[参考]多线程之争:用C还是用python
多线程之争:用C还是用python
本文主要介绍不同负载下,两种不同的编码方式的多线程运行速度,作为参考。
背景
一些任务,例如下载网页图片、爆破哈希、大规模运算等任务,用单线程跑显然太慢。然而在一次跑熵计算的应用中,使用python的concurrent.further写个协程跑的还更慢了,索性换C来跑,结果快的不少。作为开发技术,在这里记录一下。
将讨论下述应用场景并给出一定的代码示例,主要是自用。
- python:使用多线程下载
telegra.ph的图片 - C:使用WinAPI进行并行计算,并和python的等价代码进行性能比较
首先要说一说并发和并行的区别(操作系统基础):
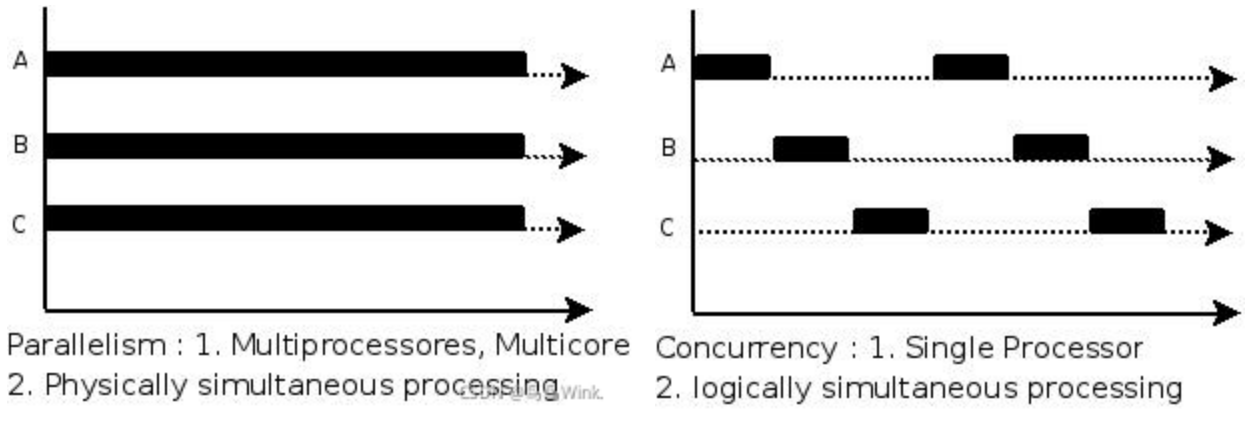
- 并发(Concurrency):实际上是处理器调度。单个处理单元轮换调度并处理诸多问题,这个“诸多”问题可以是某一个问题的子任务。
- 并行(Parallelism):将一个任务拆分为多个子任务,多个子任务分配给不同的多个处理单元,通过物理处理机的硬件优势同时的处理多个任务。
因此,对于大部分任务,结合现在的计算机硬件性能,我觉得并行的需求更为明确。
对于有人问的异步和同步,这是编程概念。异步是一种编程模型,用于处理非阻塞式的任务调度和执行。
还有协程。协程的系统资源占用比thread小,对于异步开发更佳,但是对于阻塞IO来说是个头疼的问题(至少我不会)
Python的假并发——GIL
GIL只存在于CPython,即使用C语言实现的Python上。
In CPython, the global interpreter lock, or GIL, is a mutex that protects access to Python objects, preventing multiple threads from executing Python bytecodes at once. The GIL prevents race conditions and ensures thread safety.
CPython中,为了安全性和同步问题,Python的实现器在所有多线程环境中,不论有多少线程,都只允许同时存在一个正在执行字节码的线程。GIL实际上是一种互斥机制,避免了内存访问问题(例如多个线程同时读写一块内存导致的混乱)和变量竞争(例如多个线程同时读写一个变量,本质上是内存竞争)。作为一种全局的互斥锁,此锁避免了大部分多线程的编程问题by killing multithreading
在CPython中,每一个Python线程执行前都需要去获得GIL锁 ,获得该锁的线程才可以执行,没有获得的只能等待 ,当具有GIL锁的线程运行完成后,其他等待的线程就会去争夺GIL锁,这就造成了,在Python中使用多线程,但同一时刻下依旧只有一个线程在运行 ,所以Python多线程其实并不是「并行」的,而是「并发」 。
虽然 Python 在某些情况下受到 GIL 的限制,但仍然可以通过多进程、异步编程和外部扩展模块等方式实现并发计算,以提高程序的性能和效率。选择适当的并发模型取决于任务的性质和要求。
当然,这个问题已经在2023年1月被提出,并作为Proposal(PEP 703 – Making the Global Interpreter Lock Optional in CPython | peps.python.org)提请到了Python的委员会。这个Proposal提议用一个开关--disable-gil来关闭GIL,让程序员自己保证线程安全。
实例
Python下载图片
首先给出一个使用Python下载网页的示例。对于互联网下载这种存取型任务,其主要的性能瓶颈在于网速和网络限制,因此对于并发和并行而言,虽然可以使用并行,但是效率提升不大。
https://gist.github.com/Holit/d89818543b7c4d5938348bfaaaec3dfb
#telegra.ph image download script
import urllib.request
from bs4 import BeautifulSoup
import re
import gzip
import sys
import os
import threading
import concurrent.futures
import requests
SavePath = ""
headers = {
'Host':'telegra.ph',
'Connection':'keep-alive',
'Cache-Control':'max-age=0',
'sec-ch-ua':'"Chromium";v="112", "Microsoft Edge";v="112", "Not:A-Brand";v="99"',
'sec-ch-ua-mobile':'?0',
'sec-ch-ua-platform':"Windows",
'DNT':'1',
#'Upgrade-Insecure-Requests':' 1',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36 Edg/112.0.1722.58',
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7',
'Accept-Language' : 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'Sec-Fetch-Site':'none',
'Sec-Fetch-Mode':'navigate',
'Sec-Fetch-User':'?1',
'Sec-Fetch-Dest':'document',
#'Referer':' https://www.google.com.hk/',
'Accept-Encoding':'gzip',
#'Accept-Language':' zh-CN,zh;q=0.9',
#'Cookie':' country=hk',
}
def get_page_img_url(base_url):
host = ''
match = re.match(r"(https?://[^\s/]+)",base_url)
if match:
host = match.group(1)
else:
raise Exception('[!] Unable to find host url! - This problem shall not happen!')
url_dict = []
req = urllib.request.Request(base_url, headers=headers)
res = urllib.request.urlopen(req)
data = res.read()
if res.headers.get('Content-Encoding') == 'gzip':
data = gzip.decompress(data)
soup = BeautifulSoup(data,"html.parser")
div_elements = soup.find(name='article', attrs={'class': 'tl_article_content'})
img_dicts = div_elements.findAll('img')
for img_item in img_dicts:
url = img_item.get('src')
url_dict.append(host + url)
return url_dict
max_threads = 16
thread_lock = threading.BoundedSemaphore(value=max_threads)
def download_image(url, filename):
try:
response = requests.get(url,headers=headers)
if response.status_code == 200:
with open(filename, "wb") as file:
file.write(response.content)
print(f' [+] Successfully downloaded {filename}')
thread_lock.release()
#req = urllib.request.Request(url)
#response = urllib.request.urlopen(req)
#with open(filename, "wb") as file:
# file.write(response.read(response.length))
# print(f' [+] Successfully downloaded {filename}')
# thread_lock.release()
except Exception as e:
print(f'[!] Exception : {url} -> {filename}')
print(e)
def download_imgs(url_dict, path : str):
try:
threads = []
for url in url_dict:
file_name = re.search(r"/([^/]+)$", url).group(1)
thread_lock.acquire()
thread = threading.Thread(target=download_image, args=(url, path + file_name))
threads.append(thread)
thread.start()
for thread in threads:
thread.join()
except:
input()
BaseURL = sys.argv[1]
host = ''
match = re.match(r"(https?://[^\s/]+)",BaseURL)
if match:
host = match.group(1)
print(f'[+] Host={host}')
else:
raise Exception('[!] Unable to find host url! - This problem shall not happen!')
print(f'[+] SavePath={SavePath}')
req = urllib.request.Request(BaseURL, headers=headers)
res = urllib.request.urlopen(req)
data = res.read()
if res.headers.get('Content-Encoding') == 'gzip':
data = gzip.decompress(data)
soup = BeautifulSoup(data,"html.parser")
h1 = soup.find('h1')
records = []
records.append({'title' : h1.string, 'url' : BaseURL})
div_elements = soup.find(name='article', attrs={'class': 'tl_article_content'})
a_dicts = div_elements.findAll('a')
print(f'[+] Page contains {len(a_dicts)} links.')
for a_item in a_dicts:
if(a_item.get('target') == None):
title = a_item.string
url = a_item.get('href')
records.append({'title' : title, 'url' : host + url})
print(f'[+] Fetched {len(records)} records.')
for record in records:
title = record['title']
url = record['url']
print(f'[+] Downloading {title}...')
parent_path = SavePath + title + '\\'
if(not os.path.exists(parent_path)):
os.mkdir(parent_path)
img_urls = get_page_img_url(url)
download_imgs(img_urls, parent_path)
这里使用了thread的方法,同样的,可以用concurrent实现download_imgs
#...
def download_imgs(url_dict, path : str):
try:
with concurrent.futures.ThreadPoolExecutor() as executor:
futures = []
for url in url_dict:
file_name = re.search(r"/([^/]+)$", url).group(1)
future = executor.submit(download_image, url, path + file_name)
futures.append(future)
for future in concurrent.futures.as_completed(futures):
result = future.result()
except Exception as e:
input()
#...
用协程写:
#...
async def download_imgs(url_dict, path):
try:
tasks = []
async with aiohttp.ClientSession() as session:
for url in url_dict:
file_name = re.search(r"/([^/]+)$", url).group(1)
task = asyncio.create_task(download_image(session, url, path + file_name))
tasks.append(task)
await asyncio.gather(*tasks)
except Exception as e:
print(e)
async def download_image(session, url, file_path):
async with session.get(url) as response:
with open(file_path, 'wb') as file:
while True:
chunk = await response.content.read(1024)
if not chunk:
break
file.write(chunk)
#...
计算熵
这是一个测试项目,从一个文件中逐字节读取\(N\)个字节,并计算前\(N\)个字节的信息熵。信息熵的计算公式如下:
还可以定义事件 X 与 Y 分别取 \(x_i\) 和\(y_i\)时的条件熵为
使用Python写一个,这里利用了concurrent.future。
from importlib.metadata import entry_points
import os
import sys
import math
import numpy as np
from collections import Counter
import matplotlib.pyplot as plt
import concurrent.futures
import threading
import time
def calculate_entropy(string):
# 统计字符频率
char_count = Counter(string)
total_chars = len(string)
# 计算每个字符的概率
probabilities = [char_count[char] / total_chars for char in char_count]
# 计算信息熵
entropy = -sum(p * math.log2(p) for p in probabilities)
return entropy
def calculate_entropy_incremental(file_path):
entropy_list = []
def calculate_entropy_partial(partial_text,index):
entropy = calculate_entropy(partial_text)
# 使用互斥锁确保线程安全地添加到列表
entropy_list.append(
{
'value': entropy,
'index': index
}
)
with open(file_path, 'r', encoding='utf-8') as file:
text = file.read()
chunk_size = 1 # 将文件分成32个块
pos = 0
with concurrent.futures.ThreadPoolExecutor(max_workers=128) as executor:
futures = []
while pos < len(text):
partial_text = text[0:pos]
future = executor.submit(calculate_entropy_partial, partial_text,pos)
futures.append(future)
pos = pos+1
# 等待所有线程完成
concurrent.futures.wait(futures)
# 按照字节顺序排序
#entropy_list.sort(key=lambda x: x[0])
entropy_list = sorted(entropy_list, key=lambda x: x['index'])
entropy_list = [item['value'] for item in entropy_list]
return entropy_list
def plot_entropy(entropy_list):
x = range(len(entropy_list))
y = entropy_list
plt.plot(x, y)
plt.xlabel('Bytes')
plt.ylabel('Entropy')
plt.title('File entropy(incremental)')
# 计算最大值和平均值
max_entropy = max(entropy_list)
avg_entropy = np.mean(entropy_list)
# 绘制最大值线
plt.axhline(max_entropy, color='red', linestyle='--', label='Max Entropy')
# 绘制平均值线
plt.axhline(avg_entropy, color='blue', linestyle='--', label='Average Entropy')
# 标注熵值
plt.text(0, max_entropy, f'{max_entropy:.2f}', ha='left', va='center', color='red')
plt.text(0, avg_entropy, f'{avg_entropy:.2f}', ha='left', va='center', color='blue')
plt.legend()
plt.show()
if len(sys.argv) < 2:
raise Exception(f'Usage: {sys.argv[0]} filepath')
if os.path.exists(sys.argv[1]) == False:
raise Exception(f'Invalid path {sys.argv[1]}')
start_time = time.time()
entropy_list = calculate_entropy_incremental(sys.argv[1])
end_time = time.time()
# 计算耗时(毫秒)
elapsed_time = (end_time - start_time) * 1000
print("总耗时:{:.4f} 毫秒".format(elapsed_time))
plot_entropy(entropy_list)
同样的,使用C写一个,直接用WinAPI
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
#include <time.h>
#include <string.h>
#include <windows.h>
#include <stdint.h>
#include <intrin.h>
static double* entropy_list = NULL;
static long len_entropy_list = 0;
static long entropy_list_pos = 0;
static long segment_size = 0;
char* text = NULL;
#define THREAD_COUNT 32
CRITICAL_SECTION cs;
HANDLE hMutex; // 互斥锁
HANDLE hMutexText;
double calculate_entropy(const char* string) {
int char_count[256] = { 0 };
int total_chars = 0;
// 统计字符频率
for (int i = 0; string[i] != '\0'; i++) {
char_count[(unsigned char)string[i]]++;
total_chars++;
}
// 计算每个字符的概率
double probabilities[256];
for (int i = 0; i < 256; i++) {
probabilities[i] = (double)char_count[i] / total_chars;
}
// 计算信息熵
double entropy = 0;
for (int i = 0; i < 256; i++) {
if (char_count[i] > 0) {
double p = probabilities[i];
entropy -= p * log2(p);
}
}
return entropy;
}
DWORD WINAPI CalculateEntropyThread(LPVOID lpParam)
{
long pos = (long)lpParam;
for (int i = 0; i < segment_size; i++)
{
EnterCriticalSection(&cs);
WaitForSingleObject(hMutexText, INFINITE);
char* partial_text = (char*)malloc((pos + i + 1) * sizeof(char));
memset(partial_text, 0, (pos + i + 1) * sizeof(char));
if (text == NULL || partial_text == NULL)
{
throw "Unexpected null pointer: text!";
return -4;
}
strncpy(partial_text, text, pos + i);
ReleaseMutex(hMutexText);
partial_text[pos + i] = '\0';
WaitForSingleObject(hMutex, INFINITE);
entropy_list[pos + i] = calculate_entropy(partial_text);
ReleaseMutex(hMutex);
LeaveCriticalSection(&cs);
free(partial_text);
InterlockedIncrement(&entropy_list_pos);
}
return 0;
}
double* calculate_entropy_incremental(const char* file_path) {
FILE* file = fopen(file_path, "r");
if (file == NULL) {
printf("Invalid path: %s\n", file_path);
return NULL;
}
long file_size = 0;
fseek(file, 0, SEEK_END);
file_size = ftell(file);
rewind(file);
text = (char*)VirtualAlloc(NULL, file_size + 1, MEM_COMMIT, PAGE_READWRITE);
fread(text, sizeof(char), file_size, file);
text[file_size] = '\0';
entropy_list = (double*)malloc((file_size + 1) * sizeof(double));
len_entropy_list = file_size + 1;
int pos = 0;
const int numThreads = 8;
HANDLE hThreads[numThreads];
segment_size = file_size / numThreads;
// 动态生成线程
for (int i = 0; i < numThreads; i++)
{
hThreads[i] = CreateThread(NULL, 0, CalculateEntropyThread, (LPVOID)(i * segment_size), 0, NULL);
if (hThreads[i] == NULL)
{
printf("Failed to create thread %d\n", i);
}
}
WaitForMultipleObjects(numThreads, hThreads, TRUE, INFINITE);
// 释放线程资源
for (int i = 0; i < numThreads; i++)
{
CloseHandle(hThreads[i]);
}
VirtualFree(text, 0, MEM_RELEASE);
fclose(file);
entropy_list[file_size] = entropy_list[file_size - 1];
return entropy_list;
}
void plot_entropy(const double* entropy_list, int size) {
// 绘制折线图的代码,请根据需要使用合适的绘图库
// 例如,可以使用gnuplot库进行绘图
FILE* gnuplot = _popen("gnuplot -persist", "w");
if (gnuplot != NULL) {
fprintf(gnuplot, "set term wxt size 1920, 1080\n"); // 设置绘图窗口分辨率为 1024x768
fprintf(gnuplot, "set xlabel 'Bytes'\n");
fprintf(gnuplot, "set ylabel 'Entropy'\n");
fprintf(gnuplot, "set title 'File entropy(incremental)'\n");
fprintf(gnuplot, "plot '-' with lines title 'Entropy'\n");
for (int i = 0; i < size; i++) {
fprintf(gnuplot, "%d %f\n", i, entropy_list[i]);
}
fprintf(gnuplot, "e\n");
_pclose(gnuplot);
}
else
{
printf("Unable to open gnuplot for configuration.\n\n");
return;
}
}
int main(int argc, char* argv[]) {
if (argc < 2) {
printf("Usage: %s filepath\n", argv[0]);
return 1;
}
if (GetFileAttributesA(argv[1]) == INVALID_FILE_ATTRIBUTES)
{
printf("Invalid path: %s\n", argv[1]);
return 1;
}
uint64_t start, end;
uint64_t frequency;
if (!QueryPerformanceFrequency((LARGE_INTEGER*)&frequency)) {
printf("Failed to query performance frequency.\n");
return 1;
}
InitializeCriticalSection(&cs);
start = __rdtsc();
double* entropy_list = calculate_entropy_incremental(argv[1]);
end = __rdtsc();
DeleteCriticalSection(&cs);
if (entropy_list == NULL)return -1;
double elapsed_time = (double)(end - start) / frequency;
printf("Total time: %.6f milliseconds\n", elapsed_time);
if (entropy_list != NULL) {
plot_entropy(entropy_list, len_entropy_list);
free(entropy_list);
}
return 0;
}
结果是
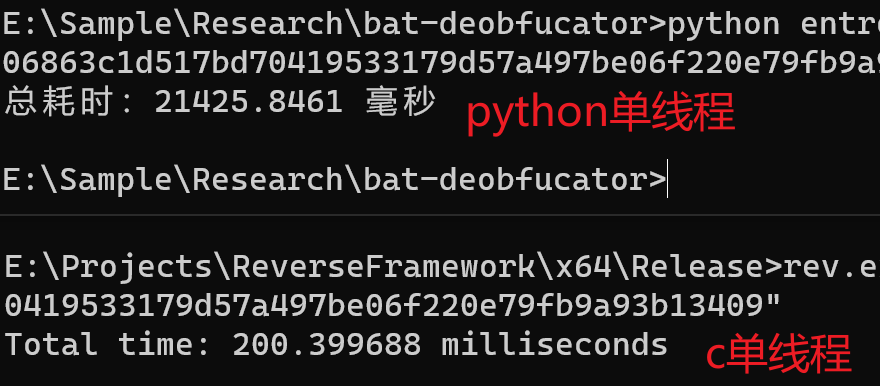
如果把Python版本的单线程按照上述代码更改为多线程(32),其性能提升如何呢?
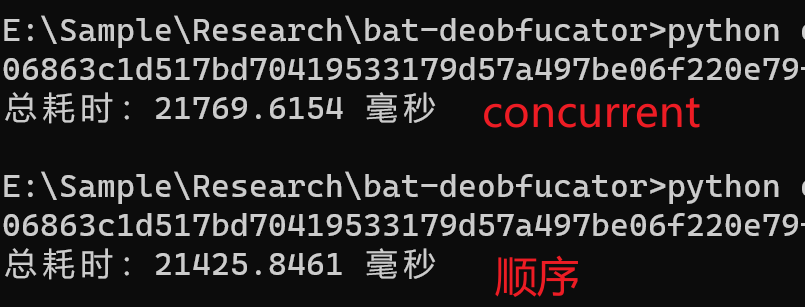
答:没有提升,原因是这是一个计算密集型任务,单纯的轮换调度(并发)并不能很好的完成这个任务。
结论
- 对于计算密集任务,请用C
- 对于Python的并发,请用concurrent
作者发布、转载的任何文章中所涉及的技术、思路、工具仅供以安全目的的学习交流,并严格遵守《中华人民共和国网络安全法》、《中华人民共和国数据安全法》等网络安全法律法规。
任何人不得将技术用于非法用途、盈利用途。否则作者不对未许可的用途承担任何后果。
本文遵守CC BY-NC-SA 3.0协议,您可以在任何媒介以任何形式复制、发行本作品,或者修改、转换或以本作品为基础进行创作
您必须给出适当的署名,提供指向本文的链接,同时标明是否(对原文)作了修改。您可以用任何合理的方式来署名,但是不得以任何方式暗示作者为您或您的使用背书。
同时,本文不得用于商业目的。混合、转换、基于本作品进行创作,必须基于同一协议(CC BY-NC-SA 3.0)分发。
如有问题, 可发送邮件咨询.


 浙公网安备 33010602011771号
浙公网安备 33010602011771号