


LFM 隐语义模型
隐语义模型:
物品 表示为长度为k的向量q(每个分量都表示 物品具有某个特征的程度)
用户兴趣 表示为长度为k的向量p(每个分量都表示 用户对某个特征的喜好程度)
用户u对物品i的兴趣可以表示为
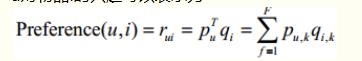
其损失函数定义为-
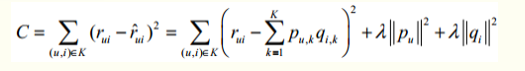
使用随机梯度下降,获得参数p,q
负样本生成:
对于只有正反馈信息(用户收藏了,关注了xxx)的数据集,需要生成负样本,原则如下
1.生成的负样本要和正样本数量相当
2.物品越热门(用户没有收藏该物品),越有可能是负样本
实现:
# coding=gbk ''' 实现隐语义模型,对隐式数据进行推荐 1.对正样本生成负样本 -负样本数量相当于正样本 -物品越热门,越有可能成为负样本 2.使用随机梯度下降法,更新参数 ''' import numpy as np import pandas as pd import random from sklearn import cross_validation class LFM(): ''' 初始化隐语义模型 参数: *F 隐特征的个数 *N 迭代次数 *data 训练数据,要求为pandas的dataframe *alpha 随机梯度下降的学习速率 *r 正则化参数 *ratio 负样本/正样本比例 ''' def __init__(self,data,F=100,N=1000,alpha=0.02,r=0.01,ratio=1): self.F=F self.N=N self.alpha=alpha self.r=r self.data=data self.ratio=ratio ''' 初始化物品池,物品池中物品出现的次数与其流行度成正比 ''' def InitItemPool(self): self.itemPool=[] groups = self.data.groupby([1]) for item,group in groups: for i in range(group.shape[0]): self.itemPool.append(item) ''' 获取每个用户对应的商品(用户购买过的商品)列表,如 {用户1:[商品A,商品B,商品C], 用户2:[商品D,商品E,商品F]...} ''' def user_item(self,data): ui = dict() groups = data.groupby([0]) for item,group in groups: ui[item]=set(group.ix[:,1]) return ui ''' 初始化隐特征对应的参数 numpy的array存储参数,使用dict存储每个用户(物品)对应的列 ''' def initParam(self): users=set(self.data.ix[:,0]) items=set(self.data.ix[:,1]) self.Pdict=dict() self.Qdict=dict() for user in users: self.Pdict[user]=len(self.Pdict) for item in items: self.Qdict[item]=len(self.Qdict) self.P=np.random.rand(self.F,len(users))/10 self.Q=np.random.rand(self.F,len(items))/10 ''' 使用随机梯度下降法,更新参数 ''' def stochasticGradientDecent(self): alpha=self.alpha for i in range(self.N): for user,items in self.ui.items(): ret=self.RandSelectNegativeSamples(items) for item,rui in ret.items(): p=self.P[:,self.Pdict[user]] q=self.Q[:,self.Qdict[item]] eui=rui-sum(p*q) tmp=p+alpha*(eui*q-self.r*p) self.Q[:,self.Qdict[item]]+=alpha*(eui*p-self.r*q) self.P[:,self.Pdict[user]]=tmp alpha*=0.9 print i def Train(self): self.InitItemPool() self.ui = self.user_item(self.data) self.initParam() self.stochasticGradientDecent() def Recommend(self,user,k): items=self.ui[user] p=self.P[:,self.Pdict[user]] rank = dict() for item,id in self.Qdict.items(): if item in items: continue q=self.Q[:,id]; rank[item]=sum(p*q) return sorted(rank.items(),lambda x,y:cmp(x[1],y[1]),reverse=True)[0:k-1]; ''' 生成负样本 ''' def RandSelectNegativeSamples(self,items): ret=dict() for item in items: #所有正样本评分为1 ret[item]=1 #负样本个数,四舍五入 negtiveNum = int(round(len(items)*self.ratio)) N = 0 while N<negtiveNum: item = self.itemPool[random.randint(0, len(self.itemPool) - 1)] if item in items: #如果在用户已经喜欢的物品列表中,继续选 continue N+=1 #负样本评分为0 ret[item]=0 return ret data=pd.read_csv('../data/ratings.dat',sep='::',nrows=10000,header=None) data=data.ix[:,0:1] train,test=cross_validation.train_test_split(data,test_size=0.2) train = pd.DataFrame(train) test = pd.DataFrame(test) lfm = LFM(data=train) lfm.Train() lfm.Recommend(1, 10)
