
mycat学习-3 分库分表
1.切分简介
分库分表是对数据的拆分,有水平拆分和垂直拆分两种。
水平切分是根据表中数据的逻辑关系,将同一个表中的数据按照某种条件拆分到多台数据库服务器上面,为横向切分;
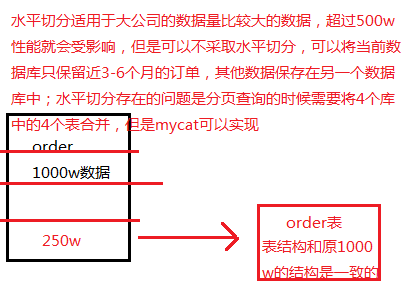
垂直切分是一种按照不同的表切分到不同的数据库上,垂直切分一般是按照业务维度进行数据库表的切分;把相同类型的表放在一个数据库,另一些表放在另一个数据库;也就是不同的维度不同的表,把表分散到各个数据库中;
垂直拆分用的比较多;

垂直切分的方法中有一种小的形式是 例如一个表需要有80个字段 基于字段太多可以将本表拆分为两个表 base表是20个字段 ext扩展表是60字段 两个表通过id相关联;
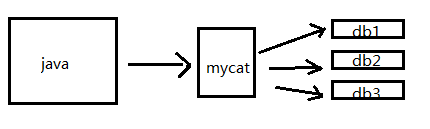
mycat中间代理层规避了多数据源的问题 对应用完全透明,对于切分后存在的问题也做了解决方案;
2.mycat实现水平切分配置
server.xml 和schema.xml和rule.xml,其中rule.xml未曾变动 server.xml参照上次读写分离的配置,修改的是schema.xml文件:
server.xml文件中配置如下内容:将mycatdb2修改为mycatdb3

只是分库分表的配置:
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<!--
schema用户配置逻辑数据库 实现分库分表,schema下配置table
需求: order表数据量太大,1000w条数据,需要水平切分,原来表在test01数据库
现在切到test01、test02、test03这3个数据库
dataNode属性配置的意思是这个order表在3个数据库上
rule 是切分规则一般用 mod-long是取模的配置 在rule.xml文件中指定
<tableRule name="mod-long">
<rule>
<columns>id</columns>
<algorithm>mod-long</algorithm> 有对应的算法
</rule>
</tableRule>
对应的算法如下
<function name="mod-long" class="io.mycat.route.function.PartitionByMod">
<property name="count">3</property> 切分到几个库就写几
</function>
主键取模的规则 例如id=1 数据库有3个 那么1%3=1到test02数据库 id=2 2%3=3到test03数据库 id=3 3%3=0到test01数据库
最终的配置如下:
<schema name="mycatdb3" checkSQLschema="false" sqlMaxLimit="100" >
<table name="order" primaryKey="id" dataNode="dn1,dn2,dn3" rule="mod-long"/>
</schema>
<!--
配置datanode,datanode定义了mycat中的数据节点<定义真实的物理数据库>,也就是我们通常说的数据分片,一个datanode
标签就是一个独立的数据分片,通俗理解,一个分片就是一个物理数据库database就是
实际的数据库名称;
<dataNode name="dn1" dataHost="localhost1" database="test01" />
配置说明:
name:定义数据节点的名称,这个名称需要是唯一的,这个名称在schema里面会使用到;
dataHost:用于定义该分片属于哪个数据库实例的,属性值是引用dataHost标签上定义的name属性
database:用于对应真实的数据库名,必须是真实存在的;
最终配置如下:
-->
<dataNode name="dn1" dataHost="localhost" database="test01"></dataNode>
<dataNode name="dn2" dataHost="localhost" database="test02"></dataNode>
<dataNode name="dn3" dataHost="localhost" database="test03"></dataNode>
<!--
配置dataHost 定义具体的数据库实例、读写分离配置和心跳语句
<dataHost name="localhost1" 名称上面使用
maxCon="1000" 最大连接数
minCon="1"
balance="1" 负载均衡(改成1代表开启读写分离模式)目前的取值有4种:
0:不开启读写分离机制,所有读操作都发送到当前可用的writeHost上
1:全部的readHost与stand by writeHost<既是主又是从以下是3307和3308>参与select语句的负载均衡,简单的说就是当双主双从模式(M1->S1,M2->S2,并且M1与M2互为主备)正常情况下,当M1是写的时候,M2,S1,S2都参与
2:所有读操作都随机的在writeHost、readHost上分发
3:所有读请求随机的分发到writeHost对应的readHost执行,writeHost不负担读压力
推荐balance设置为1
dbType="mysql" 数据库类型
dbDriver="native" 数据库驱动 native代表本地驱动
switchType="1" 故障切换
-1表示不自动切换
1默认值 自动切换 心跳语句为 select user() 使用的比较多
2基于mysql主从同步的状态决定是否切换 心跳语句为 show slave status
3基于mysql galary cluster模式的切换机制(适合集群) 心跳语句 show status like 'wsrep%'
通常使用1自动切换,因为双主双从的模式2 3 比较复杂不适用
slaveThreshold="100"> 读写分离从服务器的最大个数
<heartbeat>select user()</heartbeat>心跳语句 mycat每隔一段时间会给mysql发送一条命令 检测mysql是否有响应 是否正常
writeHost 配置写数据库(主库),有几个主库就配置几个writeHost
<writeHost host="hostM3307" url="localhost:3307" user="root" password="111111">
配置读数据库(从库)
<readHost host="hosts3308" url="localhost:3308" user="root" password="111111">
<readHost host="hosts3309" url="localhost:3309" user="root" password="111111">
</writeHost>
<writeHost host="hostM3308" url="localhost:3308" user="root" password="111111">
配置读数据库(从库)
<readHost host="hosts3307" url="localhost:3307" user="root" password="111111">
<readHost host="hosts3310" url="localhost:3310" user="root" password="111111">
</writeHost>
</dataHost>
-->
<dataHost name="localhost"
maxCon="1000"
minCon="1"
balance="1"
dbType="mysql"
dbDriver="native"
switchType="1"
slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<!--配置写数据库(主库),有几个主库就配置几个writeHost -->
<writeHost host="hostM3308" url="localhost:3308" user="root" password="">
<!--配置读数据库(从库)-->
<readHost host="hosts3309" url="localhost:3309" user="root" password=""/>
<readHost host="hosts3310" url="localhost:3310" user="root" password=""/>
</writeHost>
</dataHost>
</mycat:schema>
------------------------------------------------------------------------------------------------------------------------------------------
分库分表+读写分离
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<!--
schema用户配置逻辑数据库 实现分库分表,schema下配置table
需求: order表数据量太大,1000w条数据,需要水平切分,原来表在test01数据库
现在切到test01、test02、test03这3个数据库
dataNode属性配置的意思是这个order表在3个数据库上
rule 是切分规则一般用 mod-long是取模的配置 在rule.xml文件中指定
<tableRule name="mod-long">
<rule>
<columns>id</columns>
<algorithm>mod-long</algorithm> 有对应的算法
</rule>
</tableRule>
对应的算法如下
<function name="mod-long" class="io.mycat.route.function.PartitionByMod">
<property name="count">3</property> 切分到几个库就写几
</function>
主键取模的规则 例如id=1 数据库有3个 那么1%3=1到test02数据库 id=2 2%3=3到test03数据库 id=3 3%3=0到test01数据库
最终的配置如下:
<schema name="mycatdb3" checkSQLschema="false" sqlMaxLimit="100" >
<table name="order" primaryKey="id" dataNode="dn1,dn2,dn3" rule="mod-long"/>
</schema>
<!--
配置datanode,datanode定义了mycat中的数据节点<定义真实的物理数据库>,也就是我们通常说的数据分片,一个datanode
标签就是一个独立的数据分片,通俗理解,一个分片就是一个物理数据库database就是
实际的数据库名称;
<dataNode name="dn1" dataHost="localhost1" database="test01" />
配置说明:
name:定义数据节点的名称,这个名称需要是唯一的,这个名称在schema里面会使用到;
dataHost:用于定义该分片属于哪个数据库实例的,属性值是引用dataHost标签上定义的name属性
database:用于对应真实的数据库名,必须是真实存在的;
最终配置如下:
如果不想在分库分表的基础上不实现读写分离
3308建立数据库test01
-->
<dataNode name="dn1" dataHost="localhost1" database="test01"></dataNode>
<dataNode name="dn2" dataHost="localhost2" database="test02"></dataNode>
<dataNode name="dn3" dataHost="localhost3" database="test03"></dataNode>
<!--
配置dataHost 定义具体的数据库实例、读写分离配置和心跳语句
<dataHost name="localhost1" 名称上面使用
maxCon="1000" 最大连接数
minCon="1"
balance="1" 负载均衡(改成1代表开启读写分离模式)目前的取值有4种:
0:不开启读写分离机制,所有读操作都发送到当前可用的writeHost上
1:全部的readHost与stand by writeHost<既是主又是从以下是3307和3308>参与select语句的负载均衡,简单的说就是当双主双从模式(M1->S1,M2->S2,并且M1与M2互为主备)正常情况下,当M1是写的时候,M2,S1,S2都参与
2:所有读操作都随机的在writeHost、readHost上分发
3:所有读请求随机的分发到writeHost对应的readHost执行,writeHost不负担读压力
推荐balance设置为1
dbType="mysql" 数据库类型
dbDriver="native" 数据库驱动 native代表本地驱动
switchType="1" 故障切换
-1表示不自动切换
1默认值 自动切换 心跳语句为 select user() 使用的比较多
2基于mysql主从同步的状态决定是否切换 心跳语句为 show slave status
3基于mysql galary cluster模式的切换机制(适合集群) 心跳语句 show status like 'wsrep%'
通常使用1自动切换,因为双主双从的模式2 3 比较复杂不适用
slaveThreshold="100"> 读写分离从服务器的最大个数
<heartbeat>select user()</heartbeat>心跳语句 mycat每隔一段时间会给mysql发送一条命令 检测mysql是否有响应 是否正常
writeHost 配置写数据库(主库),有几个主库就配置几个writeHost
<writeHost host="hostM3307" url="localhost:3307" user="root" password="111111">
配置读数据库(从库)
<readHost host="hosts3308" url="localhost:3308" user="root" password="111111">
<readHost host="hosts3309" url="localhost:3309" user="root" password="111111">
</writeHost>
<writeHost host="hostM3308" url="localhost:3308" user="root" password="111111">
配置读数据库(从库)
<readHost host="hosts3307" url="localhost:3307" user="root" password="111111">
<readHost host="hosts3310" url="localhost:3310" user="root" password="111111">
</writeHost>
</dataHost>
-->
<dataHost name="localhost1"
maxCon="1000"
minCon="1"
balance="1"
dbType="mysql"
dbDriver="native"
switchType="1"
slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<!--配置写数据库(主库),有几个主库就配置几个writeHost -->
<writeHost host="hostM3308" url="localhost:3308" user="root" password="">
</writeHost>
</dataHost>
<dataHost name="localhost2"
maxCon="1000"
minCon="1"
balance="1"
dbType="mysql"
dbDriver="native"
switchType="1"
slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<!--配置写数据库(主库),有几个主库就配置几个writeHost -->
<writeHost host="hostM3309" url="localhost:3309" user="root" password="">
</writeHost>
</dataHost>
<dataHost name="localhost3"
maxCon="1000"
minCon="1"
balance="1"
dbType="mysql"
dbDriver="native"
switchType="1"
slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<!--配置写数据库(主库),有几个主库就配置几个writeHost -->
<writeHost host="hostM3310" url="localhost:3310" user="root" password="">
</writeHost>
</dataHost>
</mycat:schema>
水平切分测试验证:
3308上创建test01、test02和test03 3个数据库,据说此处3309和3310可以同步的3个数据库的,但是并不知道是否需要主从的某些同步配置,本处手工在3309和3310中创建了对应的3个数据库才启动startup_nowrap.bat成功;
<!--注:经过查询资料发现mycat并不负责mysql的主从同步问题,这是负责读写分离,所以此处如果想数据同步的话则应该在前两篇文章mysql的主从配置中的mysql的基础上做修改https://www.cnblogs.com/healthinfo/p/10375322.html-->
在test01中创建表orders必须有id字段因为是id取模规则,不用自动递增。
修改3308,3309,3310为mysql的主从同步配置


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理