keras学习(一)
最近在学习keras,主要还是跟着网上大佬们的教程走的,代码也是跟着写的,没啥自己创新,算是记录一下吧!第一次学习就是进行一个简单的拟合,拟合一个一元一次方程吧(数学语言来说):y = 0.5x + 2。先放上代码吧!
import keras
import numpy as np
import matplotlib.pyplot as plt
from keras.models import Sequential #模型这个用的多
from keras.layers import Dense #用到什么层,就像这个形式导入
x = np.linspace(-1, 1, 200)
np.random.shuffle(x) #打乱数组,指令操作,不是赋值操作,如果在前面加'x='会出错
ai = np.random.normal(0, 0.05, (200,)) #这种是生成一些正态分布的数据,均值是0,标准差是0.05
bi = np.linspace(-0.05, 0.05, 200) #这个就是单纯的随机生成,
y = x*0.5 + 2 + ai #根据函数关系式生成y
plt.scatter(x, y) #scatter显示散点图,显示x与y的关系散点图
plt.show()
#划分训练集和验证集
x_train, y_train = x[:160], y[:160] #前160训练
x_test, y_test = x[160:], y[160:] #后160测试
#建立模型
model = Sequential() #建立模型第一步就是这一个语句,建立一个顺序模型
model.add(Dense(units=1, input_dim=1)) #然后慢慢一步一步的往模型里面加层,这里直接全连接层,输入尺寸为1,输
#出也是1,一个x对应一个y
model.compile(loss='mse',optimizer='sgd') #上面是模型的结构搭建好了,接下来是编译模型,使得他能够使用
#开始训练
print("#train--------------------------")
for step in range(601): #训练601步,如果结果不是很接近0.5和2,可以自己设置多训练一会
cost = model.train_on_batch(x_train, y_train) #这个按照官方文档说的就是每次去batch个数据进行训练,这里
#应该是每次选一个吧,然后返回一个测试误差的值(或者一些
#误差值的列表,这里没有多个评价指标,所以就一个了)
if step%100==0:
print("cost%f" % cost) #每一百步输出一下cost,可以自己设置,输出500个都没问题
print("#test---------------------------")
cost = model.evaluate(x_test, y_test, batch_size=40) #这个就是直接取40个测试数据进行预测,我的理解就是通过
#模型将输入的x_test计算出y值,再跟y_test比较,得出误差值
print("test cost:%f" % cost)
w,b = model.get_weights() #这个我也不知道该咋说,就是获得权重和偏置
print("w:%f,b:%f" % (w, b))
y_pred = model.predict(x_test) #显而易见就是根据x_test获得预测值
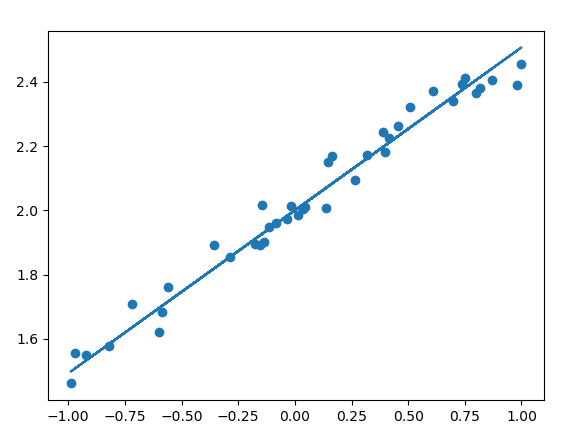
plt.scatter(x_test, y_test) #最后将x_test,y_test的散点图显示和预测出y_pred绘制的直线进行对比
# plt.show()
plt.plot(x_test, y_pred)
plt.show()
代码就是上面的了,我也是萌新,大佬看了不要喷,有写错的地方希望指正。整体思路就是先得到训练数据和测试数据,应该也可以导入,但是通过numpy获得比较快捷。然后就是搭建模型,编译模型,再开始训练,测试,最后看一些结果。为什么要在y=0.5*x+2后面再加个ai呢(看代码),如果不加,那所有的数据点都在一条直线上了,就没有训练的目的了,直接根据两个点就算出来了。然后处理ai是获得正态分布的数值,不用bi(代码),因为bi差不多是均匀分布的,虽然是随机生成的,所以整个数据可以类似看成是一个矩形了,下图红色框(我已经尽量把线画直了:):
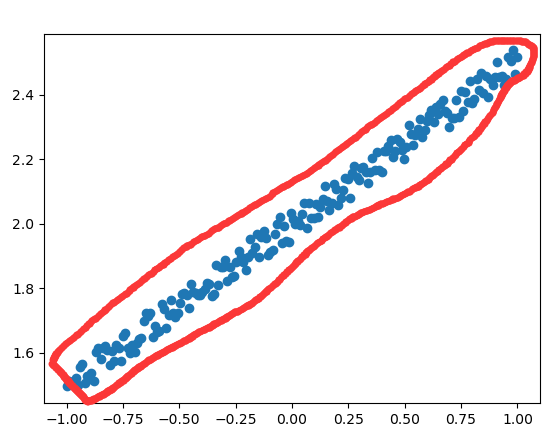
然后训练可能就会在这个矩形里面进行,而采用正态分布就会比这个效果好。最后得到的结果w=0.507225,b=1.999865,图形如下:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号