
关于tensorflow里多维数组(主要是四维)的组织形式之前一直没弄懂,最近遇到相关问题,算是搞清楚了一些东西,特别记下来,免得自己又遗忘了。
三维形式能很简单的脑补出来三维的形状,不再赘述。
之前一直纠结四维的时候数据是怎样填充的。特别是遇到深度学习的时候输入都是[batch,height,width,channel],这种四维的张量的时候,是怎样个数据的形状。
先看代码:
prediction2 = tf.constant([1,2,3,4,5,6,7,8,9,13,14,14,15,1,6,34,23,7],shape=[2,1,3,3])
生成一个shape为 [2,1,3,3]的tensor,具体生成的时候按照一个维度一个维度填充的,先填充最“里面”的维度,这里指维度3,然后往外依次填充。因此可以将[1,1,3,3]看成是这样形状:

而[2,1,3,3]则是两个这样的立方体组合而成。生成这样的一个tensor的时候依次填充[0][0][0][0], [0][0][0][1], [0][0][0][2]......
依次当求这个tensor在相应维度下的最大值坐标就很好理解了,如这句代码:
result = tf.argmax(prediction2,3)
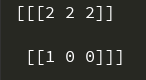
将返回在Z轴上最大值的坐标,因此立方体第一列即[0][0][0][0], [0][0][0][1], [0][0][0][2],依次为1,2,3, 最大为2,返回维度为2;同理可推出,函数返回值为:
[[2,2,2],
[1,0,0]]
实际运行结果也相同:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号