寒假作业(2/2)
寒假作业(2/2)
| 这个作业属于哪个课程 | 课程链接 |
|---|---|
| 这个作业要求在哪里 | 作业要求链接 |
| 这个作业的目标 | 学会使用git,github,认真阅读构建之法 |
| 作业正文 | 如下 |
| 其他参考文献 | 《构建之法》 |
- part1:阅读《构建之法》并提问
- part2:WordCount编程
- Github项目地址
- PSP表格
- 计算模块接口的设计与实现过程
- 解题思路描述
- 代码规范制定链接
- 设计与实现过程
- 性能改进
- 单元测试
- 异常处理说明
- 心路历程与收获
part1:阅读《构建之法》并提问
问题1:

--《构建之法》第一章的作者的一个提问,结合自身的阅历和作者后面的叙述。我自己有时候也会有这种想法,辛辛苦苦写了一个功能,还要改好久的bug,然后发现已经有现成的了,就会感觉努力可能有点白费啥的,个人感觉这个过程主要是在锻炼自己对算法数据结构的理解,更好的掌握基础的东西,以后套用别人现成的才会灵活。个人感觉一个优秀的程序员应该要有较强的自学能力,对基础知识掌握牢固,一些具体细节的话可以面对百度编程。
问题2:

--这是《构建之法》第21页的截图,不懂的是如何让团队之间的配合,代码之间的隔阂少一点?个人的编程经验挺少的,一般合作的项目都是老师布置的,和同学一起负责一个考试系统的后端,然后就会出现我写的代码自己测试没问题,但是在他的电脑测试整合时出了点问题。为了方便搭档的理解,一般就规定好变量名和注释尽可能详细,不过调用别人的代码目前对于我还是挺头疼的,特别是看编程大佬的代码。
问题3:

--书本35页关于大学生和社会工作的工程师psp数据比较,其实也算不上大的问题,就是没想到工程师在代码编写前的准备和编写后的整理和复审测试花的时间比例比大学生多挺多的。而在具体编程方面花的时间比较少,是因为工作的内容详细单一,重复套框架变熟练嘛。目前作为一个编程新手时间主要还是花在编程设计和代码编程中,想知道工程师一天多久是在敲代码和思考敲代码。
问题4:


--出自《构建之法》56页的一段话,觉得挺有意思的,因为寒假第一次作业我就说过相关的事情,就是只是把编程当作一项赚钱的工作,编程的动力更多是来自压力,而不是自己主动的兴趣,所以编程水平一直中流,然后结合课本的例子和老师给的建议,有了自己对以后的了解。
问题5:

--出自《构建之法》353页,有关创新的部分,问题就是一定得专家领域才能创新嘛?答案肯定是否定的,个人感觉创新就是一个短暂一闪而过的念头,可能是不是你擅长领域的新念头,每个人都能有创新,不过感觉在某一方面越在行,确实更容易有所创新和突破,而且也更有可能把点子真正实现,所以终归有创新不够,还是也得学习和研究。
问题6:

--选自《构建之法》408页的截图,感觉描述得很形象生动,挺有感触的,关于这部分所谓价值观是待人友善,挺老板的话,然后勤奋工作嘛。未来对于自己,业绩和价值观都没有太大的把握,感觉自己的人格还在完善阶段,有时候心血来潮挺努力,挺有干劲的,但是过不久或者是稍微学了一会儿就开始放松。个人还不想太早出来工作,努力考个研希望可以让自己更有价值,顺带更成熟沉稳。
附加题:
1952年,图灵写了一个国际象棋程序。可是,当时没有一台计算机有足够的运算能力去执行这个程序,他就模仿计算机,每走一步要用半小时。他与一位同事下了一盘,结果程序输了。后来美国新墨西哥州洛斯阿拉莫斯国家实验室的研究群根据图灵的理论,在MANIAC上设计出世界上第一个计算机程序的象棋。从1952年直到去世,图灵一直在数理生物学方面做研究。他在1952年发表了一篇论文《形态发生的化学基础》(The Chemical Basis of Morphogenesis)。它主要的兴趣是费班纳赛叶序列(Fibonacci phyllotaxis),存在于植物结构的费班纳赛数。他应用了反应-扩散公式,现在已经成为图案形成范畴的核心。他后期的论文都没有发表,一直等到1992年《艾伦·图灵选集》出版,这些文章才见天日。
故事链接:http://sunny204.blog.sohu.com/18429897.html
part2:wordCount编程
Github项目地址:
https://github.com/Hector2333/PersonalProject-Java.git
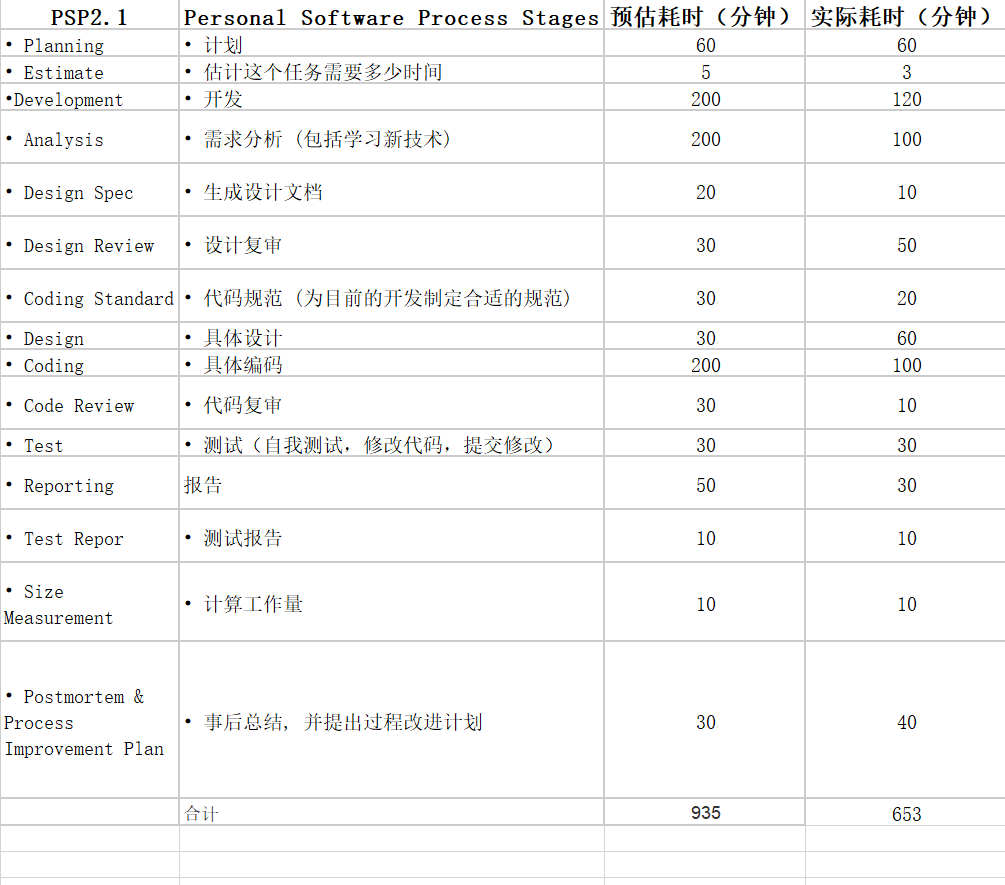
PSP表格:
计算模块接口的设计与实现过程:
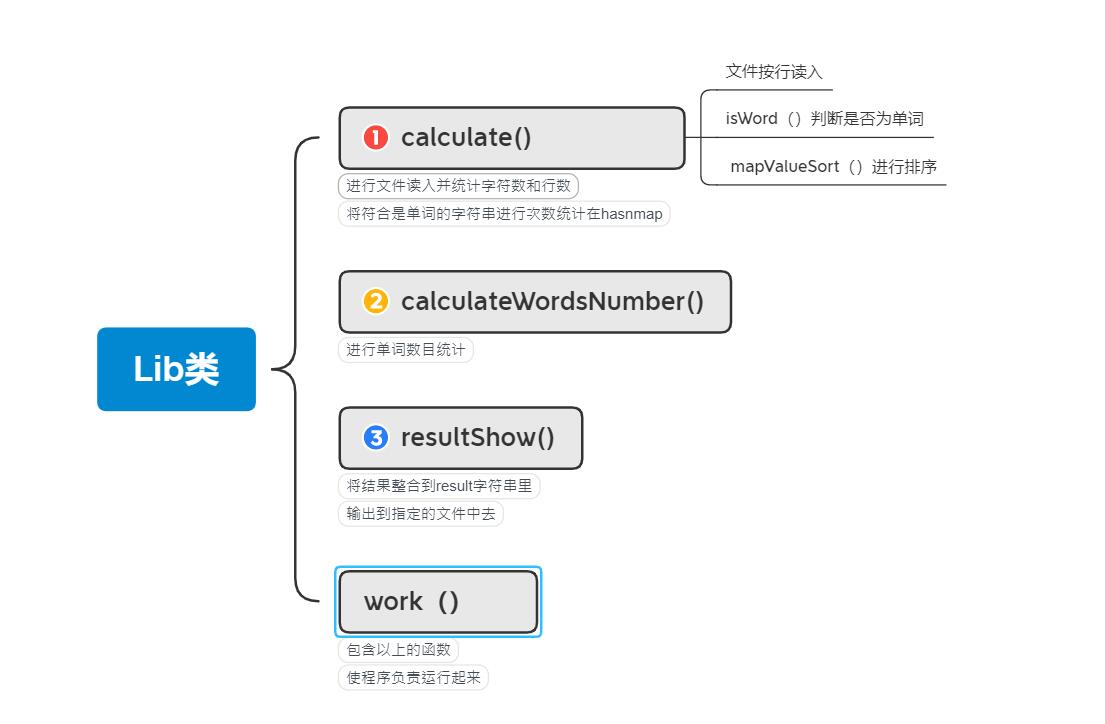
--代码包含的类有三个,一个是Lib.java工具类,包含了所有统计的方法;一个是WordCount.java用来运行;还有一个ce'shi测试类LibTest.java。Lib的构建函数导入要统计文件的地址和统计结果输出的文件地址。Lib类里面有一个总的work()函数运行,运行顺序是先读入文件,读入的同时进行统计字符数和行数,然后将符合是单词的字符串及出现次数统计在一个hashmap里面,这些功能我都封装到一个函数叫calculate()里面。接着是进行遍历hasnmap的单词数目统计(具体函数是calculateWordsNumber()),最后是将统计结果整合成result字符串并输出到指定文件(具体函数resultShow())。
解题思路描述:
--首先用scanner套接file读取指定文档里面的字符串,并进行字符串和行数的统计。建立一个hashmap表来记录各个单词出现的频率,每一行从文档中读入字符串后先进行小写化,然后去掉空格,用某一特殊字符替代非单词的字符串后,跟hashmap中的表进行比较,没有的话就以该字符串为key,1为value插入,有的话就再原来的基础上加一。最后将得到的hashmap表中的空字符和特殊字符去掉后,先进行排序。排序用的是转化为List,重写List中的sort方法进行排序的,得到结果后输出前十个出现频率最高的单词。
重要代码:
public void mapValueSort(HashMap<String, Integer> map) { //将hashMap转化为list,使用其封装的sort函数进行排序
list = new ArrayList<Map.Entry<String, Integer>>(map.entrySet());
list.sort(new Comparator<Map.Entry<String, Integer>>(){
public int compare(Map.Entry<String, Integer> o1,Map.Entry<String, Integer> o2){ //重写compare函数,复杂度为nlog2(n),先按照value从大到小,
if (o1.getValue()<o2.getValue()) //value相等的情况下,再按照key从小到大。
return 1;
else if (o1.getValue()>o2.getValue())
return -1;
else {
return o1.getKey().compareTo(o2.getKey());
}
}
});
}
--上述代码传入的参数是包含单词以单词为key,单词出现次数为value的hashmap,然后将hashmap里面的内容存在新建的ArrayList里面,用list自带的sort函数进行排序。依据题意,先按照出现的次数从高到低排,再根据出现次数相同的情况下按照字符串的大小排序。
public void calculate() throws FileNotFoundException //进行文章统计计算,得出单词统计的hashMap,并进行排序
{
File file=new File(inputTxt);
if(!file.exists())
{
System.out.println("文件不存在");
return;
}
Scanner scanner=new Scanner(file);
hashMap=new HashMap<String, Integer>();
while(scanner.hasNextLine())
{
String line=scanner.nextLine();
if (!line.matches("\\s*"))
wordlines++;
characters += line.length();
characters ++; //多加换行符一个字符
anticle += line;
//\w+ : 匹配所有的单词
//\W+ : 匹配所有非单词
String[] lineWords=line.split("\\W+"); //用非单词符来做分割,网上找的知识点
Set<String> wordSet=hashMap.keySet();
for (int i=0;i<lineWords.length;i++) { //将不是英文的字符串替换成特定字符串,并将所以字段转化为小写
lineWords[i] = lineWords[i].toLowerCase();
if (isWord(lineWords[i])==-1)
lineWords[i] = "221801106";
}
for(int i=0;i<lineWords.length;i++){
if(wordSet.contains(lineWords[i])){ //如果已经有这个单词了
Integer number=hashMap.get(lineWords[i]);
number++;
hashMap.put(lineWords[i], number);
}
else{ //如果没有包括这个单词
hashMap.put(lineWords[i], 1);
}
}
}
hashMap.remove(""); //将字段里面的空字符串去掉
hashMap.remove("221801106"); //将不是单词的字符段去掉
mapValueSort(hashMap);
scanner.close();
}
--上述的代码先打开文件流,然后用套接流一行一行读入字符串。每一行读入的字符串都先进行字符串长度统计和判断是否为非空行,以进行字符数和行数统计。然后分割字符串,将不是单词的字符串设置为特殊字符串后面删掉(也可以加判断)并且全部小写化,最后将结果添加到hashmap里面,先判断是否存在相关key,有的话就加一,没有的话就加入新的enrty,设置key为未出现的单词,value为1.
public void resultShow() { //将结果显示
result += "characters:"+characters;
result += "\nwords:"+wordnumbers;
result += "\nlines:"+wordlines;
int i=1;
for (Map.Entry<String, Integer> word : list) {
// result += "\nword"+i+":"+word.getKey()+"("+word.getValue()+")";
result += "\nword"+i+":"+word.getKey();
if (++i>10)
break;
}
File file = new File(outputTxt);
if (!file.exists()) {
System.out.println("没有找到相关文件");
return ;
}
try {
PrintWriter pw = new PrintWriter(file);
pw.print(result);
System.out.println(result);
pw.close();
}
catch (FileNotFoundException a) {
System.out.println("没有找到统计结果的输出函数");
}
finally {
}
// System.out.println("运行结束");
}
--上述代码首先输出的是需要统计的字符数,单词数和行数。然后遍历经过排序了的,包含单词及其出现次数的list,将前10的结果输出,所有要输出的内容存放在result字符串中,然后通过输出流写到指定文件上。
代码规范制定链接:
https://github.com/Hector2333/PersonalProject-Java/blob/main/221801106/codestyle.md
性能改进:
可以选择正则表达式来减少代码量,排序算法用的是里面的sort函数,复杂度n*log2(n),感觉应该可以再减少点。流的读入读出没有用最原始的fileWriter,fileReader,用的套接流。
单元测试:
@Test
void testIsWord() {
assertEquals(lib.isWord("1234"),-1);
assertEquals(lib.isWord("ttt43"),-1);
assertEquals(lib.isWord("tttt3"),1);
assertEquals(lib.isWord("aaaaaa3"),1);
assertEquals(lib.isWord("t43te"),-1);
}
void testCalculate() throws FileNotFoundException{
lib.calculate();
assertEquals(lib.characters,490);
// assertEquals(lib.wordnumbers,50);
assertEquals(lib.wordlines,7);
Lib temp = new Lib("C:\\Users\\29847\\Desktop\\测试1.txt","");
assertEquals(temp.wordlines,2);
assertEquals(temp.characters,30);
assertEquals(temp.wordnumbers,6);
}
--用来测试函数的部分代码
--第一次使用单元测试,用的挺生疏的,主要是感觉自己的函数连在一起了,而且程序本身挺小的,没有分成太多函数。以后做比较大的项目感觉会挺好的,不过如果用单元测试生疏的话有时候比直接结果输出或者断点慢,以后会慢慢熟悉单元测试。
进行了几次不同的测试:
input1:
output1:


input2:
output2:

input3:
output3:


异常处理说明:
try {
PrintWriter pw = new PrintWriter(file);
pw.print(result);
System.out.println(result);
pw.close();
}
catch (FileNotFoundException a) {
System.out.println("没有找到统计结果的输出函数");
}
finally {
}
// System.out.println("运行结束");
--主要的异常是没有找到input.txt或者output.txt,这里给的是输出时的异常,输入用的scanner,输出用的printWriter。
心路历程与收获:
--很久没有打过java的代码了,打了一次就又记起来了。之前hashmap啥的再用了一下清楚了,更熟悉博客的编写,然后第一次学习了github的使用,在学git的使用碰到了连不上网络厂库的问题,卡住了一下,单元测试以前不懂,现在经过学习也算略知一二。
--跟优秀的博客比起来单元测试还有代码那部分比较简陋,因为我在这两方面花的心思比较少,感觉能运行大概符合我的要求就可以了,这点真的挺不对的。之前有一些不懂的地方去看了一下别人优秀的博客一下子就懂了,普通的博客看完没有什么收获。一方面自己真的比较不注重结果的表达,另一方面自己能力确实欠缺。所以还得继续努力

