
分库分表学习-1 分库分表策略概述
1.为什么要分库分表?
数据库分片:<redis>
用户流量和数据量比较大,两个因素迫使需要优化,
单表的数据量大,不论单表如何优化,解决大数据存储的访问性能;
分库分表解决的是两个问题:
1>超大容量问题<用户表、订单表等 io能力和单表处理能力有瓶颈>
2>性能问题<io能力、单库>
2.如何实现分库分表
1>垂直切分:
1.1>垂直分库: 订单库+用户表+活动库 业务清晰并且每个数据库都可以独立部署到服务器上
解决的是表过多的问题
1.2>垂直分表:解决单表列过多的问题
例如商品表 商品主表+扩展表+标签信息表
2>水平切分:
大数据表拆成小表;
举例:
例如一张订单表拆分成5张小的订单表,有一个拆分策略,再将表拆分到不同的库中
实际项目中拆分的选择?
根据架构不同的选择:
数据库存储层的性能瓶颈:
优化的依据:
3.拆分策略:
1>垂直拆分: 两个前提:技术+业务(er分片)
2>水平拆分:一致性hash<例如订单表的某个字段的维度拆分10个,例如根据userId拆分取模 userId%10>
问题:
拆分字段的选择非常重要,影响到后续
3>范围切分:例如按照id在某个维度的拆分<id 0~100000> 好处:数据连续,但是hash是随机的
4>日期切分:
拆分带来的问题:
1>跨库join的问题 select a.x,b.y from a join b on a.id=b.id
A服务 B服务 <A 查id 去B中查 然后两个再join 关联键是主键>
1>设计的时候考虑到应用层的join问题
2>在服务层去做调用
A服务里查询到一个list
for(list){bservice.select(id);} 不能这样做,因为多次rpc网络的影响很大的
改成bservice.select(list);
3>全局表<解决跨库join的问题>
公共的数据,每个数据库每个应用节点都可能用到例如字典表或者常量等
a.数据变更比较少的基于全局应用的表<例如当10个节点都依赖1个表,那么10个服务里面都去写这样一个代码是没有必要的可以抽取成一个公共的服务>
b.公共服务
4>做字段冗余(空间换时间的做法)
订单表,商家id 例如订单列表中需要展示商家名称的时候,不同的库里面,可以在订单表里面做一个商家名称,如果商家名称变动的时候(变动的时候消息通知或者定时任务,任务通知,商家名称变更)
2>跨分片数据表排序分页:
订单小表123在database1,订单小表45在database2中,这种比较复杂
唯一主键问题:
用自增id做主键
uuid 比较长,性能比较低
snowflake算法< 雪花算法 >
mongDB的
zookeeper的自增id
redis的自增主键
数据库表来做<专门有个表去存储id>
分布式事务问题:
原本一个库的事务分到两个或者多个库中,保证多个库事务的强一致性
分布式事务的应用是比较少的;
产品最大的特点是用户的体验(反馈的时间3-5秒)
多表拆分之后带来的问题的解决!
分库分表最难的在于业务的复杂度
如何权衡当前公司的存储需要优化?
1.提前规划(主键问题解决、join问题)
2.当前数据单表超过1000w,每天的增长量持续上升,迫切需要优化
查询语句 索引
MySQL的优化
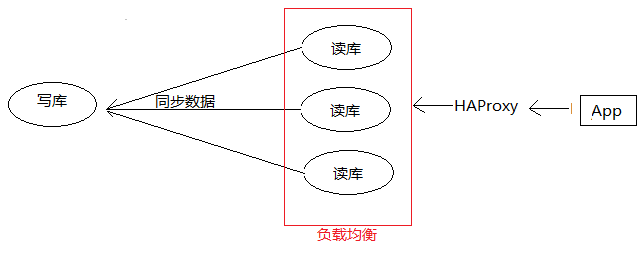
绝大部分应用是写少读多的操作,此场景是否可以做一个读写分离呢?


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理