
利用sklearn中 ID3算法实现简单的课程销量预测+决策树可视化
决策树中ID3算法是一种贪心算法,用来构造决策树。ID3算法主要用到每个属性的信息增益,使用到信息熵。ID3算法计算每个属性的信息增益,并选取具有最高增益的属性作为给定集合的测试属性。对被选取的测试属性创建一个节点,并以该节点的属性标记,对该属性的每个值创建一个分支据此划分样本.
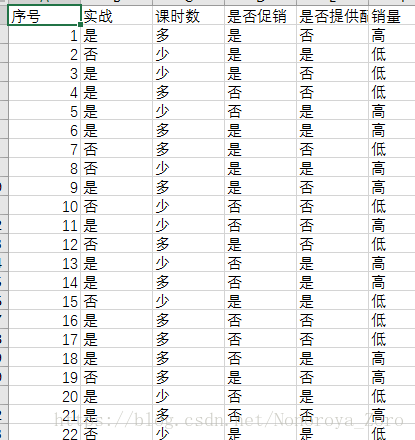
信息熵从通俗易懂的角度来说就是信息的价值。比如本次是做对网络上课程销量的预测,而影响一门课程销量的因素有该课程是否有配套资料或源码、是否有实战教程、是否有促销活动、课时数的数量多少等,假如一门课程是以实战为前提,并且有配套资料,那么大多数人会选择购买此类课程学习,所以实战和资料的信息价值就很大。
变量的不确定性越大,熵也就越大,把它搞清楚所需要的信息量也就越大。
信息熵是信息论中用于度量信息量的一个概念。一个系统越是有序,信息熵就越低;
反之,一个系统越是混乱,信息熵就越高。所以,信息熵也可以说是系统有序化程度的一个度量。
- 课程数据内容,显示没门课程的实战、课时数等相关信息,为训练数据,测试数据由自己定。
- 代码实现:
import pandas as pda fname="./lesson.csv" dataf=pda.read_csv(fname,encoding="gbk") x=dataf.iloc[:,1:5].as_matrix() y=dataf.iloc[:,5].as_matrix() for i in range(0,len(x)): for j in range(0,len(x[i])): thisdata=x[i][j] if thisdata=="是" or thisdata == "多" or thisdata == "高": x[i][j]=int(1) else: x[i][j] = -1 for i in range(0, len(y)): thisdata = y[i] if thisdata == "高": y[i] = 1 else: y[i] = -1 #需要将数据x,y转化好格式,数据框dataframe,否则格式报错 xf = pda.DataFrame(x) yf = pda.DataFrame(y) x2 = xf.as_matrix().astype(int) y2 = yf.as_matrix().astype(int) #建立决策树 from sklearn.tree import DecisionTreeClassifier as dtc #设置参数为信息熵模式 dtcx = dtc(criterion="entropy") dtcx.fit(x2,y2) #训练 #可视化决策树 from sklearn.tree import export_graphviz from sklearn.externals.six import StringIO file=StringIO() export_graphviz(dtcx,feature_names=[r"实战",r"课时数",r"促销",r"配套资料"],out_file=file)
测试内容可以使用以下,预测有实战、课时数少、不促销、没有配套资料的课程的销量:
test=pda.DataFrame(data=[[1,-1,-1,-1]]).as_matrix().astype(int)
a = dtcx.predict(test)
print(a)
可以看到是否有实战的信息价值十分重要,即使没有其他内容,只要有实战,该课程的销量也应该不错。
- 将决策树可视化
决策树可视化利用到graghviz工具,下载地址http://www.graphviz.org/download/
下载完成后,将该工具安装目录下的bin目录假如到环境变量中,即可使用dos命令进行决策树的转化,完成可视化。
使用一下命令将文件进行转化,输出为可视化文件。
dot -Tpng <filename> -o <outfilename>
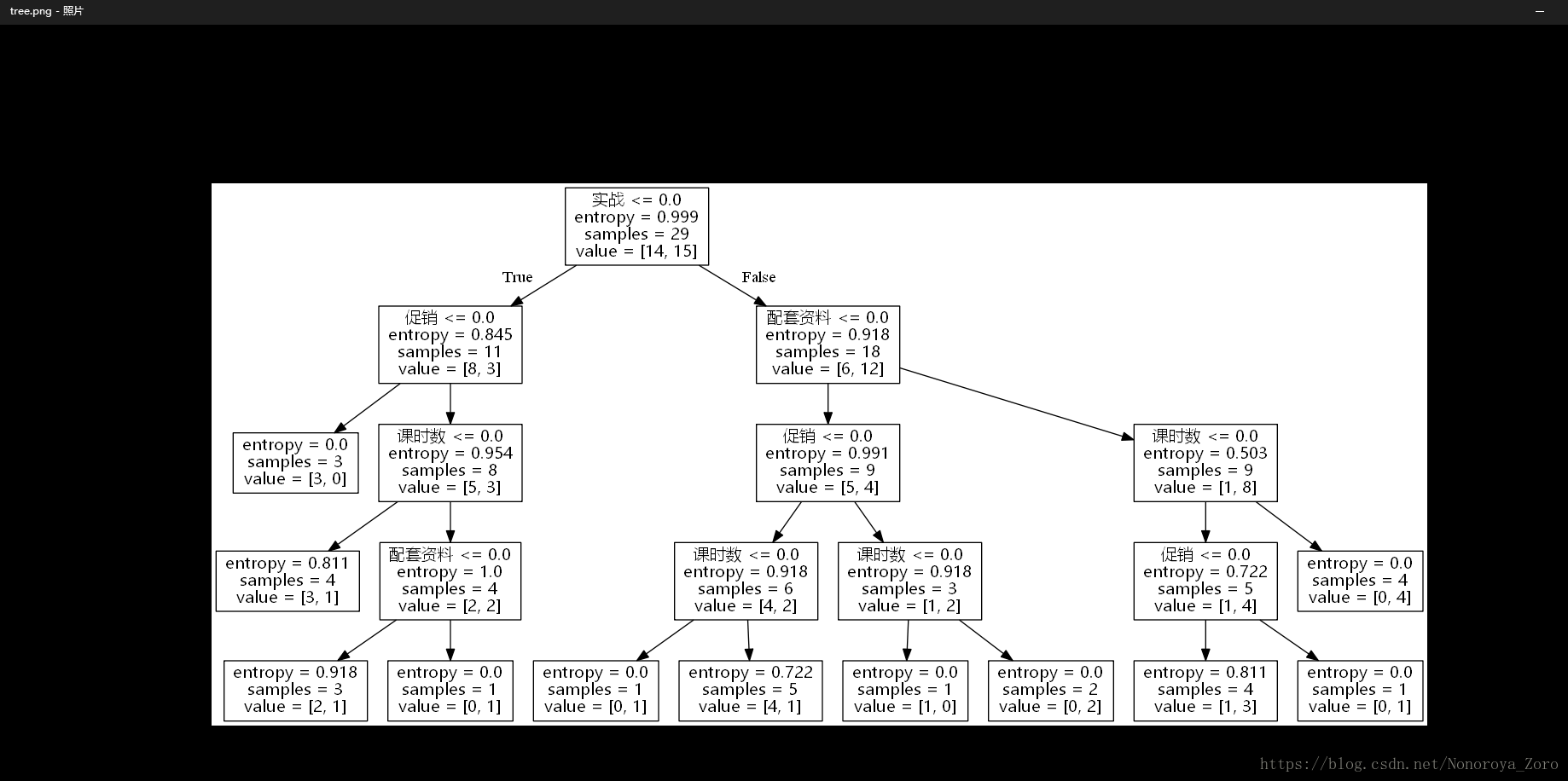
观察上图,可以看到实战的信息价值最高(以此类推),当有实战教程,往右分支走,反之往左分支走。
其中每个节点中的内容,第一行代码对应属性的分支,起判断条件,如果一个测试内容进行预测,则进行属性判断。第二行代表该属性的熵,越大,则有该属性确定的销量的所需信息就越少。第三行表示该属性的数据量总共多少。对应的第四行为无实战教程和有实战教程的数据量,两者相加就是第三行的数据量。
PS:
关于graghviz中文乱码的问题:
打开决策树内容文件,在其中添加字体类型为微软雅黑字体即可。文本保存要是utf-8格式,不要使用windows记事本更改格式,在dot绘图转换时出现错误提示。可以使用notepad或其他文本编辑器转换文本编码。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号