这就保证了apk包里的文件不能被随意替换。比如拿到一个apk包后,如果想要替换里面的一幅图片, 一段代码, 或一段版权信息,想直接解压缩、替换再重新打包,基本是不可能的。如此一来就给病毒感染和恶意修改增加了难度,有助于保护系统的安全。 -
res目录
res目录存放资源文件。包括图片,字符串等等。 -
lib目录
lib目录下的子目录armeabi存放的是一些so文件。eclipse在打包的时候会根据文件名的命名规则(lib****.so)去打包so文件,开头和结尾必须分别为“lib”和“.so”,否则是不会打包到apk文件中的。
-
assets目录
assets目录可以存放一些配置文件,这些文件的内容在程序运行过程中可以通过相关的API获得。具体的方法可以参考SDK中的例子:
在sdk的
\SDK\1.6\android-sdk-windows-1.6_r1\platforms\android-1.6\samples\ApiDemos例子中,有个com.example..android.apis.content的例子,在这个例子中他把一个text文件放到工程的asset目录下,然后把这个txt当作普通文件处理。处理的过程在ReadAsset.java中。同理,asset也可以放置其他文件。 -
classes.dex文件
classes.dex是java源码编译后生成的java字节码文件(首先是java文件通过jdk编译成字节码文件然后经过dex编译成classes.dex)。但由于Android使用的dalvik虚拟机与标准的java虚拟机是不兼容 的,dex文件与class文件相比,不论是文件结构还是opcode都不一样。目前常见的java反编译工具都不能处理dex文件。Android模拟 器中提供了一个dex文件的反编译工具,dexdump。用法为首先启动Android模拟器,把要查看的dex文件用adb push上传的模拟器中,然后通过adb shell登录,找到要查看的dex文件,执行dexdump xxx.dex。另,有人介绍到Dedexer是目前在网上能找到的唯一一个反编译dex文件的开源工具,需要自己编译源代码。 -
resources.arsc
编译后的二进制资源文件的索引(apk文件的资源表/索引)
所以我们主要就要分析其中的classes.dex文件。有些时候该文件可能不止一个,我们都要进行分析。
-
-
反编译对象文件获取基本代码
-
对于PE/ELF/Android文件都适用于将文件直接拖入IDA(Interactive Disassembler Professional)中进行分析。这样的不执行代码进行反汇编的过程叫做静态分析。而对于WinPE文件可以使用OD(OllyDebug)进行动态调试。
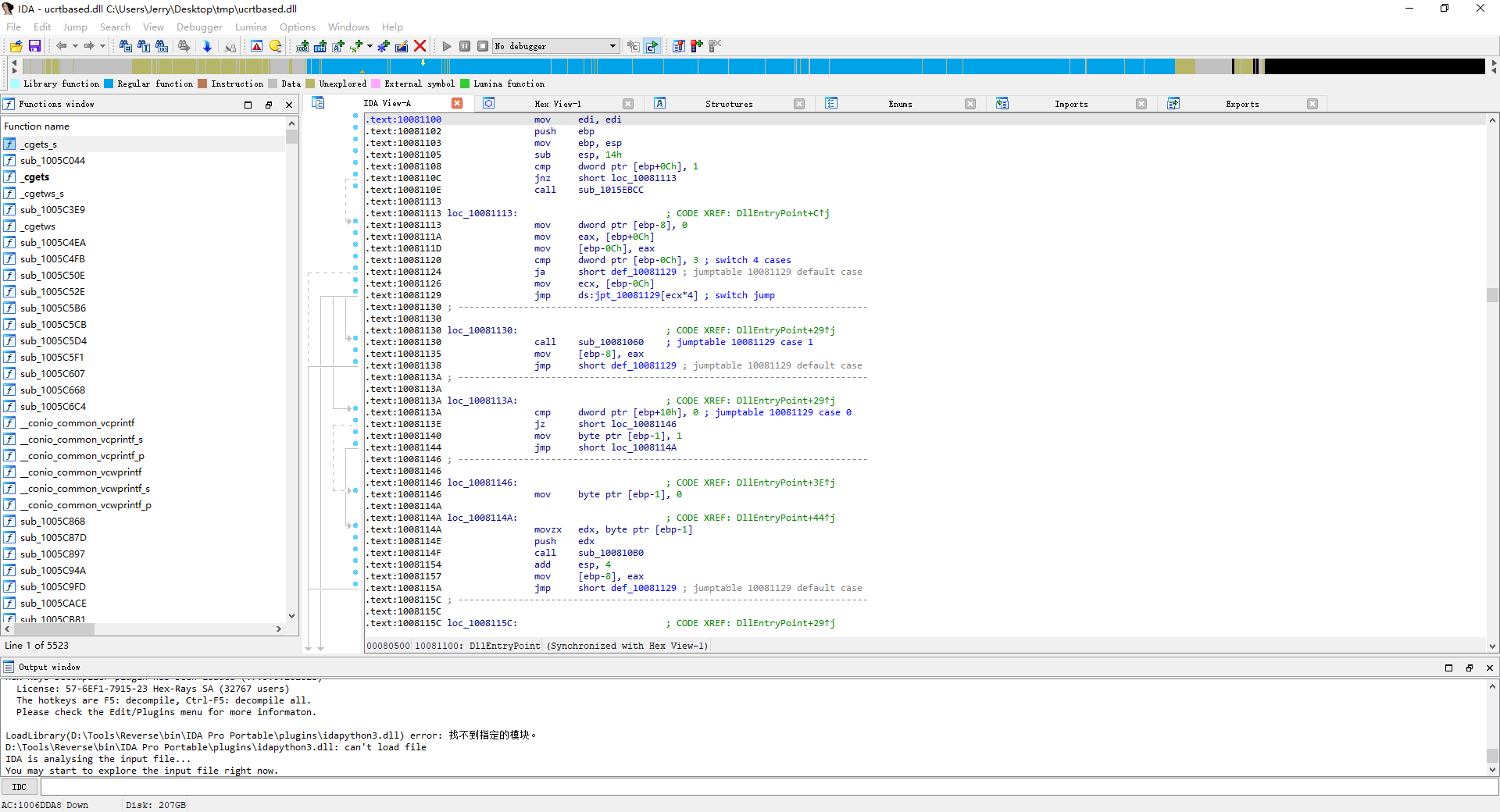
一个经典的IDA32界面,其中包含了函数列表、反汇编窗口等消息。此处分析的是一个Windows文件(ucrtbased.dll)
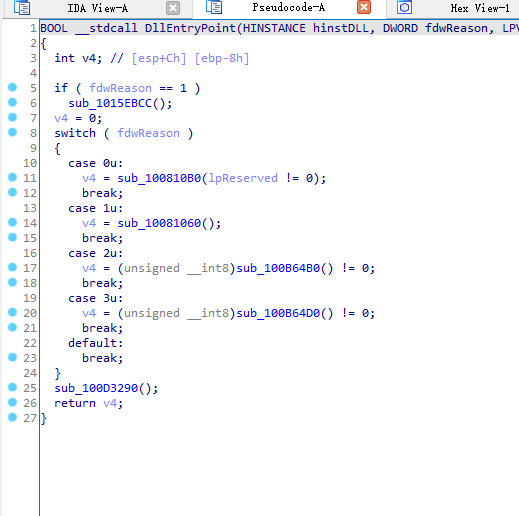
IDA的伪代码(Pseudocode)功能,可以很方便的将一些显而易见的逻辑翻译为C语言代码,便于分析。然而其语法不一定严格遵照C语言,例如其中可能有未声明的变量,有奇怪的类型(
_BYTE)等。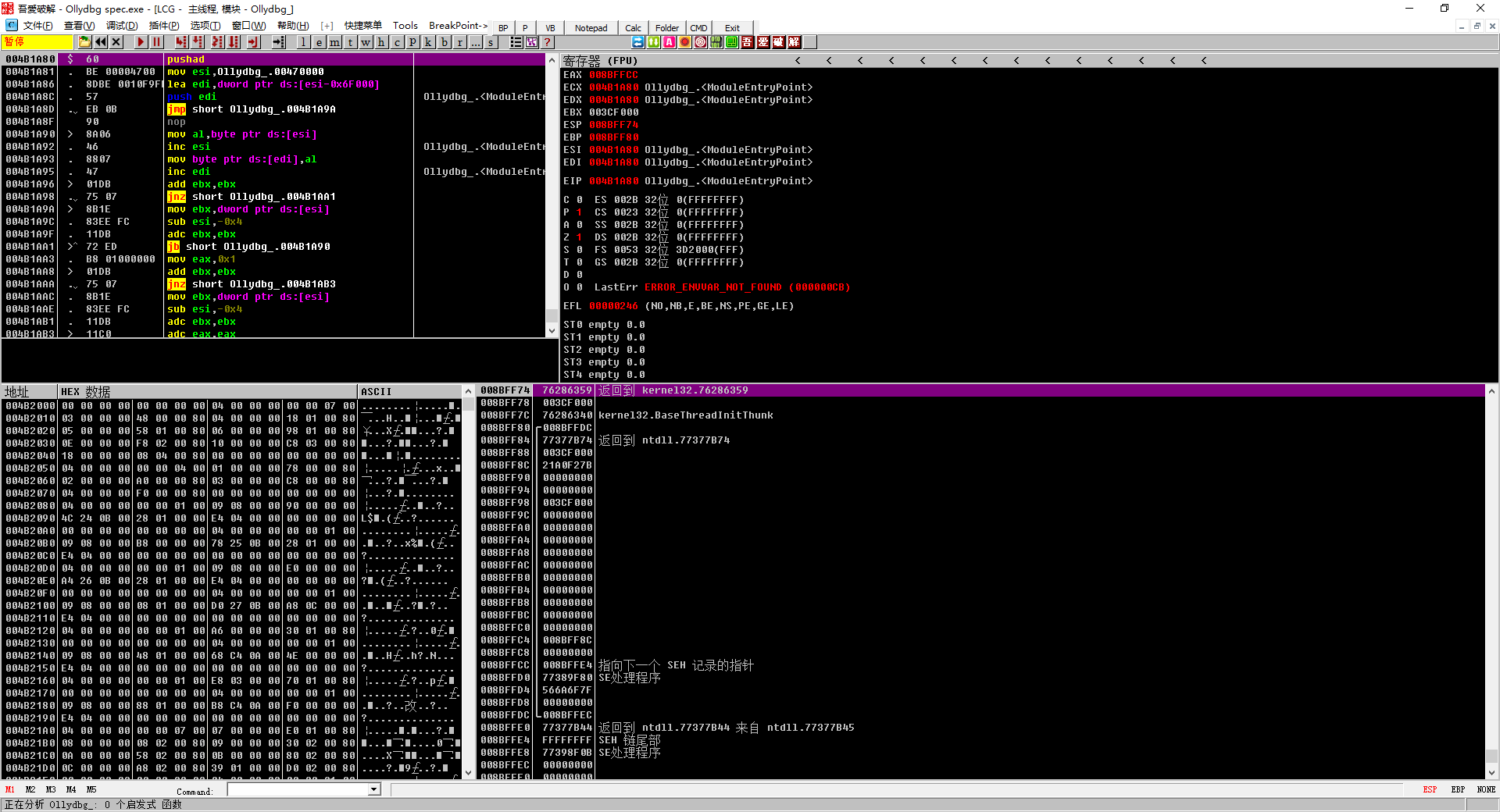
Ollydbg界面,此处分析的是他自己(Ollydbg spec.exe)
-
对于Android文件,也可以使用其他更为方便的工具进行分析,例如jeb、APKIDE等
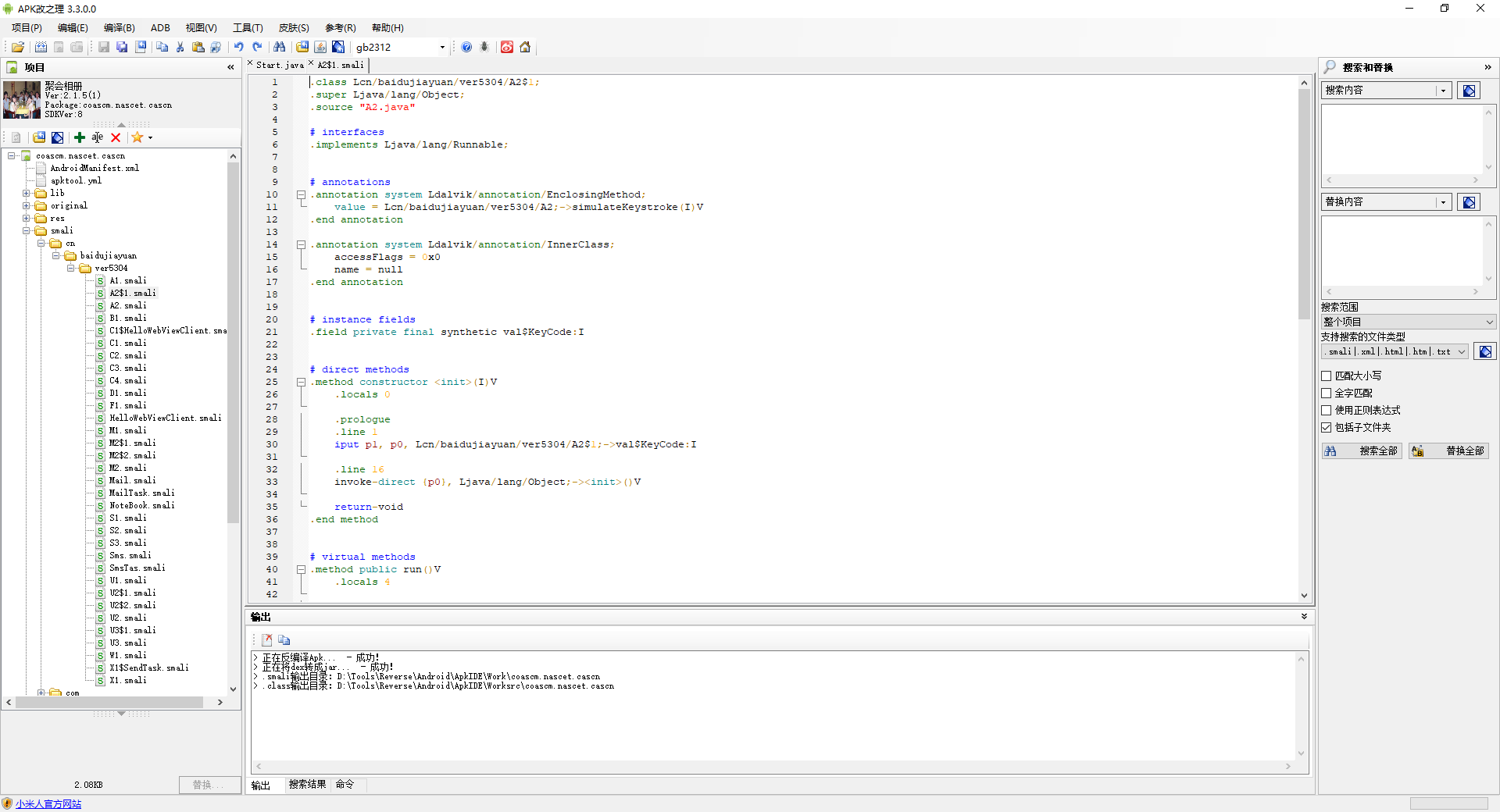
APKIDE界面,包括了反编译生成的smali文件窗口、资源窗口等
-
-
分析基本代码解其中的flag
-
-
技术详解
-
前言
至此为止,你已经学习了基本的reverse流程和如何对样本进行分析的基本流程。这意味着可以从现在开始对各类基本样本进行分析了。下面将给出一些常见的/不常见的技术的说明和解决方法。
-
字符串分析技术
由于CTF的reverse赛题的答案提交形式为flag{xxx}(字段flag可能有所更改),故而大部分题目所做的工作就是花式隐藏这个字符串。我们要寻找的便是这样的字符串:%name%{%code%}。其中标志为符号{}。要寻找这样的字符串,首先需要介绍变量存储在内存中不同的形式-
全局变量
全局变量被声明在所有函数、过程的外面,是一个固定化的字符串。因而全局变量保存在内存的全局存储区中,占用静态的存储单元#include <stdio.h> char flag[] = {'f','l','a','g','{','e','x','a','m','p','l','e','}','\0'}; int main() { printf("%s",flag); return 0; }上面给出了一个最简单的全局变量表达式,这样的可执行程序在IDA32中分析的界面如下:
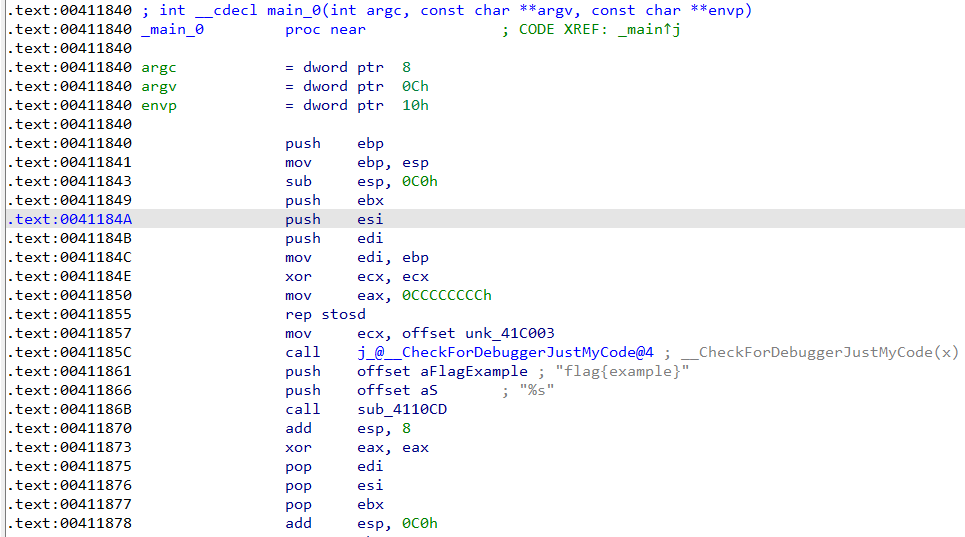
其中第
.text:00411861(此处的.text代表某个节,后面代表地址)行显示此时push offset aFlagExample,示意将aFlagExample压入栈中。此处的aFlagExample为:(IDA对反编译识别的字符串都试图进行命名,并冠以字母a)
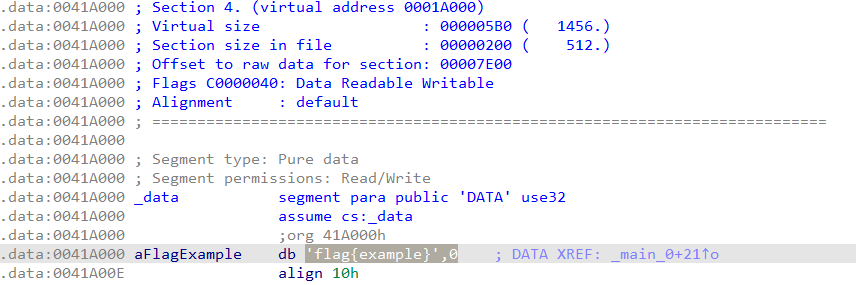
其中在数据节可以看到已经声明的数据
flag{example},这就是存储在全局变量中的字符串。这样的字符串可以很方便的找到,打开字符串子页面
在其中可以很快找到这样的字符串
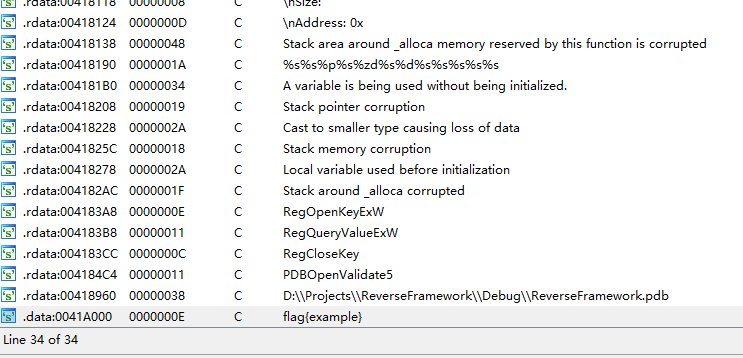
此处可以按下
CTRL+F键呼出“查找”,输入大括号再进行筛选就可以找到字符串
由于这种加密方式过于简单,所以这样的题目基本都在签到题
-
局部变量
局部变量被声明在函数、过程内部,因而只有在调用函数、引用过程时生成。局部变量保存在栈中,只有在所在函数被调用时才动态地为变量分配存储单元。#include <stdio.h> char flag[8] = {0}; int main() { flag[0] = 'f'; flag[1] = 'l'; flag[2] = 'a'; flag[3] = 'g'; flag[4] = '{'; flag[5] = 'p'; flag[6] = 'i'; flag[7] = '}'; printf("%s", flag); return 0; }对于上面这段程序,由于flag只在外面声明了一个框架,他的赋值是在函数内进行的,因此不能在string子窗口或者
.data节找到端倪。
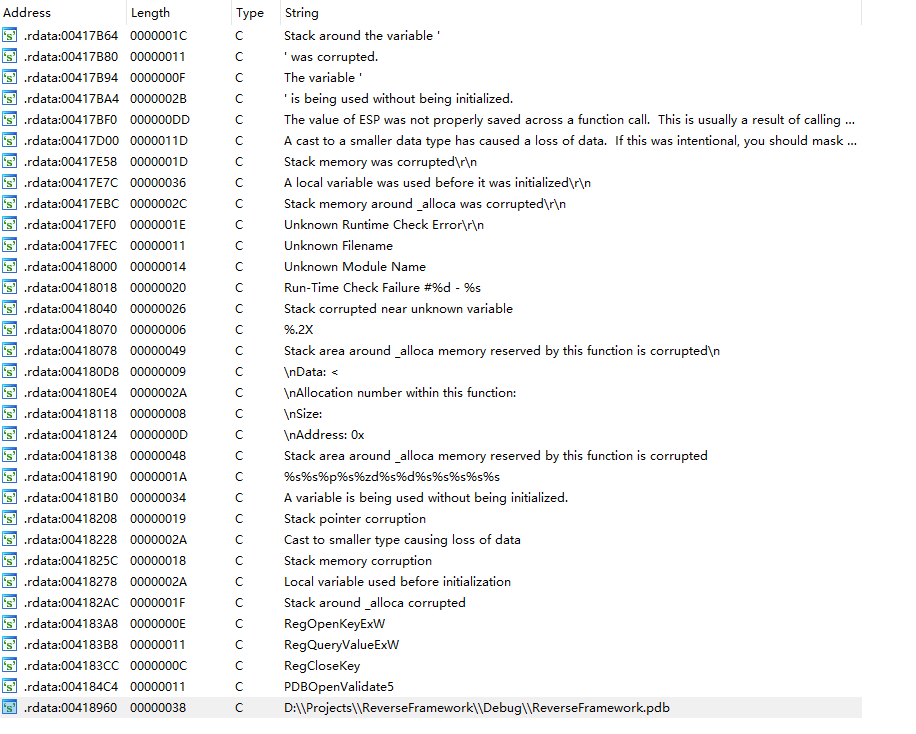
因而我们打开ida的反汇编界面
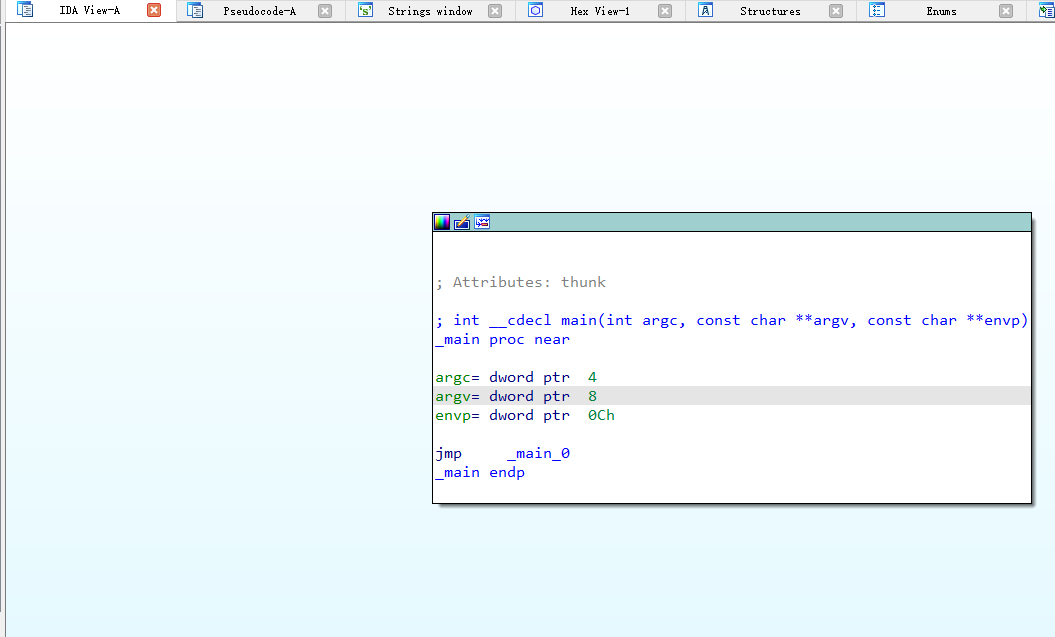
其中的指令
jmp _main_0指示了代码的跳转。在IDA中双击这个跳转中的参数_main_0,IDA便自动定位到其函数位置并展示了如下的代码: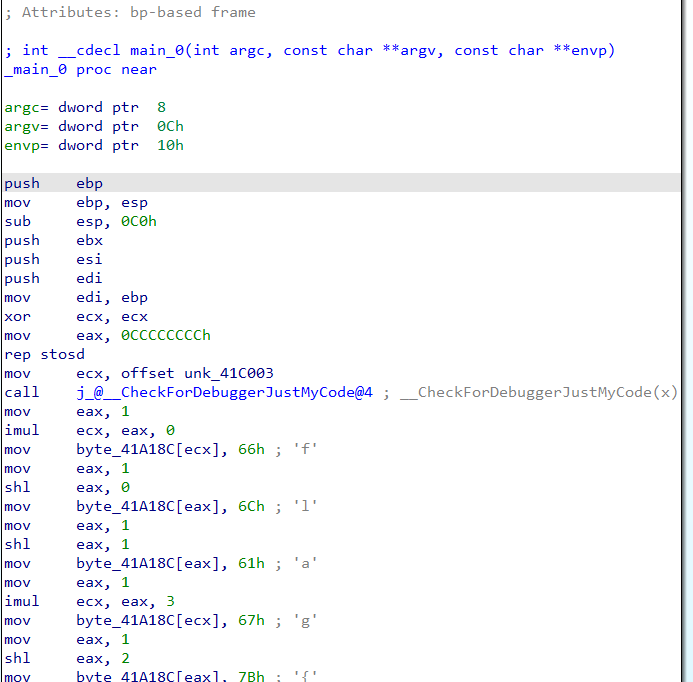
这是一段汇编指令。要简化汇编的分析,可以按下
F5快捷键打开伪代码(pseudocode)窗口
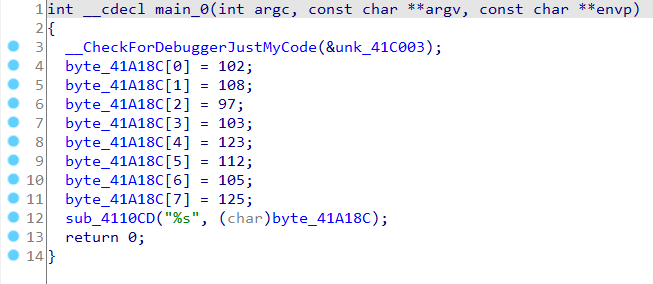
可以看到这段程序被方便的转换为了以C语言为主要格式的伪代码。
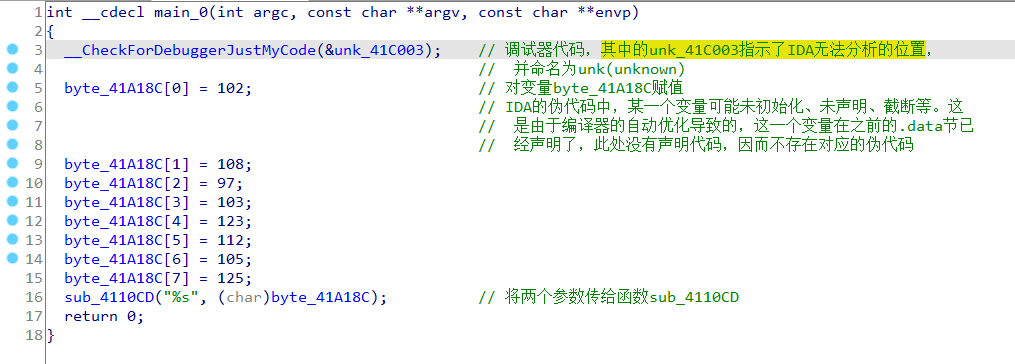
一个小技巧是:IDA中在伪代码中使用
/键可以进行注释,而反汇编窗口则使用;进行注释。使用N键可以将变量、函数重命名。上面给出了一个函数,
sub_4110CD,这是标准输入输出中的printf函数。感兴趣的读者可以自行定位到其实现看看IDA是如何反汇编系统函数的。同时要提到的技巧就是,十分逆向三分猜。对于逆向的程序,由于其复杂庞大不可能完全搞清楚,在已经确认是有效的、真实的代码结构之后,可以宏观上先猜测某个函数、结构、代码片段的功能,在根据上下文反推函数的功能,并不需要完全定位到函数的底层实现。上面我们看到函数
sub_4110CD接受了一个很眼熟的参数"%s",这是printf函数接受的参数format中的一种,因此可以断定这就是printf函数或者其衍生版本。
-
-
字符串加密、混淆技术
- 简单异或加密
上面讲的都太简单,毕竟字符串直接写在了程序之内。下面我们介绍题目中的基本程序过程:验证反推
对于大部分reverse题目,他们都接受一个用户输入并进行比对。如果此输入和程序内定义的flag相同则输出正确输出,否则就提示输入错误。各种reverse题目大同小异都在隐藏flag、隐藏判定过程上做手脚。
异或是指对于命题A,B,A XOR B的运算。当A、B两两数值相同为否,而数值不同时为真。这个运算具有一个性质:自反律,即A XOR B XOR B = A,即将某明文对密码异或,得到的密文再对密码异或又可以得到明文。利用这个性质,可以将用户的输入与密码异或,与内存中已经异或并存储的flag字符串进行比对。(在C语言里,异或XOR表示为^
#include <stdio.h> #include <string.h> char flag[10] = { 102,10,107,12,119,7,110,19,35 }; int main() { char input[256] = { 0 }; printf("input your flag:"); scanf("%s", input); input[255] = '\0'; for (int i = strlen(flag)-1; i > 0 ; i--) { flag[i] = flag[i] ^ flag[i - 1]; } flag[8] = '\0'; if (strcmp(flag, input)) { printf("\nYou are correct!"); } else { printf("\nYou failed"); } return 0; }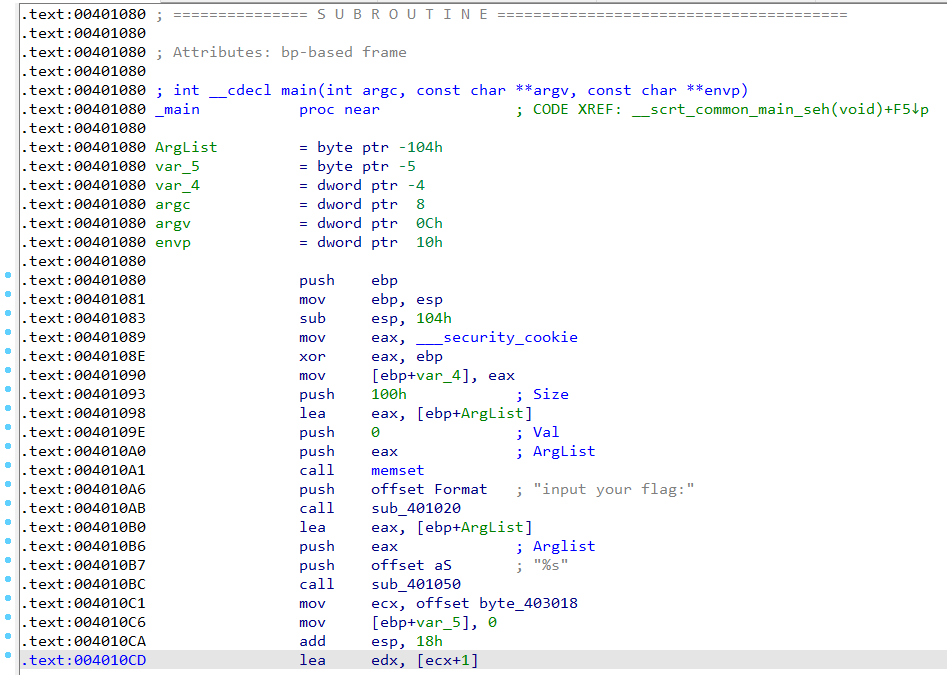
上述程序在IDA的汇编分析下看不出端倪,并且神奇的是原程序里定义的全局变量也不见了。这就是IDA的缺陷之处,因为IDA必须按照一定的准则方能猜测字符串、全局变量的存在。但是这没关系,我们检查他的伪代码:
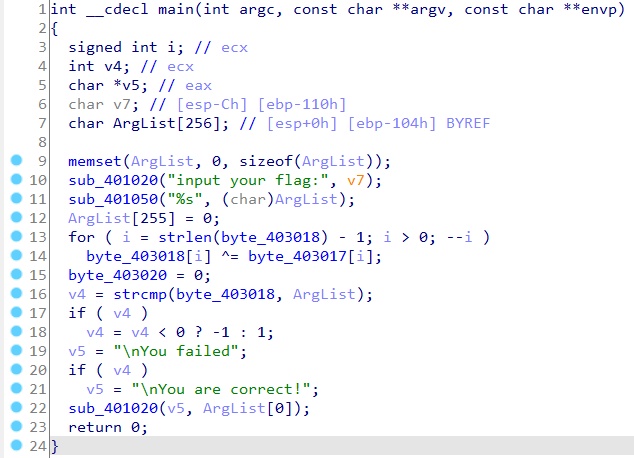
乍一看毫无头绪,但是仔细观察一些循环、判断结构就会发现IDA不过将一些本该写道一行的代码写到了两行。这并不影响我们对代码逻辑进行分析

我们可以确定程序对这个
byte_???变量进行了异或操作,跟踪此变量: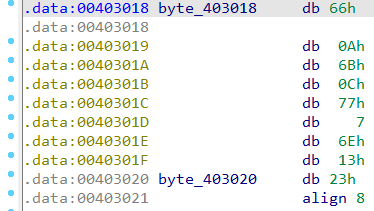
对于
.data断,其中有指令align 8:align伪指令将一个变量对齐到字节边界、字边界、双字边界或段落边界。为了满足对齐要求,汇编器会在变量前插入一个或多个空字节。为什么要对齐数据?因为,对于存储于偶地址和奇地址的数据来说,CPU 处理偶地址数据的速度要快得多**。这里进行了数据对齐,并且接下来的数据都是db 0,因此可以断定这是一个用特殊方法声明的字符串。,也就对应了源文件里的char flag[10] = { 102,10,107,12,119,7,110,19,35 };将这段数据按照程序的逻辑异或就可以得到flag
-
凯撒密码
凯撒密码和异或加密大同小异。凯撒密码(Caesar cipher),或称凯撒加密、凯撒变换、变换加密,是一种最简单且最广为人知的加密技术。凯撒密码是一种替换加密技术,明文中的所有字母都在字母表上向后(或向前)按照一个固定数目进行偏移后被替换成密文。例如,当偏移量是3的时候,所有的字母A将被替换成D,B变成E,以此类推。这个加密方法是以罗马共和时期凯撒的名字命名的,据称当年凯撒曾用此方法与其将军们进行联系。凯撒密码通常被作为其他更复杂的加密方法中的一个步骤,例如维吉尼亚密码。凯撒密码还在现代的ROT13系统中被应用。但是和所有的利用字母表进行替换的加密技术一样,凯撒密码非常容易被破解,而且在实际应用中也无法保证通信安全。
-
base64混淆
Base64(基底64)是一种基于64个可打印字符来表示二进制数据的表示方法。由于log(2,64)=6,所以每6个比特为一个单元,对应某个可打印字符。3个字节相当于24个比特,对应于4个Base64单元,即3个字节可由4个可打印字符来表示。在Base64中的可打印字符包括字母A-Z、a-z、数字0-9,这样共有62个字符,此外两个可打印符号在不同的系统中而不同。一些如uuencode的其他编码方法,和之后BinHex的版本使用不同的64字符集来代表6个二进制数字,但是不被称为Base64。
Base64常用于在通常处理文本数据的场合,表示、传输、存储一些二进制数据,包括MIME的电子邮件及XML的一些复杂数据。
Base64的特征在于:
- 字符串末尾存在"="或者"=="
- 密文长度一定是4的倍数
在程序中,Base64加密的特征在于:
-
存在一个密文表,其形式为
ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/

(这里展示的是非常规Base64加密的密码表)
(拓展)Base64加解密过程介绍
Base64的主要思想是将3个字节的数据映射为4个字节的数据.从二进制观点看,3字节一共24
bit,把24bit依次分组生成4个字节.根据Base64的映射表就可以确定密文.相对的,也就可以推出明文.因为6个bit最多能表示64种模式,因此Base64编码出来的字符种类只有64个,这也是Base64名字的由来。
从ASCII中0x20 ~ 0x7E(可打印字符)选出64个普通的ASCII字符建立映射表:
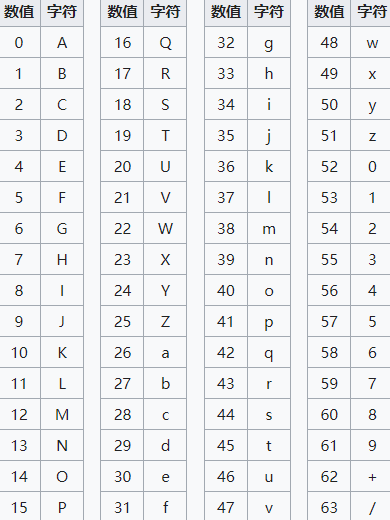
如果要编码的字节数不能被3整除,最后会多出1个或2个字节,那么可以使用下面的方法进行处理:先使用0字节值在末尾补足,使其能够被3整除,然后再进行Base64的编码。在编码后的Base64文本后加上一个或两个
=号,代表补足的字节数。也就是说,当最后剩余两个八位(待补足)字节(2个byte)时,最后一个6位的Base64字节块有四位是0值,最后附加上两个等号;如果最后剩余一个八位(待补足)字节(1个byte)时,最后一个6位的base字节块有两位是0值,最后附加一个等号。 参考下表: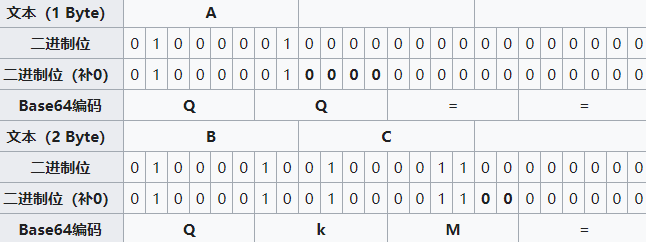
- 简单异或加密
-
爆破
对于具有输入的代码,可以对应的写一个自动化脚本不断试错。这样的解题方法因为耗时长,因此作为下策在万不得已时使用。 -
迷宫
这类题目的flag字符串不存在程序内部,他们的flag字符串是一系列操作的组合。在程序内部生成一个迷宫,这个迷宫需要按照特定的方法,输入字符,操作光标移动最终到达终点。输入的字符组合就是flag。其特征为:存在一个switch判断或者多个if判断,并且其中含有一个包含大量重复字符和空格的字符串。例如#s###### # # # ## # # # ## # # ###### # # # #e######这样的字符串一般可以组成一个矩阵。
-
-
pyc文件
使用uncompyle6进行字节码反编译。由于pyc文件是python源码生成的一种字节码,因此可以很方便的反编译生成源码。pip install uncompyle6 uncompyle6 -o code.py target.pyc其中的code.py是保存到的位置,target.pyc为题目的pyc文件
-
-
常见问题
1. 字符串逆序 根据内存模型,对于小段(littile-ending)存储方法,所有在内存里的数据都是倒序存储的。因此从汇编代码里读出的数据可能需要进行反向,以便进一步分析。
作者发布、转载的任何文章中所涉及的技术、思路、工具仅供以安全目的的学习交流,并严格遵守《中华人民共和国网络安全法》、《中华人民共和国数据安全法》等网络安全法律法规。
任何人不得将技术用于非法用途、盈利用途。否则作者不对未许可的用途承担任何后果。
本文遵守CC BY-NC-SA 3.0协议,您可以在任何媒介以任何形式复制、发行本作品,或者修改、转换或以本作品为基础进行创作
您必须给出适当的署名,提供指向本文的链接,同时标明是否(对原文)作了修改。您可以用任何合理的方式来署名,但是不得以任何方式暗示作者为您或您的使用背书。
同时,本文不得用于商业目的。混合、转换、基于本作品进行创作,必须基于同一协议(CC BY-NC-SA 3.0)分发。
如有问题, 可发送邮件咨询.


 浙公网安备 33010602011771号
浙公网安备 33010602011771号